父の日に過去 30 年分の家族の動画を AI アーカイブにしてプレゼント
Google Cloud Japan Team
※この投稿は米国時間 2020 年 6 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
私の父が初めてビデオカメラを手にしたのは、今から約 30 年前、私が生まれた日のことでした。その日は偶然、父の日でもありました。「カメラに話しかけて!」これが病院のベビーベッドの上の真っ赤でぽっちゃりした赤ちゃん(私)に向けられたビデオカメラが捉えた、父の最初の言葉です。それ以降、おむつ替えの様子や癇癪を起している私の姿、そして何より思い出したくもない思春期の様子など、父はさまざまな映像を記録してきました。
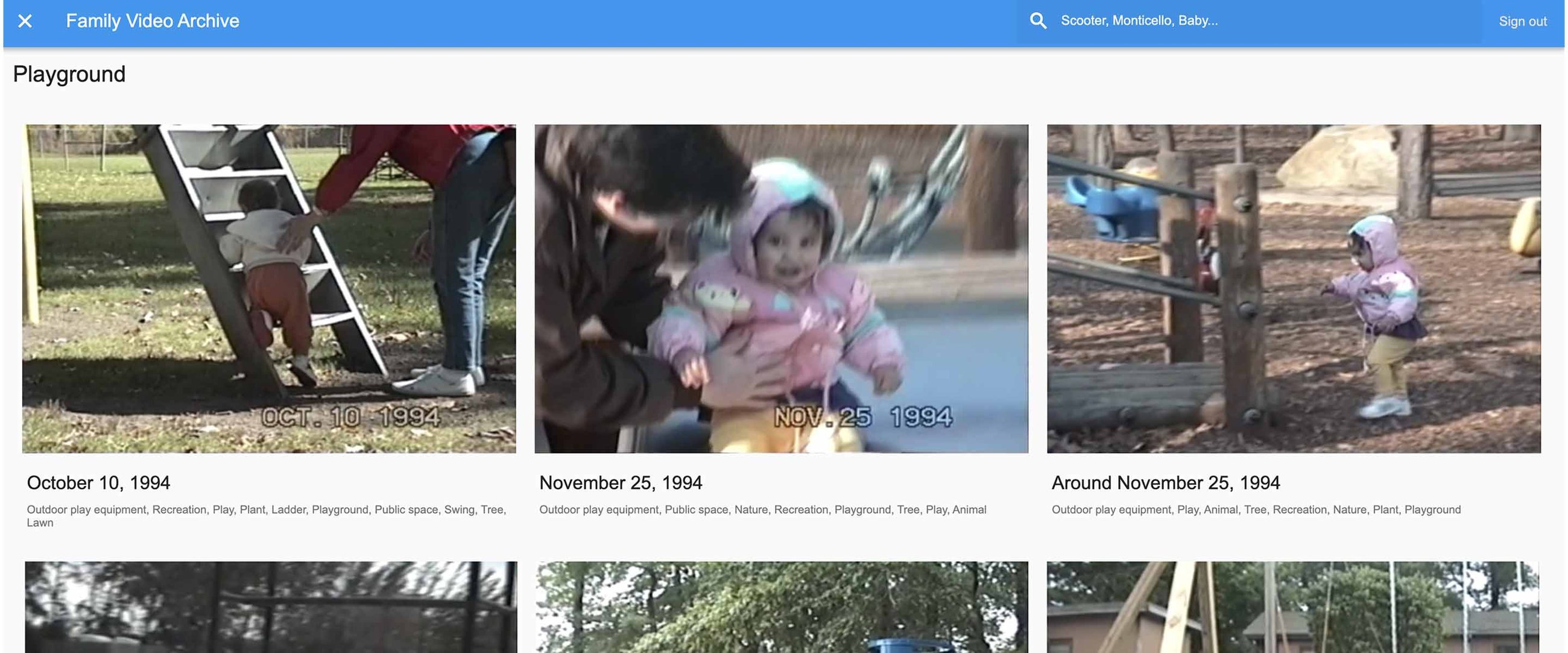
こうした恥ずかしく思える過去の映像の数々は、父が 2 年前にすべての映像を Google Drive にアップロードするまでは、ミニ DV カセットや何枚もの SD カードに散在していました。考えてみれば、こうした映像がクラウドに保存されるようになったことで、私や家族は見ようと思えばいつでも好きなときに映像を見ることができたはずでした。しかし、456 時間を超える映像をすべて視聴するには超人的な忍耐が必要だったことでしょう。家族の旧知の友人たちがクリスマス プレゼントを開ける瞬間を何度も何度も見る羽目になります。そこで今年の父の日には、AI を活用して検索できる家族動画のアーカイブを父に作ってあげることにしました。
