Google Kubernetes Engine 上の Kubeflow と Ray による機械学習プラットフォームの構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習(ML)機能を活用して、サービス、プロダクト、オペレーションの改善に役立てている組織の数は増え続けています。ML の機能の成熟とともに、組織の中の多くのチームやユーザーを支援する一元化された ML プラットフォームの構築が進められています。機械学習は、本質的に繰り返しのイテレーションを必要とする実験的なプロセスです。ML プラットフォームは、モデルのデプロイとデプロイ ワークフローを標準化し、繰り返しのプロセスの一貫性を高めます。これにより、生産性が向上し、プロトタイプから本番環境への移行時間を削減できます。
ML をクラウド上で初めて試す場合、多くの技術担当者は、Google Cloud の Vertex AI といったようなフルマネージド ML プラットフォームから始めることでしょう。フルマネージド プラットフォームは、多くの複雑な問題を抽象化し、エンドツーエンドのワークフローを簡略化します。しかし、ほとんどの意思決定がそうであるように、ここにもトレードオフが存在します。組織は管理と柔軟性などの理由から、自分たちでカスタムメイドのセルフマネージド ML プラットフォームを構築したいと考えるかもしれません。独自のプラットフォームを構築すれば、リソースをより詳細に管理できるからです。ご自身の組織のニーズに合わせて、独自のリソース利用制約、アクセス権限、インフラストラクチャ戦略を実装できます。ツールとフレームワークに対しても、さらなる柔軟性が期待できます。システムは完全にオープンなため、使用中の ML ツールとの統合も可能です。さらに、クラウドネイティブなプラットフォームは、定義上、クラウド プロバイダ間で移植可能であるため、ベンダーのロックインも回避することができます。
セルフマネージド ML プラットフォームにとって、オープンソース ソフトウェアはデジタル イノベーションの重要な推進力です。ML 技術の進化に興味をお持ちで、その動向をチェックされているなら、オープンソース機械学習フレームワーク、プラットフォーム、そしてツールのエコシステムの成長にもお気づきのことと思います。しかし、完全な ML ソリューションを提供できる単一のオープンソース ライブラリはまだありません。そのため、ML プラットフォームを構築するには、複数のオープンソース プロジェクトを統合する必要があるのです。
