Scikit-Learn でモデルカードを作成してクラウドにデプロイする方法
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習モデルは、多数の難しいタスクを遂行するために使用されるようになりました。大きな可能性を秘める ML モデルですが、その使用方法、構成、制限に関して疑問も寄せられています。そうした疑問に対する回答を文書化することで状況が明確になり、共通の理解を得ることができます。これらの目標を達成するために、Google はモデルカードを導入しました。
モデルカードの目的は、機械学習モデルの全体像を簡潔に提供することです。まず、モデルカードはそのモデルの機能、意図するユーザー層、その管理者について説明します。また、アーキテクチャや使用されているトレーニング データなど、モデルの構成に関する情報も提供します。さらに、生のパフォーマンス指標だけでなく、モデルの制限とリスク緩和の機会についても記載しています。調査報告書 Model Cards for Model Reporting では、モデルカードについて詳しく説明されています。
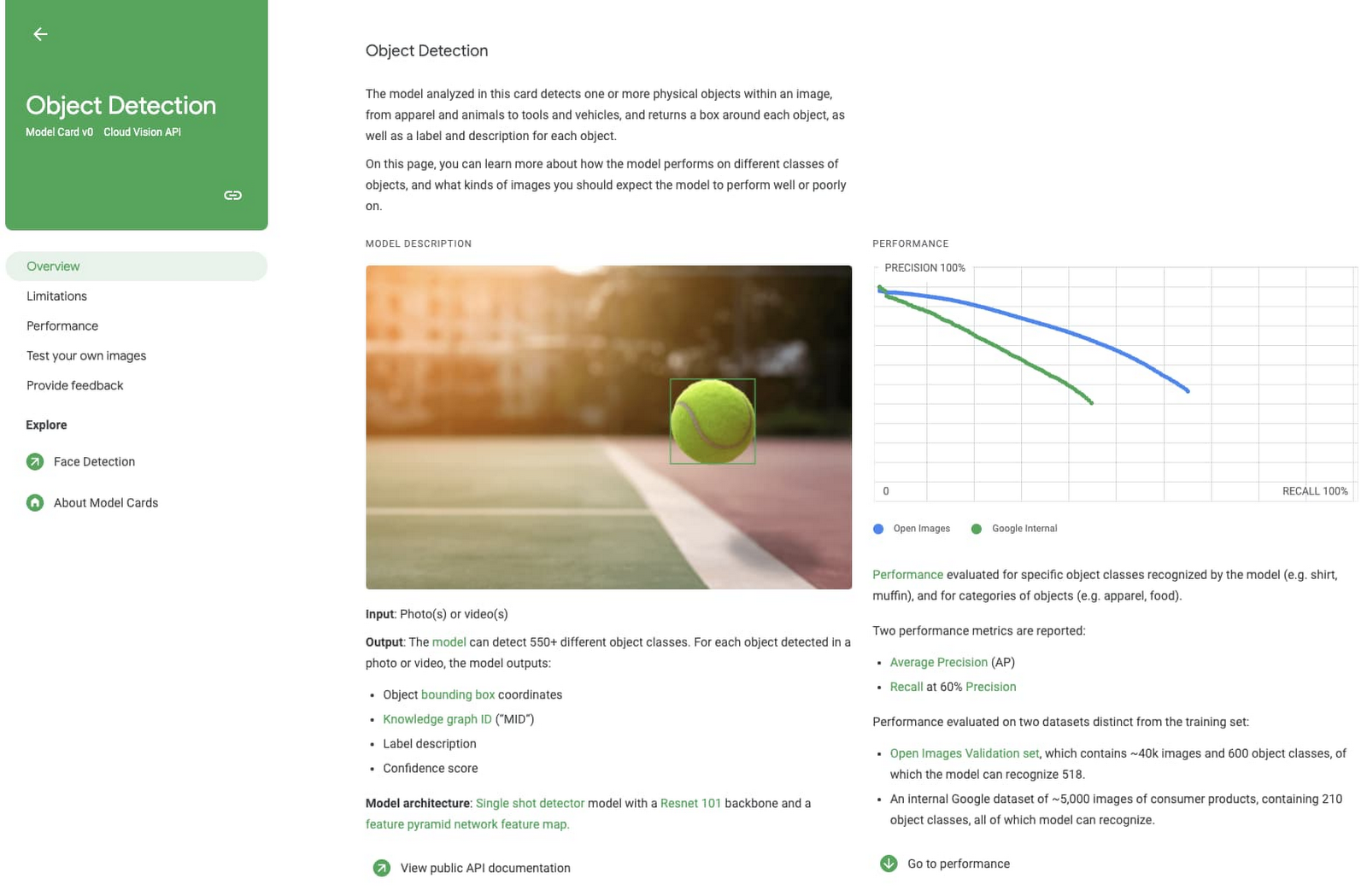
このブログ投稿では、独自のモデルカードをいかに簡単に作成できるかをご紹介します。今回は人気の高い scikit-learn フレームワークを使用しますが、ここで説明するコンセプトは TensorFlow、PyTorch、XGBoost などの他のフレームワークにも当てはまります。
Model Card Toolkit
Model Card Toolkit は、モデルカードの作成プロセスを効率化します。このツールキットは、モデルカードに情報を入力し、モデルカードをエクスポートする機能を備えています。また、TensorFlow Extended や ML Metadata から直接モデルカードのメタデータをインポートすることもできますが、その機能は必須ではありません。今回のブログ投稿ではモデルカードのフィールドに手作業で情報を入力してから、モデルカードを表示用の HTML にエクスポートします。
データセットとモデル
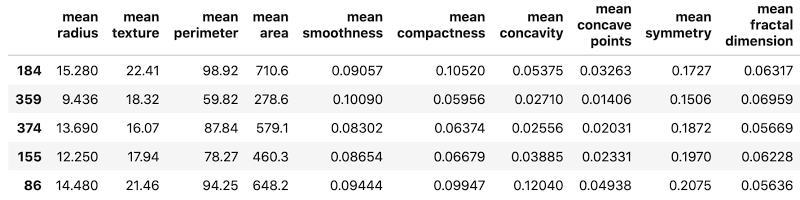
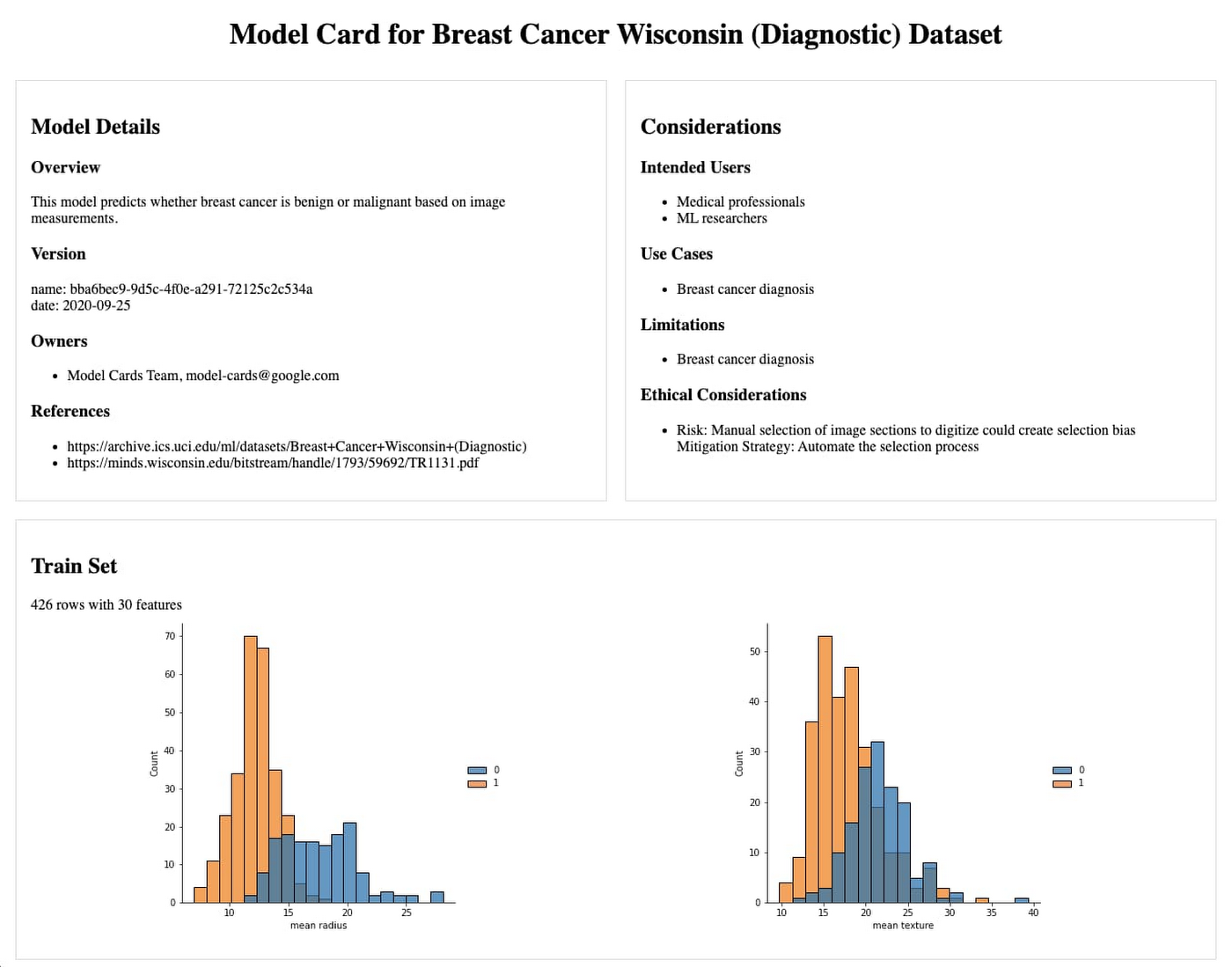