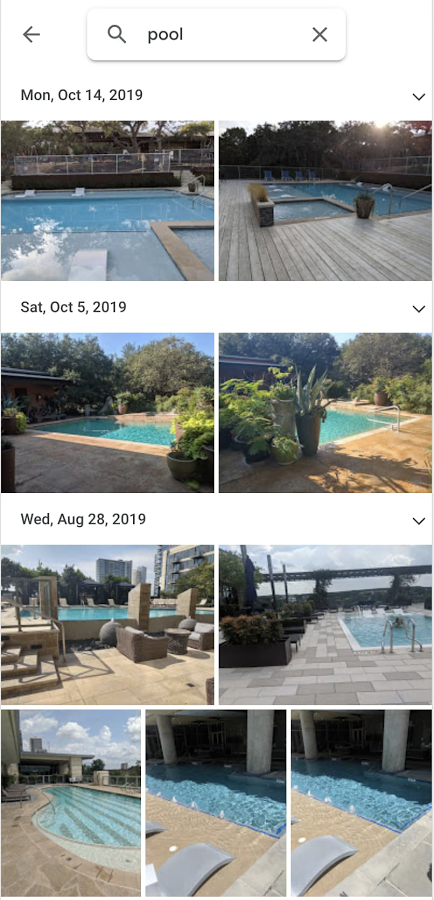
Google フォトを使ったことがあれば、画像や動画を検索したり整理したりするのに AI の力を活用したことがあるはずです。アプリでは、機械学習を使って画像に写っている人物やペットのほか、オブジェクトやテキストまで識別されます。例えば、Google フォトアプリで「プール」を検索すると、これまでに撮ったプールの写真や動画がすべて表示されます。
フォトアプリは写真や動画のインデックス作成を急ぐときには最適な方法ですが、今回私は(父のように)クリエイターとして自力でオリジナルの動画アーカイブを構築したいと考えました。非常に特別なファイル処理に対応していることはもちろん、映像の内容だけでなく、映像内の人の言葉(文字起こし)で検索できる機能を加えたいと思っていました。この機能はフォトアプリでは現在サポートされていません。こうすることで、私の家族がよく使う言葉遣い(痛がっている人に使う「skutch」)や「first word」や「first steps」、あるいは「whoops」などのフレーズを使って検索できるようになりました。また、父は指紋認証によるロック解除用の指紋登録をよしとしないほどプライバシーにうるさい人なので、家族メンバー限定の全動画データの保存場所を正確に把握し、具体的なプライバシー保護を保証できるようにしたいと考えました。こうして、私は Google Cloud 上にアーカイブを構築し、次のように出来上がりました。