ML プラットフォームの構築を始めるには、ノートブックでのプロトタイピングからオンライン サービングへの大規模トレーニングまでの基本的な ML ユーザー ジャーニーをサポートする必要があります。さらに、複数のチームを抱える組織では、ID ベースの認証と認可によるマルチユーザーのサポートという管理上の要件もサポートしなければなりません。Kubeflow と Ray という 2 つの主要なオープンソース プロジェクトを組み合わせることで、そうした必要性をサポートできます。Kubeflow は、マルチユーザー環境とインタラクティブなノートブック管理を提供します。Ray は、トレーニングとサービングを含む ML のライフサイクル全体にわたって分散されたコンピューティング ワークロードをオーケストレートします。
Google Kubernetes Engine(GKE)は、自動スケーリングと自動プロビジョニングにより、オープンソースの ML ソフトウェアのクラウドでのデプロイを簡素化します。GKE を使うことで、基盤となるインフラストラクチャのデプロイと管理の手間を大規模に軽減し、選択した ML フレームワークを柔軟に使用することができます。この記事では、Kubeflow と Ray を組み合わせて、シームレスなエクスペリエンスを生み出す方法をご紹介します。また、この 2 つを GKE にデプロイすることで、プラットフォーム ビルダーが、包括的で本番環境に対応した ML プラットフォームを提供できる方法を紹介します。
Kubeflow と Ray
まずは、これら 2 つのオープンソース プロジェクトについて詳しく見てみましょう。Kubeflow と Ray が取り組むのは、どちらも ML の大規模な実現というテーマではありますが、両者は問題のまったく違う側面にそれぞれ焦点を当てています。
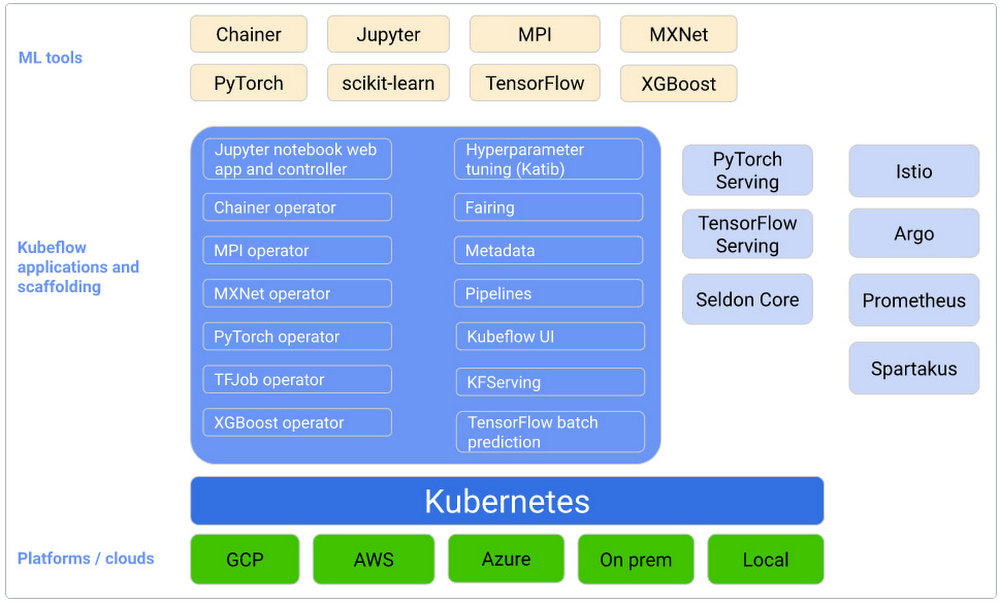
Kubeflow は、ML モデルの構築、トレーニング、デプロイのライフサイクルを簡素化することを目的とした、Kubernetes ネイティブの ML プラットフォームです。そのため、一般的な MLOps が中心となっています。Kubeflow は、以下のようなユニークな機能を提供します。
プロトタイピングのための Jupyter ノートブックとの組み込みのインテグレーション
マルチユーザーの分離サポート
Kubeflow Pipelines によるワークフロー オーケストレーション
Istio インテグレーションを通じた ID ベースの認証と認可
