Comment développer et déployer des applications IA à l’Edge

Yanni Peng
Customer Engineer
Abdul Haseen Kinadiyil
Staff Technical Solutions Consultant
Que ce soit pour s'assurer que les ouvriers portent bien leur équipement de protection individuelle (EPI), pour gérer les stocks des magasins et des entrepôts, ou pour assurer une maintenance prédictive sur les chaînes de montage, les modèles ML de vision exécutés à l’Edge peuvent répondre à une grande variété de cas d’usage et profondément améliorer l'expérience des clients ou des collaborateurs. Cependant, l'exploitation de l'IA, la sécurité des données critiques et la complexité de gestion de multiples déploiements en périphérie (à l’Edge) peuvent constituer des obstacles difficiles à surmonter.
La maintenance prédictive, la sécurité en usine, la reconnaissance vocale, et bien d'autres encore sont autant de cas d’usages très populaires des technologies ML et IA. Ces cas d'utilisation nécessitent des modèles d'IA déployés sur des sites périphériques, à l’Edge, tels que des installations de fabrication, des centres de soins de santé, des magasins de détail, des véhicules, etc. Pour simplifier le déploiement et la gestion des workloads IA à l'échelle du cloud public et du Edge, Google Cloud propose un ensemble de technologies et de plateformes permettant d'exécuter et de gérer des applications d'IA à grande échelle sur le cloud public, les sites périphériques Edge et les appareils.
Déployer données et IA à l’Edge avec Google Cloud
Ainsi, avec sa plateforme Vertex AI, Google Cloud a considérablement simplifié et fluidifié le développement, le déploiement et l'exploitation d'applications IA industrielles.
Vertex AI fournit des modèles pré-entraînés de haute qualité, tels que des modèles de reconnaissance de produits et de tags, ainsi que d'autres modèles d'IA pour la vision et l’analyse vidéo par exemple.
Parce que les applications Edge AI peuvent nécessiter le développement de modèles personnalisés tels que la reconnaissance d'objets, la plateforme Vertex AI permet aux développeurs de personnaliser ou former des modèles dans le cloud puis de les déployer aisément sur les sites Edge.
Parallèlement, l’offre Google Distributed Cloud (GDC) permet aux développeurs et aux entreprises de combiner le meilleur de l’IA, de la sécurité et des outils open source de Google tout en conservant leur indépendance et leur contrôle total des données critiques partout où se trouvent leurs clients, et y compris à l’Edge que ce soit au travers de Google Distributed Cloud Edge (GDC Edge et son portfolio de services managés et de hardware conçus pour les workloads d’entreprises dans les domaines du retail, du manufacturing, des transports…) ou de Google Distributed Cloud Hosted (GDC Hosted, une solution cloud privé isolée pour aider les gouvernements et les entreprises soumises à régulation à respecter des normes rigoureuses de localisation et de sécurité des données).
Autre composante différenciante, Edge TPU est un ASIC (un circuit intégré spécialisé) spécialement conçu par Google Cloud pour l’exécution des inférences IA à l’Edge. Il offre des performances élevées dans un faible encombrement physique et énergétique idéalement adapté aux déploiements d’IA de haute précision à la périphérie. Il complète Cloud TPU et les services de Google Cloud pour fournir une infrastructure matérielle et logicielle de bout en bout, du Cloud à l’Edge. Il ne s'agit pas seulement d'une solution matérielle, mais d'une combinaison de processeurs, de logiciels ouverts et d'algorithmes d'IA de pointe pour fournir des solutions d'IA de haute qualité et faciles à déployer dans l’Edge. Notamment, Edge TPU vous permet de déployer une inférence ML en périphérie à l’aide de différentes solutions matérielles de prototypage et de production signées Coral.
Edge TPU complète ainsi les CPU, GPU, FPGA et autres solutions ASIC pour l'exécution de l'IA dans l’Edge.