今回は Breast Cancer Wisconsin Diagnostic Dataset を使用します。このデータセットには、569 のインスタンスとデジタル化された画像から取得した測定値が含まれています。ここでデータのサンプルを見てみましょう。
scikit-learn の GradientBoostedClassifier を使用してモデルを構築してみましょう。このモデルはバイナリ分類子です。つまり、インスタンスのタイプを予測することができます。ここでは、提供されている測定値に基づいて、腫瘍が良性か悪性かを予測します。
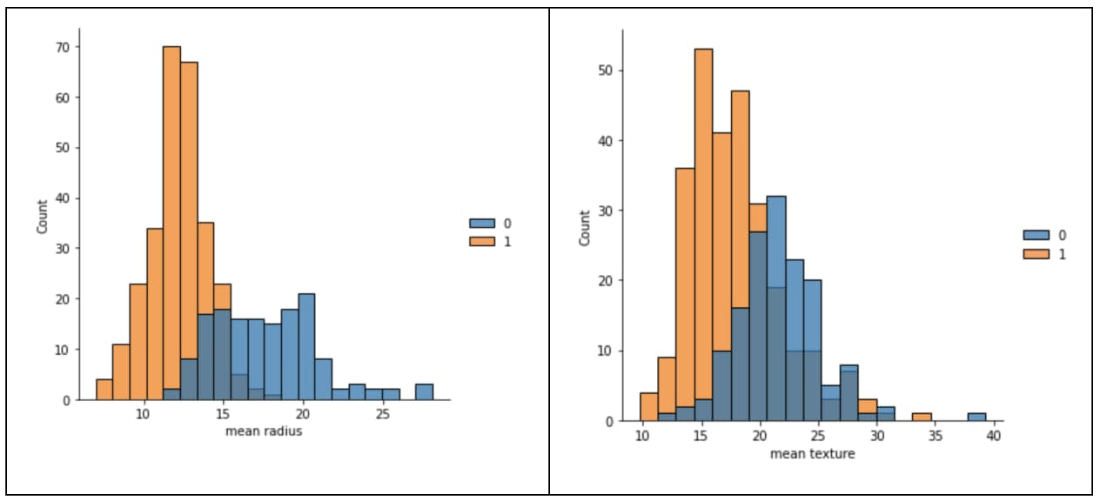
たとえば、以下の 2 つのグラフから、「平均半径(mean radius)」と「平均テクスチャ(mean texture)」の特性は診断と相関関係があることがわかります(0 は悪性、1 は良性)。このモデルは、最高の予測結果を出すように、これらの特性、特性間の関係、特性の重み付けを最適化するようにトレーニングされます。今回の記事では、モデルのアーキテクチャについては深く掘り下げません。
ノートブックの作成
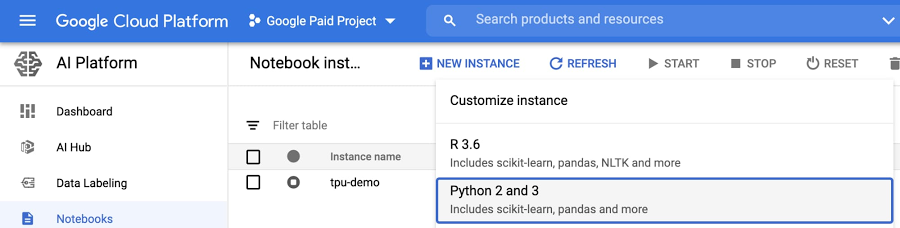
AI Platform Notebooks により、データ サイエンティストはクラウド内でモデルのプロトタイプ作成、開発、展開を行うことができます。まず、Google Cloud Console でノートブックを作成してみましょう。「Python 2 and 3」インスタンスで、すでに scikit-learn や pandas などの人気の高いフレームワークが事前インストールされた新しいインスタンスを作成できます。ノートブック サーバーがプロビジョニングされたら、まず [JupyterLab を開く] を選択します。
ここで使用するデータセットには 569 行しか含まれていないため、ノートブックのインスタンス内で迅速にモデルをトレーニングできます。より大きなデータセットに基づくモデルを構築する場合は、AI Platform Training サービスも利用して scikit-learn モデルを構築すれば、インフラストラクチャの管理は一切不要です。また、モデルをホストする準備が整うと、AI Platform Prediction サービスから scikit-learn モデルが提供され、必要に応じて REST エンドポイントおよび自動スケーリングを利用できるようになります。