検索可能でインデックスが付いた動画アーカイブは、個人的なプロジェクトとして面白いものであることはもちろん、ビジネスの世界でも有用です。この技術を利用すれば、企業は大量の動画データセットのメタデータを自動生成し、映像に字幕を付けたり翻訳したりすることも、ブランドやクリエイティブ アセットをすばやく検索することも可能になります。
それでは、AI を活用した動画アーカイブの作成方法を見てみましょう。
AI を活用した動画アーカイブの作成方法
このプロジェクトの主戦力となったのは、何と言っても Video Intelligence API でした。このツールを使うと、次のようなことができるようになります。
音声文字変換(自動字幕など)
オブジェクトの認識(飛行機、ビーチ、雪、自転車、ケーキ、ウェディングなど)
テキストの抽出(道路標識、T シャツ、バナー、ポスターなど)
ショット変更の検出
不適切なコンテンツへのフラグ追加
私の同僚の Zack Akil が、こうした機能をすべて余すところなく紹介した素晴らしいデモを作成してくれましたので、ぜひこちらからご覧ください。
動画の検索が可能に
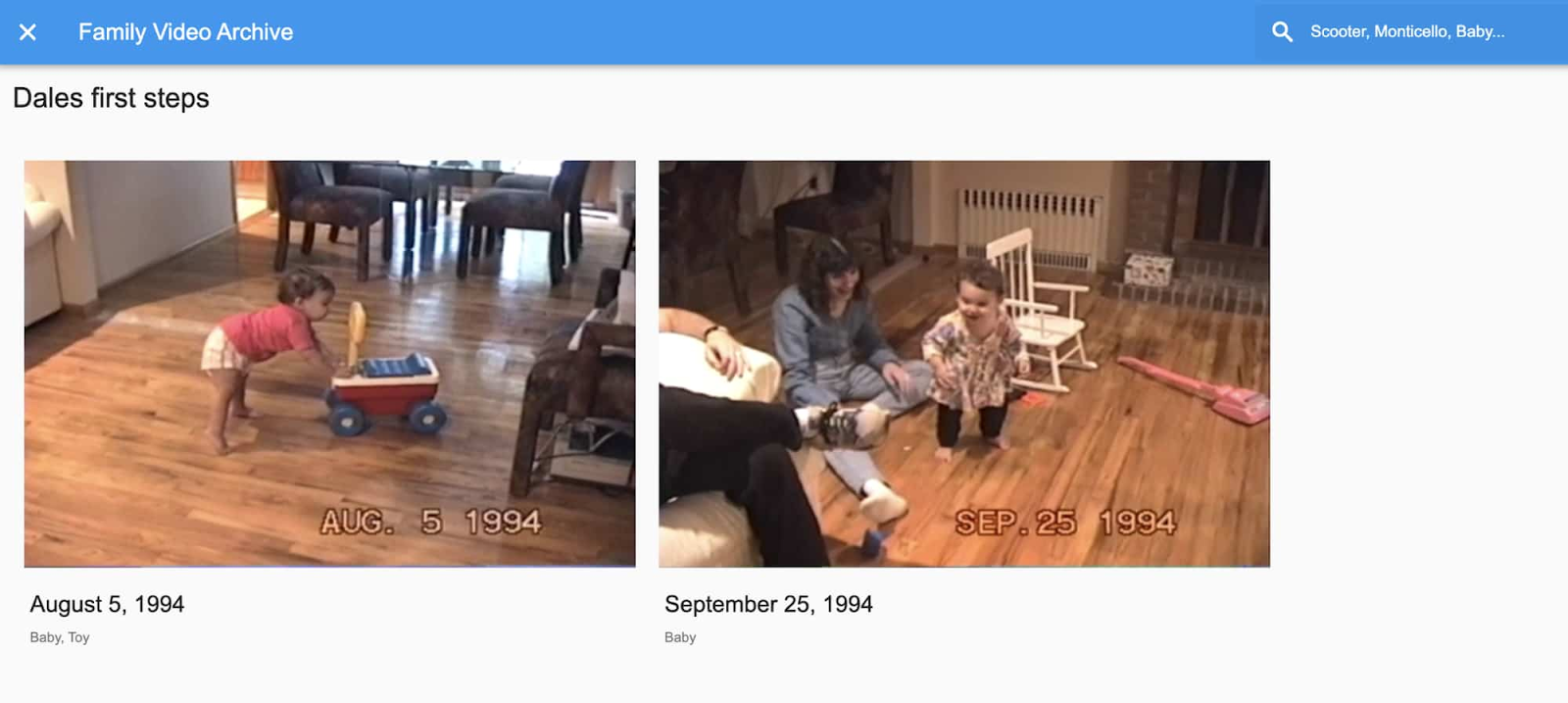
私は Video Intelligence API をいくつかの方法で使用しました。まず、これが一番大事なのですが、後で検索に使うための特徴の抽出に使用しました。例を挙げると、自動文字変換機能のおかげで次のようなかわいいやり取りを抽出して、私が初めて歩いたときの動画を見つけることができました。
「ごらん、このとき初めてデールが歩いたんだよ。カメラにも映っているよ。見てみよう。デールは何をして遊んでいるんだい?」(これは Video Intelligence API の逐語対応の音声文字変換機能で得られた会話です)。