GCP、Azure、AWS といった主要なクラウド プロバイダとのすぐに利用できるインテグレーション
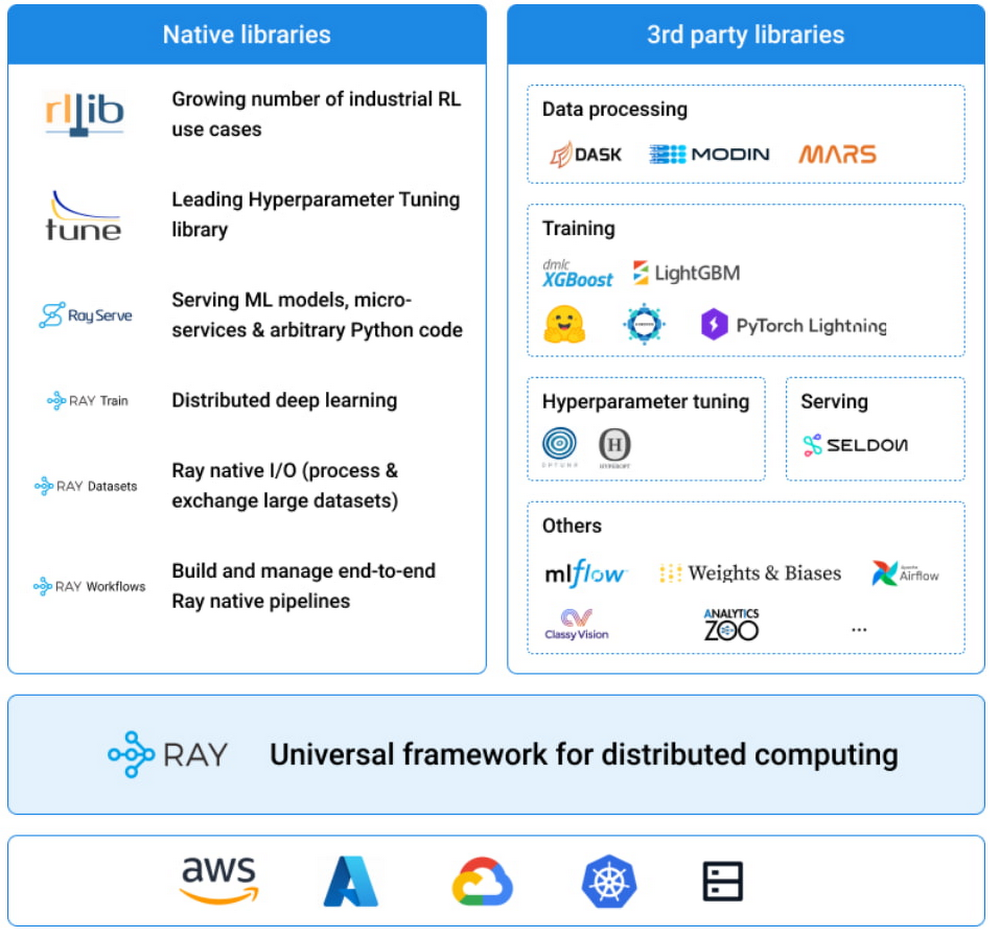
Ray は、大規模なデータ処理、モデル トレーニング、強化学習、モデル サービングのための豊富な一連のライブラリを備えた、汎用分散コンピューティング フレームワークです。AI や Python のワークロードを構築、スケーリングするためのシンプルな API として、お客様から好評をいただいています。アプリケーションそのものに焦点を当てることで、ユーザーは統一された柔軟な API セットで分散コンピューティング ソフトウェアを構築できます。Ray が提供する高度なライブラリの一部をご紹介します。
強化学習のための RLLib
ハイパーパラメータ調整のための Ray Tune
分散型ディープ ラーニングのための Ray Train
スケーラブルなモデル サービングのための Ray Serve
前処理のための Ray Data
Ray は Kubernetes ネイティブのプロジェクトではないことに注意する必要があります。Ray を Kubernetes 上でデプロイするために、オープンソース コミュニティは、KubeRay という、読んで字のごとく、Kubernetes 上で Ray をデプロイするためのツールキットを作成しました。KubeRay は、カスタム リソース API やスケーラブル オペレータなど、多くの素晴らしい機能を持ったパワフルな一連のツールを提供します。詳細については、こちらをご覧ください。
ここまで、Kubeflow と Ray の違いを見てきましたが、ご自身の組織にはどちらのプラットフォームが適しているのか迷われるかもしれません。Kubeflow の MLOps 機能と Ray の分散コンピューティング ライブラリにはそれぞれの利点があり、それ単独でも有用です。しかし、この 2 つのシステムの利点を組み合わせることができたらどうでしょう。次のような環境を想像してみてください。
自動スケーリングとリソースのプロビジョニングで、Ray Train をサポート
ID ベースの認証と認可とのインテグレーション
マルチユーザーの分離とコラボレーションをサポート
インタラクティブなノートブック サーバーが含まれる
では、この 2 つのプラットフォームを組み合わせて、それぞれの便利な機能を活用する方法を見ていきましょう。具体的には、Kubeflow でインストールした GKE クラスタに Kuberay をデプロイします。そのシステムは、次のようになります。