サンプル ノートブックの読み込み
Model Card Toolkit の GitHub リポジトリには、サンプルとプロジェクトのソースコードが含まれています。まず、JupyterLab のメニューで [Git] > [Clone a Repository] を選択し、リポジトリのクローンを作成しましょう。
次に、リポジトリの URL(https://github.com/tensorflow/model-card-toolkit)を入力します。すると、コンテンツがお使いのノートブック環境にダウンロードされます。ディレクトリ構造: model-card-toolkit/model_card_toolkit/documentation/examples に移動し、Scikit-Learn ノートブックを開きます。
モデルカードの作成
では始めましょう。このセクションでは、モデルカードを作成するための主な手順について説明します。サンプル ノートブックを参照しながら進めることもできますが、必須ではありません。
最初の手順は Model Card Toolkit のインストールです。Python パッケージ マネージャーを使用して、環境にパッケージをインストールするだけです(pip install model-card-toolkit)。
モデルカードの作成を開始するには、モデルカードを初期化してから、Model Card Toolkit のアセットを生成する必要があります。このスキャフォールディング プロセスにより、モデルカードの JSON ファイルおよびカスタマイズ可能なモデルカード UI テンプレートとともに、アセットのディレクトリが作成されます。ML メタデータ ストアを使用している場合は、必要に応じてメタデータ ストアでツールキットを初期化し、モデルカードのプロパティとグラフに情報を自動的に入力することもできます。この記事では、その情報を手作業で入力する方法をご紹介します。
モデルカードへの情報の入力
ここから、モデルカードに多数のプロパティを追加できます。以下のように、プロパティはネスティングに対応しており、複数の値の配列など、多数のさまざまなデータタイプをプロパティに追加することができます。