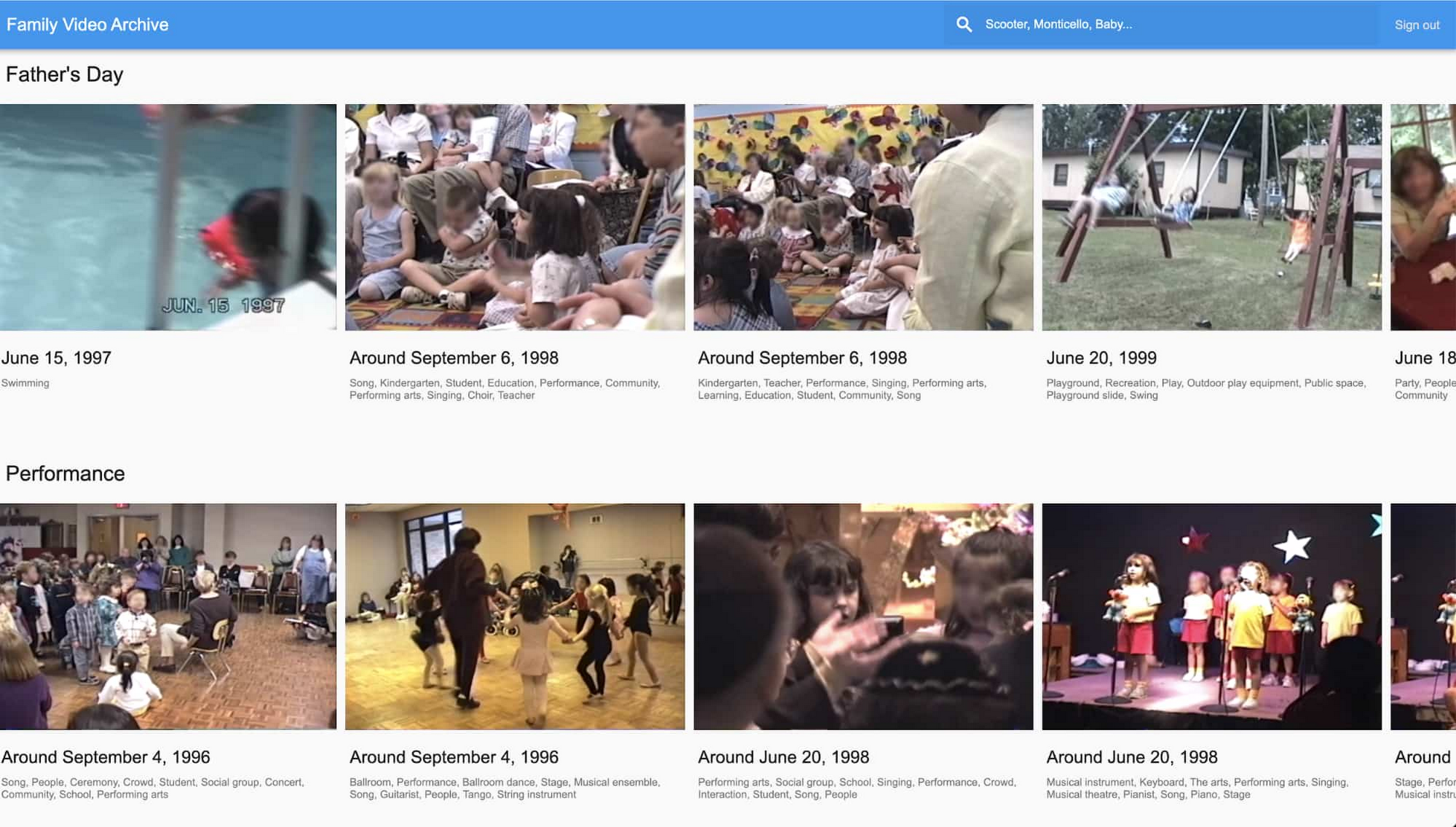
コンピュータ ビジョンを活用したオブジェクト認識機能では、「ブライダル シャワー」「ウェディング」「野球ゲーム」「ベビー」「パフォーマンス」のようなエンティティ、すなわち思い入れが強く愛着のある検索属性を認識できました。
またテキスト抽出機能を使うと、画面に写っているテキストで動画を検索できるので、標識や T シャツ、バースデー ケーキに書かれているテキストでさえも検索に利用できます。実際この機能を使って、私と兄の初めての誕生日を見つけ出しました。


長い動画を分割し、日付を抽出
このプロジェクトで最も苦労したことの一つは、何十年もの間に父が所有していたさまざまなビデオカメラで撮られた、ファイル形式がすべて異なる映像を処理することでした。父がデジタルカメラで撮影したものは、ファイル名に日付が入った短い動画クリップがほとんどでした(clip-2007-12-31 22;44;51.mp4 など)。しかし、2001 年以前は、動画をミニ DV カセットに書き込むタイプのビデオカメラを使っていました。デジタル化に際し、父はすべての動画クリップをテープごとに 1 つの大きな 2 時間のファイルにまとめました。動画クリップには、撮影時に父が画面に日付を表示するボタンを手動で押したものを除いて、撮影日に関する情報が一切入っていませんでした。