Avec ce portfolio de solution Google Cloud en tête, voyons un peu plus en détail comment construire, former et déployer dans l’Edge un modèle ML basé sur la vision Google Vertex AI, Google Distributed Cloud et Edge TPUs pour prendre en charge des cas industriels tels que la détection des stocks, la détection des EPI et la maintenance prédictive.
De l’apprentissage dans l’Edge
Lors du déploiement de workloads IA sur des emplacements Edge, chaque cas d'usage doit s'assurer que les modèles formés sont déployés sur la topologie adéquate en prolongement du cloud public. D'un côté du spectre, nous avons de grandes fermes de serveurs utilisant des hyperviseurs. De l'autre, on exploite une multitude de capteurs et autres dispositifs tels que des caméras.
Avec Google Cloud, les développeurs bénéficient d'une expérience homogène lors du développement et de l'exécution des applications IA sur les sites en périphérie. Et les opérateurs de la plateforme IA déployée gèrent et surveillent les applications aisément, quel que soit leur lieu d'exécution.
En utilisant les plateformes GDC, nos clients ont la possibilité de déployer indifféremment leurs modèles AI/ML sur les Edge TPUs ou sur des GPUs. Les GPU et TPU, en plus de simplifier les tâches IA, offrent aussi de multiples avantages tels que l’accélération des exécutions, des performances graphiques améliorées, de l'apprentissage profond, une efficacité énergétique certaine et une indéniable scalabilité. Les modèles ML peuvent être formés avec les Cloud TPUs ou les GPUs Cloud puis être ensuite déployés sur GDC dans l’Edge comme dans les datacenters. Rappelons au passage que les plateformes GDC supportent les GPU NVidia T4 et A100.
Un processus de déploiement et de gestion d'un modèle ML à l’Edge se déroule typiquement en plusieurs étapes :
- Préparation des données
- Développement des modèles
- Entraînement des modèles
- Mise en place des modèles
- Surveillance des prédictions
- Gestion des versions
Combinés, Vertex AI et GDC permettent de rationaliser et fluidifier l’ensemble de ce processus, de la préparation jusqu’à l’exécution à grande échelle des workloads IA sur l’Edge. Autre brique essentielle, Google Kubernetes Engine (GKE) vous permet d'exécuter des charges de travail d'IA conteneurisées qui nécessitent une TPU ou un GPU pour accélérer l'inférence ML, l'entraînement et le traitement des données dans Google Cloud. Vous pouvez exécuter les Workloads IA sur GKE dans l’Edge grâce à GDC.
Pour démontrer le potentiel de ces technologies et des usages de l’IA dans les points de vente, T-Mobile et Google Cloud ont, par exemple, développé le projet « magic mirror (miroir magique) », un écran interactif s’appuyant sur GDG Edge : l’utilisateur montre simplement un objet en magasin et l’écran lui donne vie comme par magie fournissant détails et vidéos explicatives.
Du ML de bout en bout
Comme nous l’avons vu, Google Cloud propose une suite complète de services et d’outils couvrant, de bout en bout, la création, le déploiement à grande échelle et la gestion de solutions IA à l’Edge. Nos clients peuvent ainsi concevoir des solutions Edge robustes adaptées à leurs différents cas d’usage de l’IA en périphérie. L’illustration ci-dessous présente une vue d’ensemble de la manière dont les différents composants et services évoqués ci-dessus s’imbriquent harmonieusement.