参照用のモデルカード スキーマがあります。このスキーマは、モデルカードの構造と使用できるデータ型を定義しています。たとえば、前述した name プロパティを説明するスニペットは以下のとおりです。
画像は base-64 でエンコードされた文字列として提供する必要があります。サンプル ノートブックは、グラフを PNG 形式にエクスポートしてから base-64 文字列としてエンコードするコードを提供しています。
最後の手順は、モデルカードのコンテンツをスキャフォールドされた JSON ファイルに書き戻す作業です。このプロセスではまず、モデルカードに入力したプロパティを検証します。
モデルカードの生成
ここまでで、モデルカードを生成する準備が整いました。次のコード スニペットは、モデルカードを HTML にエクスポートし、ノートブック内に表示する単純なものです。
HTML ファイルは、ツールキットの初期化時に指定された出力ディレクトリ内に生成されます。デフォルトでは、アセットは一時ディレクトリ内に作成されます。また、必要に応じてモデルカードのカスタム UI テンプレートを渡すこともできます。そうする場合は、まずデフォルトのテンプレートを使用するとよいでしょう。
では、結果を見てみましょう。
次のステップ
今回の投稿では、scikit-learn を使用して独自のモデルカードを作成する方法を紹介しました。ここで説明した方法は、あらゆる機械学習フレームワークに応用できます。さらに TensorFlow Extended(TFX)を使用すると、モデルカードに情報を自動入力することもできます。
Model Card Toolkit を使用すると、モデルのプロパティを入力し、その結果を好みの HTML テンプレートにエクスポートするだけなので簡単です。サンプル ノートブックを使用して、その仕組みを確認することができます。
また、Google Cloud AI Platform を使用して、モデルの開発からトレーニング、その後の提供まで、scikit-learn モデルのライフサイクル全体を管理する方法についてもご説明しました。
このプラットフォームを使用することで、今後、ご自身のモデルの理解を深めることができるようになるでしょう。
-デベロッパー アドボカシー担当マネージャー Karl Weinmeister