幸い、Video Intelligence API を使ってこうした問題を解決することができました。自動ショット変更検出機能では、複数の動画を合わせて 1 つの長い MOV ファイルにまとめている場合でも、1 本目の動画が終了して次の動画が開始した時点を認識できるので、長い動画クリップを短めのチャンクに自動で分割することができました。API はまた、画面に表示されている日付も抽出してくれたので、動画とタイムスタンプを照合することができました。こうした長い動画は合計 18 時間にもおよび、手作業だと 18 時間(ここから作成にかかった時間を差し引く)かかっていた時間を節約できたことになります。
巨大なデータはクラウドに保存
動画を扱ううえで課題となることの一つに、データファイルが巨大で、自分のパソコンを使ってローカルで作業をしようとすると、時間がかかり面倒だということがあります。データの取り扱いと処理は、すべてクラウドで行うことをおすすめします。そういうわけで、私は父が Google ドライブに保存していた動画クリップをすべて Cloud Storage バケットに転送することから始めました。効率よく行うためには、すべてのデータが Google のネットワーク内から離れないようにします。私はこちらのチュートリアルを参考にし、Colab ノートブックを使って転送しています。
私が目指したのは、すべての動画ファイルを Google Cloud にアップロードし、Video Intelligence API を使って分析して、結果として得たメタデータを後からアプリで照会し検索できるソースに書き込むことでした。