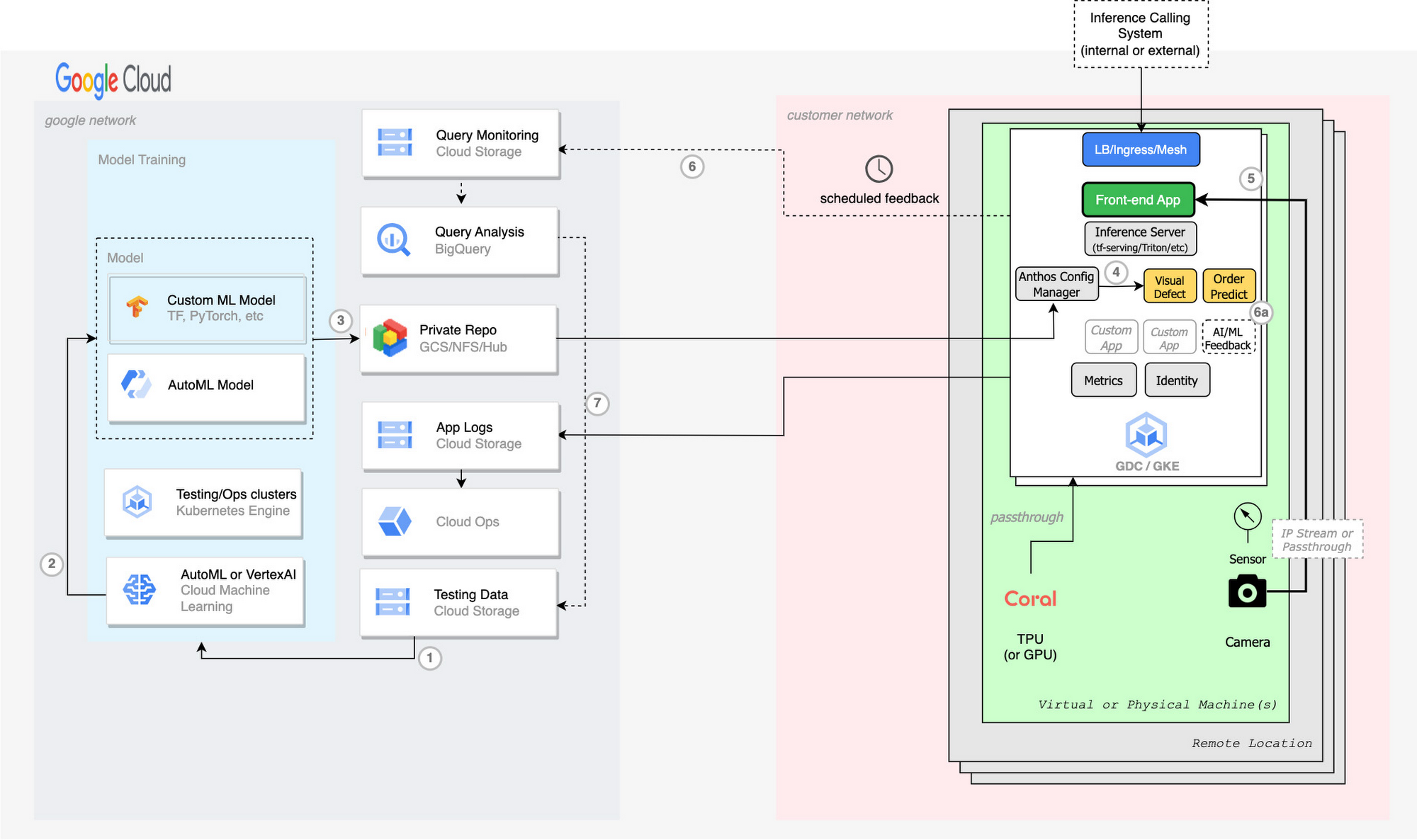
- Entraînement du modèle à l'aide de données étiquetées ou annotées sur Vertex AI
- Exportation du modèle Vertex AI
- Stockage du modèle exporté dans un Bucket GCS (Google Cloud Storage) ou dans le repository privé AI Hub
- Chaque cluster Edge télécharge ce nouveau modèle en utilisant KRM (configuration YAML K8s) sur un déploiement TF Serving ou Inference Server à travers Anthos Config Manager (ACM).