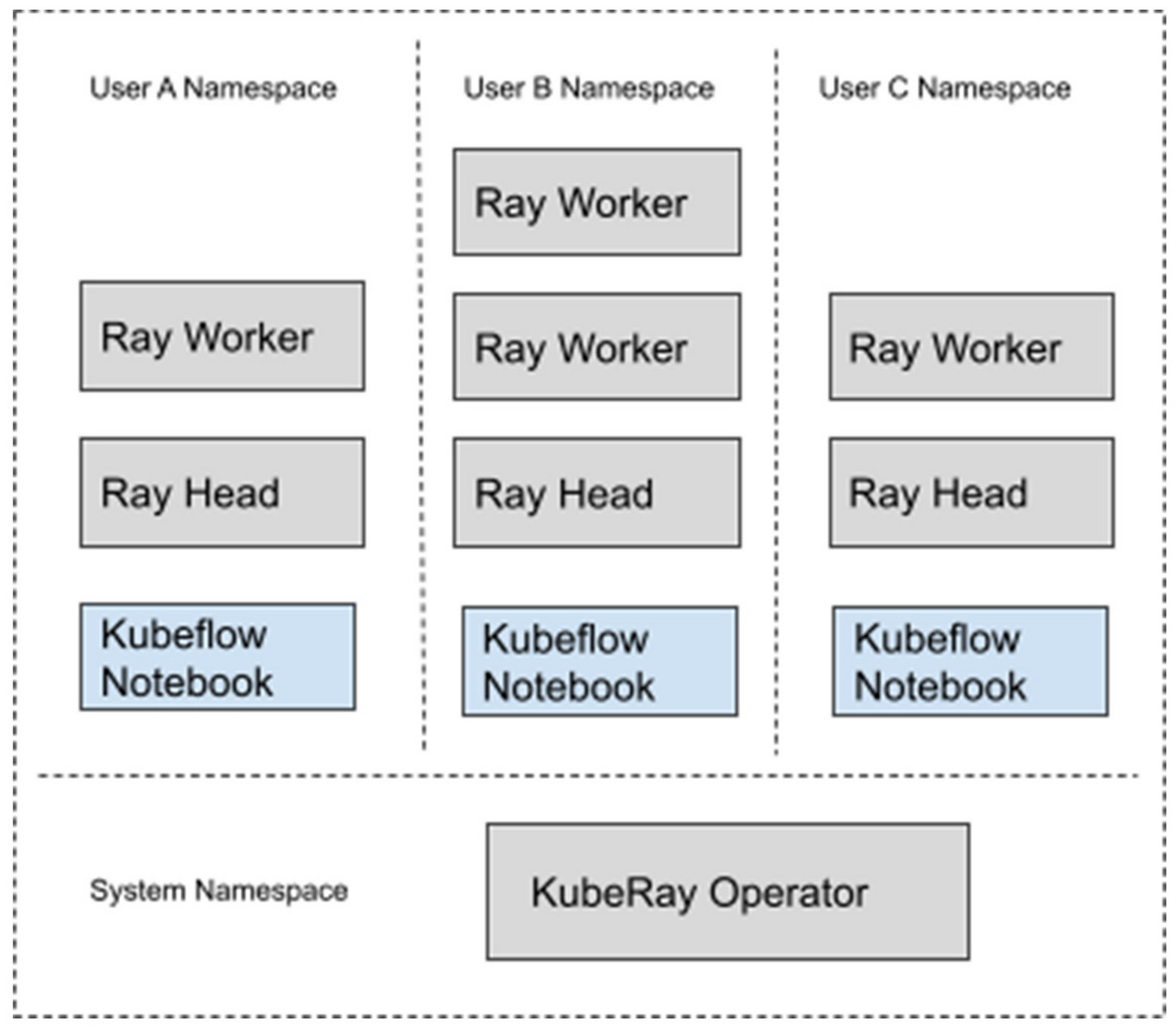
このシステムでは、Kubernetes クラスタは「プロファイル」と呼ばれる論理的に分離されたワークスペースにパーティション分割されます。新規ユーザーはそれぞれ自分のプロファイルを作成し、それが Kubernetes クラスタ内の全リソースのコンテナとなります。ユーザーは、指定された Namespace 内で、Ray クラスタや Jupyter ノートブックなどの独自のリソースをプロビジョニングできます。ユーザーのリソースが Kubeflow ダッシュボードを通じてプロビジョニングされている場合、Kubeflow は自動的にこれらのリソースをプロファイルの Namespace に配置します。
この設定において、各 Ray クラスタはデフォルトで Istio によるロールベースのアクセス制御ポリシーにより保護され、不正なアクセスを防止しています。これにより、各ユーザーは自分の Ray クラスタをそれぞれ独立して操作でき、他のチームメンバーとの Ray クラスタの共有も可能になります。
この設定では、以下のバージョンを使用します。
Google Kubernetes Engine 1.21.12-gke.2200
Kubeflow 1.5.0
Kuberay 0.3.0
Python 3.7
Ray 1.13.1
このデプロイで使用されている構成ファイルは、こちらでご覧になれます。
Kubeflow と Kuberay のデプロイ
Kubeflow のデプロイには、こちらの GCP の手順を使用します。簡略化のために、ほぼデフォルトの構成設定を使用しています。デプロイの前に、自由にカスタマイズをテストすることができます。たとえば、こちらの手順に沿って、クラスタで GPU ノードを有効にできます。
KubeRay オペレータのデプロイは、非常に簡単です。以下の最新のリリース バージョンを使用します。
これにより、クラスタの「ray-systems」Namespace に、KubeRay オペレータをデプロイできます。
Kubeflow のユーザー プロファイルの作成
Kubeflow でリソースをデプロイして使用する前に、ユーザー プロファイルを作成する必要があります。GKE のインストール手順に沿えば、ブラウザで https://[cluster].endpoints.[project].cloud.goog/ に移動できるはずです。ここで、[cluster] は GKE クラスタの名前、[project] は GCP プロジェクトの名前です。