これには、私が機械学習パイプラインを構築するときに普段から使用しているテクニックを使いました。データを Cloud Storage バケットにアップロードし、Cloud Functions の関数を使って分析を開始して、結果をデータベース(Firestore など)に書き込むというやり方です。このプロジェクトのアーキテクチャは次のようになります。
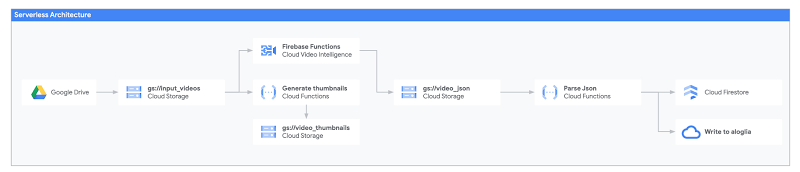
今までにこうしたツールを使ったことがない場合でも、Cloud Storage では、動画、画像、テキスト ファイル、PDF など、ありとあらゆる種類のファイルを保存できる場所が提供されます。Cloud Functions はクラウドでコードを実行する「サーバーレス」な方法です。仮想マシンやコンテナ全体を使ってコードを実行するのではなく、イベント(HTTP リクエスト、Pub/Sub イベント、またはファイルを Cloud Storage にアップロードした場合など)に応じて実行される(Python、Go、Node.js、Java の)単独の関数または関数セットをアップロードします。
ここでは、動画を Cloud Storage バケット(“gs://input_videos”)にアップロードすると、Video Intelligence API を呼び出す Cloud Functions の関数がトリガーされ、アップロードした動画が分析されます。この分析には時間がかかることもあるため、バックグラウンドで実行され、最後に 2 番目の Cloud Storage バケット(“gs://video_json”)で JSON ファイルにデータが書き込まれるようになっています。この JSON ファイルがストレージに書き込まれるとすぐに、2 番目の Cloud Functions の関数がトリガーされ、JSON データを解析してデータベース(この場合 Firestore)に書き込みます。この設計と使用するコードについてさらに詳しい内容を確認するには、こちらの投稿をご覧ください。
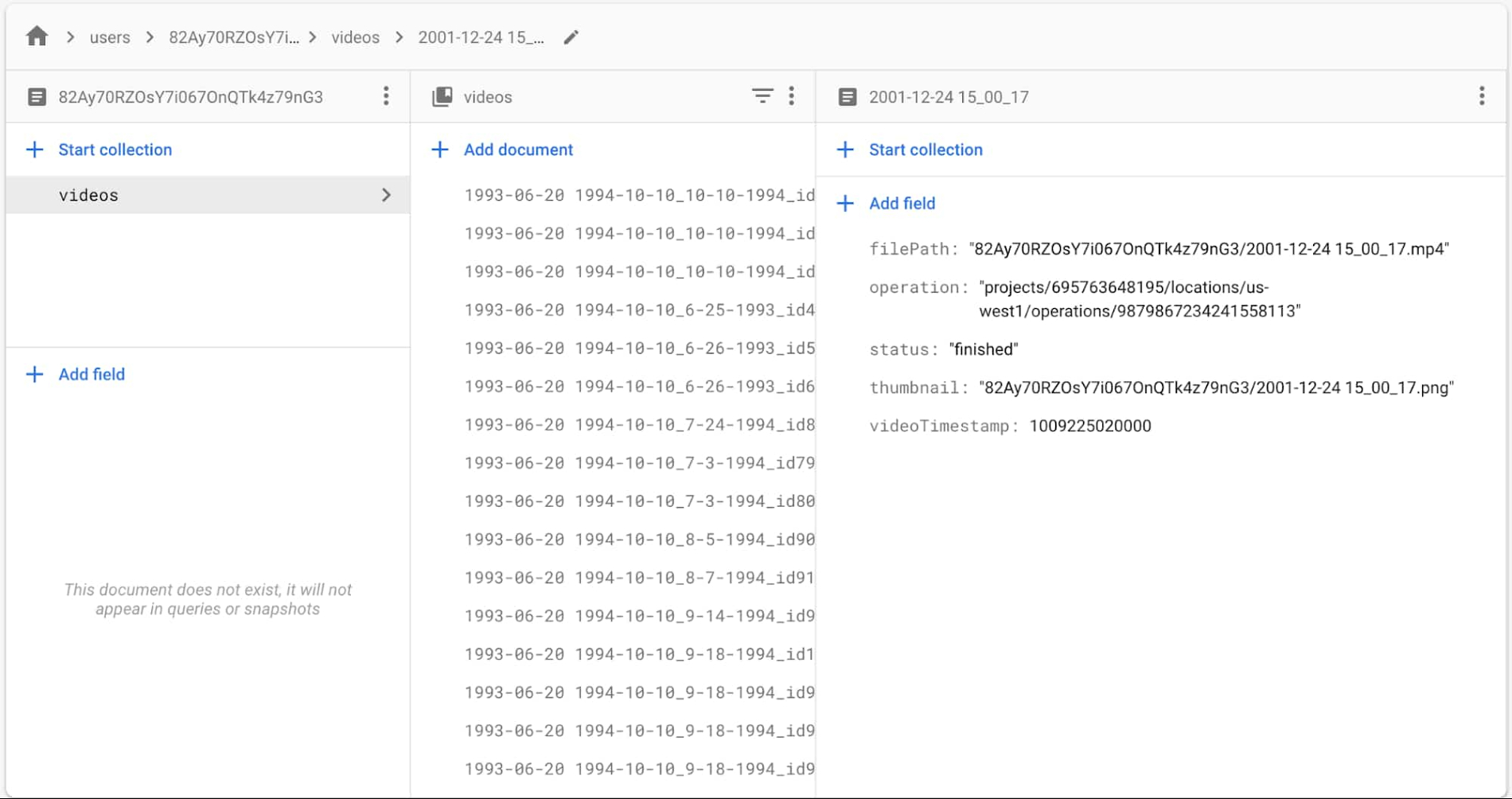
Firestore はアプリおよびウェブのデベロッパーを念頭に設計された、リアルタイムの NoSQL データベースです。動画のメタデータを Firestore に書き込んですぐ、アプリ内のデータにすばやく簡単にアクセスできるようになりました。
Algolia を使ったシンプルな検索
音声文字変換したもの、画面のテキスト、オブジェクトのラベルなど、動画から抽出したすべての情報を検索に使えるいい方法はないかと考えました。私が考えていたものは、ユーザーがタイプミスした(「birthdy party」など)言葉やフレーズでも検索に使えるうえに、すべてのメタデータを検索して最適な結果を提示してくれるようなツールでした。今回のようなタスクに使われることが多い、オープンソースの検索および分析エンジン、Elasticsearch を使うことも考えましたが、私のユースケースには少し強力すぎるように感じました。動画を検索するためだけに検索クラスタを丸ごと作成するつもりはありませんでした。