これにより、ウェブページにリダイレクトされ、そこで GCP 認証情報を使用した認証ができるはずです。
ダイアログに従っていくと、Kubeflow はあなたを管理者とする Namespace を作成します。ワークスペースに他の人を招待する方法については、後ほど説明します。
Ray のワーカー イメージの構築
次に、Ray クラスタに使用するイメージを構築しましょう。Ray はバージョンの互換性に大きな制約があります(たとえば、ヘッドノードとワーカーノードは同じバージョンの Ray と Python を使用する必要があります)。なので、独自のワーカー イメージを用意してバージョン管理することを強くおすすめします。次の Docker ページから、お望みのベースイメージをお探しください。rayproject/ray - Docker Image
Ray 1.13 と Python 3.7 を使用した、正常に機能しているワーカー イメージは以下の通りです。
CPU ではなく GPU を使いたい場合のために、GPU 上で動作するワーカー イメージ用の同じ Dockerfile を以下に示します。
Docker を使用して両方のイメージを構築し、イメージ リポジトリに push します。
Jupyter ノートブック イメージの構築
同様に、使用するノートブック イメージも作成する必要があります。このノートブックを使って Ray クラスタを操作するので、ノートブックが Ray ワーカーと同じバージョンの Ray と Python を使用していることを確認する必要があります。
Kubeflow のサンプル Jupyter ノートブックは、サンプル ノートブック サーバーをご覧ください。今回の例では、components/example-notebook-servers/jupyter/Dockerfile の PYTHON_VERSION を以下のように変更しました。以前のステップ同様、Docker を使用してノートブック イメージを構築し、イメージ リポジトリに push します。
Ray クラスタのデプロイ
これで、Ray クラスタの構成とデプロイの準備が整いました。
1. GitHub から以下のサンプル yaml ファイルをコピーします。
2. ファイル内の設定を以下のように編集します。
a. ユーザーの Namespace は、Kubeflow のプロファイル名と一致するように値を変更します。
b. Ray ヘッドとワーカーの設定では、以前構築したイメージを指すように値を変更します。