代わりに私が着目したのは、Algolia の Search API でした。このツールは、JSON データのアップロードはもちろん、すっきりとしたインターフェースであらゆるものを簡単に検索できる優れもので、誤字の修正や並べ替えなどの処理を行えます。自分のサーバーレス アプリに足りない部分を補完するのに最適なサーバーレス検索ソリューションでした。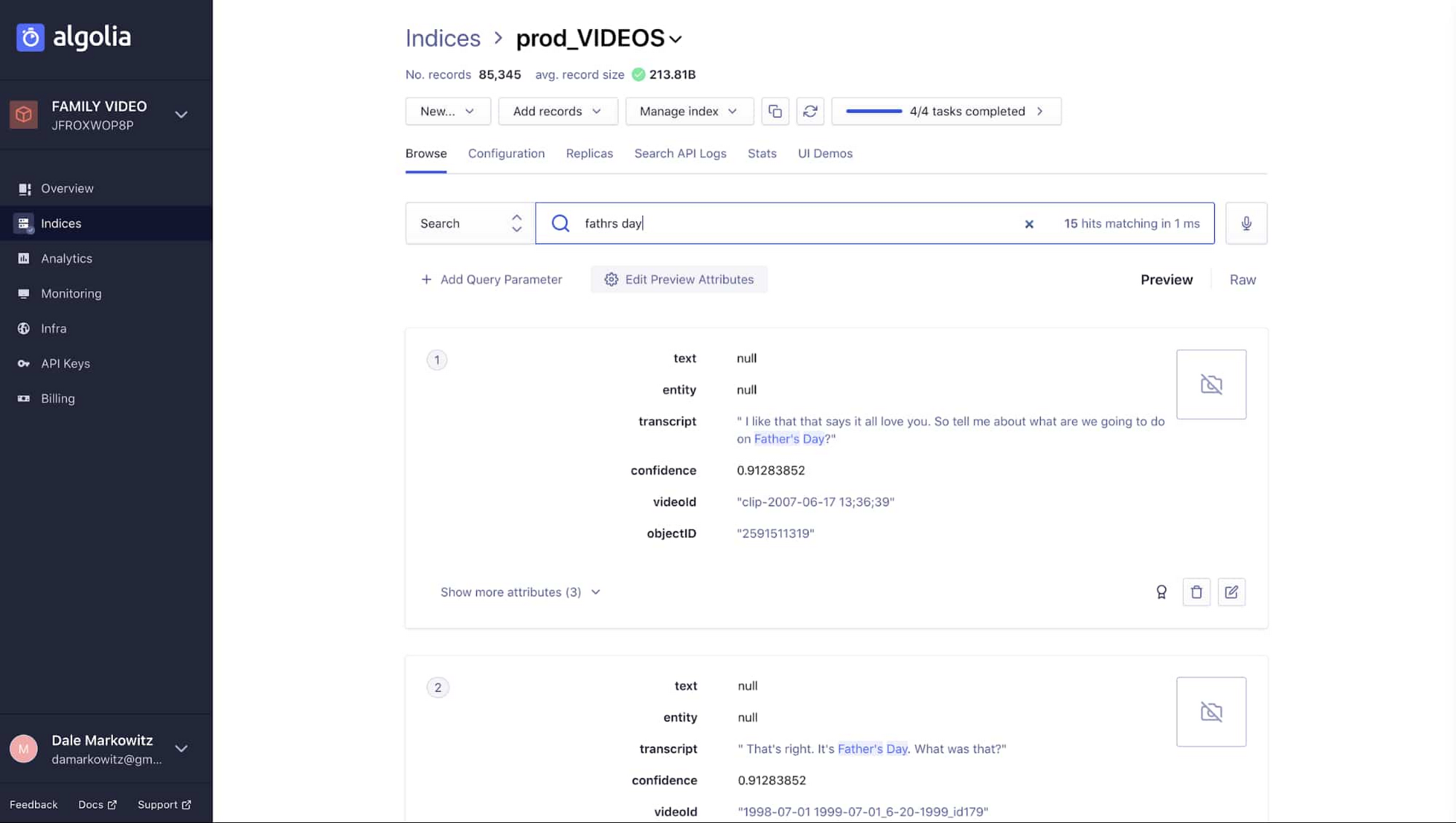
すべてを組み合わせる
こんなところでしょうか。動画をすべて分析し検索できるようにした後、残された作業は使いやすい UI を構築することだけでした。私は Flutter を利用することに決めましたが、Angular、React、モバイルアプリを使ってフロントエンドを構築することもできます。私の場合はこのようになりました。
忘れかけた記憶を思い出す
今回のプロジェクトで何よりも望んだことは、録画したことは覚えているものの見つけ出すのは不可能だと思われていた古い思い出を父が探し出せるようにすることでした。ですから、父の日の数日前にこれをプレゼントしたときに、私の口から出たのはまさにこの質問でした。「お父さん、見つけ出したい思い出はない?」
父は、私の 4 歳の誕生日に、私を驚かせようとバービーの自転車をプレゼントしたときのことを覚えていました。私たちが「自転車」を検索すると、動画が表示されました。私はその日のことをほとんど覚えていませんでしたし、動画を見たこともありませんでしたが、小さかった私は本当にびっくりしていたようです。ペダルを漕いでリビングルームを回りながら、「すごい!」と叫んでいました。今回が今までで最高の誕生日かつ父の日になったと言っていいかもしれません。


-By AI 応用エンジニア Dale Markowitz