c. 必要に応じて、リソースのリクエストと制限を編集します。たとえば、ワーカーノードの CPU や GPU の要件は以下で変更できます。
3. クラスタをデプロイします。
4. クラスタはすぐに使えるようになるはずです。GKE クラスタでノードの自動プロビジョニングを有効にしている場合、使用状況に応じてクラスタが動的にスケールアップまたはスケールダウンしているのが確認できるはずです。以下を実行することで、クラスタの状態を確認できます。
また、サービス エンドポイントが作成されているかも確認できます。
このサービス名は後で必要となるので、覚えておいてください。
これで ML プラットフォームはすべて設定され、モデルのトレーニングを開始する準備が整いました。
ML モデルのトレーニング
ノートブックを使用してモデルのトレーニングをオーケストレートしてみます。Jupyter ノートブック セッションから Ray にアクセスできます。
1. Kubeflow ダッシュボードで、[Notebooks] タブに移動します。
2. [New Notebook] をクリックします。
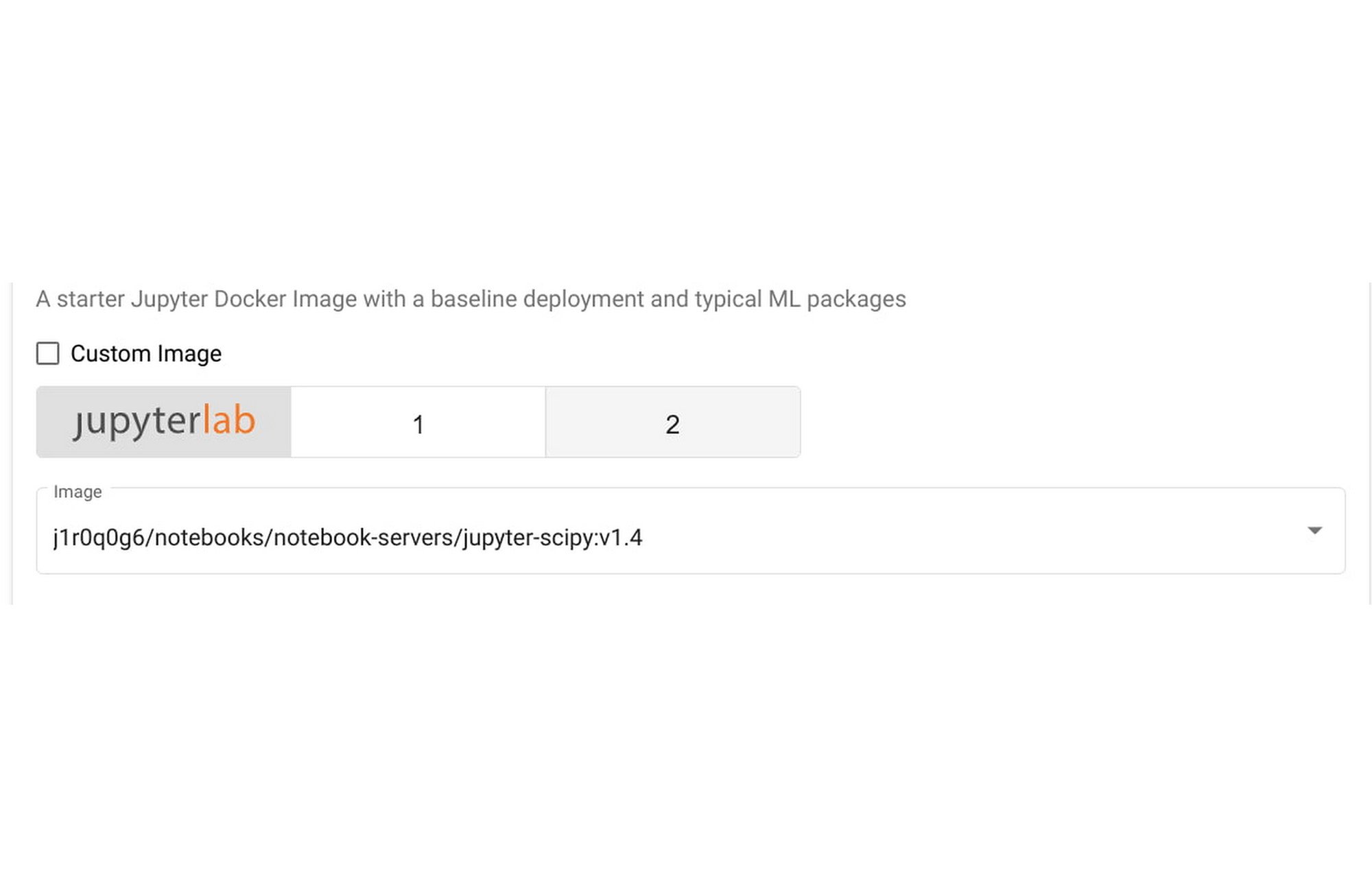
3. [Image] セクションで、[Custom Image] をクリックして、こちらで構築した Jupyter ノートブック イメージにパスを入力します。
4. 必要に応じて、ノートブックのリソース要件を構成します。デフォルトのノートブックでは、CPU の半分と 1G のメモリを使用します。なお、これらのリソースはノートブック セッションのみで、トレーニング リソースには含まれないことに注意してください。その後、Ray を使用して、GKE 上でリソースのオーケストレーションを大規模に行います。
5. [LAUNCH] をクリックします。
6. ノートブックのデプロイが終了したら、[Connect] をクリックして、新しいノートブック セッションを開始します。
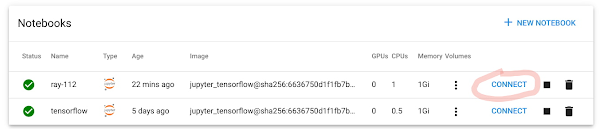
7. ノートブックの中で、[File] -> [New] -> [Terminal] をクリックして、ターミナルを開きます。
8. Ray 1.13 をターミナルにインストールします。
9. これで、このノートブックと前のセクションでデプロイしたばかりの Ray クラスタを使用して、実際の Ray アプリケーションを実行する準備が整いました。こちらでは、正規の Ray Trainer の例を使って、.ipynb ファイルを作ってみました。
10. ノートブックでセルを実行します。Ray クラスタに接続するマジックラインは以下の通りです。
これは、先ほど作成したサービス エンドポイントと一致するはずです。複数の異なる Ray クラスタがある場合、ここでエンドポイントを変更するだけで、他のエンドポイントに接続できます。
11. 次の数行で、クラスタ上で Ray Trainer プロセスが開始されます。
ここで、4 つのワーカーを指定していますが、これは Ray クラスタのレプリカの数と一致しています。この数値を変更すると、Ray クラスタはリソースの需要に応じて自動的にスケールアップまたはスケールダウンします。
ML モデルのサービング
このセクションでは、前のセクションでトレーニングしたばかりの機械学習モデルをどのようにサービングするかについて見ていきます。
1. 同じノートブックを使用して、トレーニングの手順が完了するのを待ちます。トレーニングしたモデルの指標を含む出力ログが表示されるはずです。
2 次のセルを実行します。
先ほど作成したのと同じサービス エンドポイントを使用して、トレーニングしたモデルのサービングを開始します。
3. 新しいノートブックを作成して、推論エンドポイントが動作していることを確認できます。こちらで使用できます。
4. 先ほどと同じ推論エンドポイントを呼び出していますが、以下のように別のポートを使っていることに注意してください。
5. ノートブック セッションに推論結果が表示されるはずです。
Ray クラスタの共有
インタラクティブなノートブックと Ray クラスタを備えた機能的なワークスペースができました。他の人を招待して共同作業してみましょう。
1. Cloud コンソールで、ユーザーに最小限のクラスタのアクセス権をこちらで付与します。
2. Kubeflow ダッシュボードの左側のパネルで、[Manage Contributors] を選択します。
3. [Contributors to your namespace] セクションで、アクセス権を付与したいユーザーのメールアドレスを入力します。Enter キーを押します。
4. そのユーザーは、Namespace を選択し、Ray クラスタを含むノートブックにアクセスできるようになります。
Ray ダッシュボードを使用する
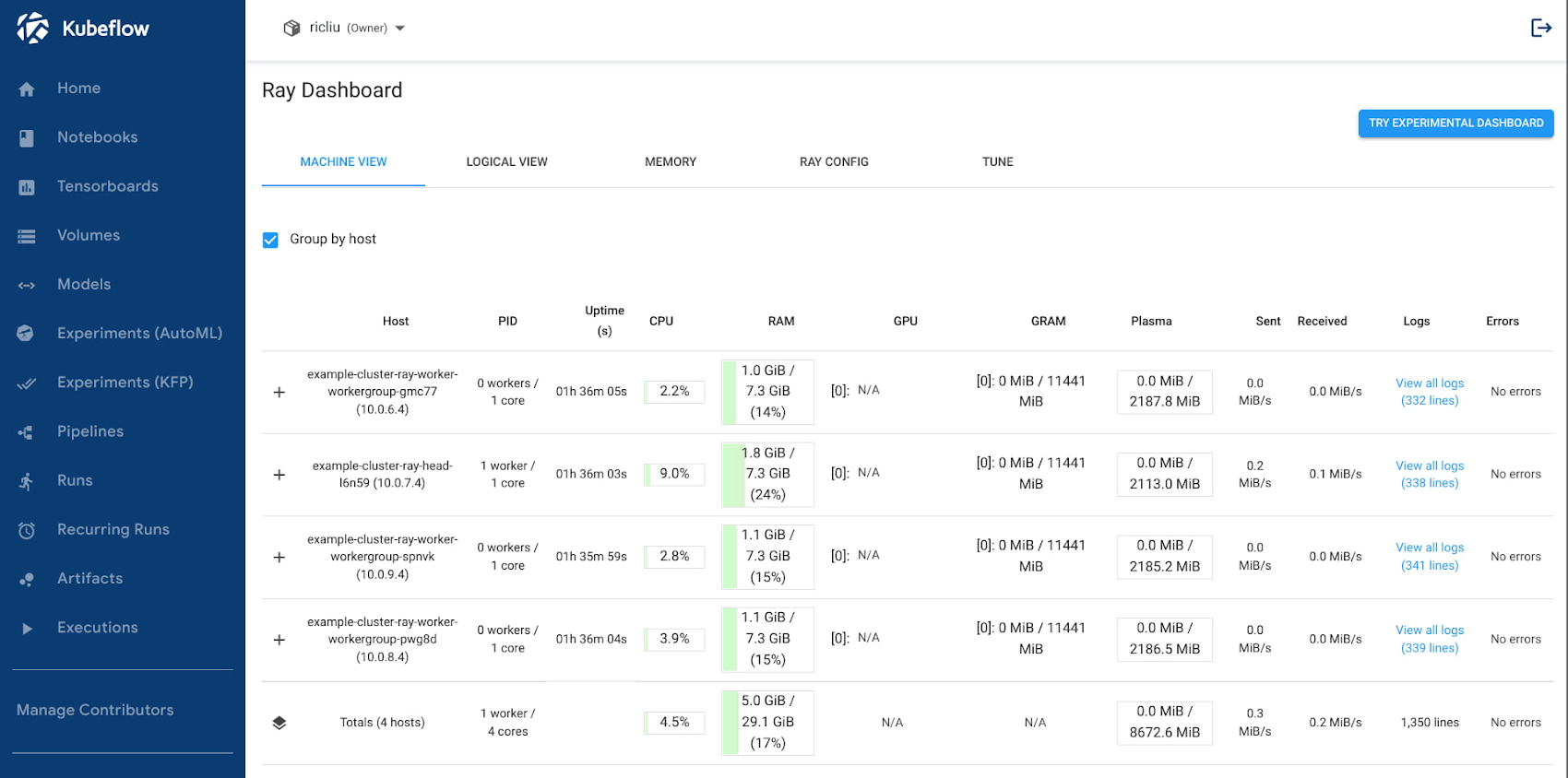
最後に、Istio の仮想サービスを使って Ray ダッシュボードを表示させることも可能です。以下の手順で、Kubeflow のセントラル ダッシュボード コンソールの中にダッシュボード UI を表示できます。
1. Istio 仮想サービスの構成ファイルを作成します。$(USER_NAMESPACE) を、ユーザー プロファイルの Namespace と入れ替えます。ローカル ファイルに保存します。
2. 仮想サービスをデプロイします。
3. ブラウザのウィンドウで、https://<host>/_/example-cluster/ に移動します。以下のように、Ray ダッシュボードがウィンドウに表示されるはずです。
まとめ
これまでのまとめをしてみましょう。今回は、Kubeflow と Ray という 2 つの主要 ML フレームワークを、同じ GCP Kubernetes クラスタにデプロイする方法を紹介しました。また、ユーザー認証に IAP(Identity-Aware Proxy)といった GCP の機能を利用することで、アプリケーションを保護しながら、クラウド管理者の負担を軽減できます。最終的には、各システムの便利な機能を取り入れた、統合された本番環境に対応したシステムが完成します。
Ray API を使用した分散コンピューティング ワークロードのオーケストレーション
Kubeflow を使用したマルチユーザーの分離
Kubeflow ノートブックを使用したインタラクティブなノートブック環境
Google Kubernetes Engine を使用したクラスタの自動スケーリングと自動プロビジョニング
ここではできることの一部をご紹介しただけですが、さらに次のようなことも実行できます。
Vertex Model monitoring などのその他の MLOps サービスとのインテグレーション
アーティファクト リポジトリによる、より迅速で安全なイメージのストレージと管理
GCSFuse を使用した非構造化データの高スループット ストレージ
NCCL Fast Socket によるグループ通信のネットワーク スループットの向上
皆様の ML プラットフォームの発展と、チームが機械学習でイノベーションを進めて行かれることを楽しみにしています。今後、ML プラットフォームの追加機能を有効にする方法についての記事を掲載予定ですので、こちらもぜひご一読ください。
- Google Kubernetes Engine シニア ソフトウェア エンジニア Richard Liu
- Google Kubernetes Engine AI/ML プロダクト マネージャー Winston Chiang