- Le feedback peut optionnellement être exporté sous forme de résultats en pourcentage (6) ou vers une application personnalisée de vérification des résultats IA par l’humain (6a). Exportation vers les buckets GCS.
- Utilisation de BigQuery pour analyser l'efficacité du modèle ML, identifier les modifications apportées aux étiquettes, à l'attribution, aux classificateurs, à la qualité, etc., afin d’enrichir les données de test (7).
Ce schéma fonctionnel en tête, entrons un peu plus au cœur des technologies et voyons comment configurer les Edge TPUs et GPUs qui animent les IA sur GDC.
Configurer les Edge TPUs
Lorsque vous développez pour une plateforme fonctionnant sous Linux, Windows ou macOS, vous pouvez choisir d'utiliser TensorFlow Lite (bibliothèque spécialement optimisée pour le déploiement de modèles à l’Edge) et une programmation Python ou C/C++.
Quel que soit le langage choisi, vous devez installer le moteur d'exécution Edge TPU (libedgetpu.so) pour tirer profit des accélérations matérielles intégrées dans les cartes de prototypages et les cartes IOT « IA » de notre partenaire Coral. Ce dernier propose des guides d’installation pour chacun de ses dispositifs IA qui détaillent notamment comment installer la bibliothèque TensorFlow Lite appropriée et la bibliothèque optionnelle Coral correspondante.
Les modèles ML sont packagés sous forme de containers et nécessitent un développement personnalisé.
Configuration des GPU
Voyons maintenant comment configurer les GPU NVIDIA T4 pour les Workers K8s sur des plateformes GDC ou Edge Anthos GKE.
Prérequis :
- Configuration des rôles et des autorisations.
- Désactiver selinux
- Désactiver apparmor
- Si selinux est activé, exécuter le plugin daemonset avec un contexte de sécurité privilégié.
- Dépendances :
- Installer les dépendances Cuda sur le système d'exploitation
- Installer le pilote NVIDIA-Linux à l'aide d'un script ou manuellement.
3 . Installer le runtime docker Nvidia
- Configurer le runtime conteneurs de kubernetes pour qu'il pointe vers Nvidia (*dans la plupart des cas, il s'agit de containerd).
- Installer le daemon Nvidia sur chaque nœud.
- Vérifier les systèmes d'exploitation pris en charge
- Tests
- Utiliser l'outil CLI nvidia-smi
- Exécuter un workload de test gpu dans le cluster
- Exécuter cmd check gpu : kubectl describe nodes
Installation :
- Configurer la sécurité (selinux, apparmor)
Pour désactiver SELinux, ouvrez le fichier de configuration /,etc/selinux/config et changez la propriété en : SELINUX=disabled
- Configurez Anthos Bare Metal en lançant des commandes bmctl sur la VM (vous devez être propriétaire/éditeur du projet utilisé).
- Docker
Ajoutez votre utilisateur au groupe docker
Redémarrez la machine virtuelle pour que les modifications apportées au groupe d'utilisateurs de Docker soient prises en compte.
- Installer les pilotes Nvidia et cuda
Connectez-vous en mode ssh à la VM et exécutez les commandes suivantes :
Reportez-vous à cette page en cas d'erreur ou si vous souhaitez en savoir plus.
- Installez Nvidia Docker et préparez le conteneur par défaut de kubernetes pour nvidia :
- Installer le daemonset (peut avoir besoin d'être exécuté en tant que administrateur) :
7. Vérifiez la bonne installation en utilisant le client nvidia-smi et vérifiez kubectl describe node. Il devrait lister "nvidia/gpu" avec une valeur de 1 ou plus sous les ressources allouables.
Prochaines étapes ?
L'Edge computing accélère la transformation numérique des entreprises de manière inédite. Avec un portefeuille complet de solutions matérielles et logicielles entièrement managées, Google Distributed Cloud rapproche les solutions d'IA et d'analyse de Google Cloud de l'endroit où vos données sont générées et consommées, afin que vous puissiez exploiter des informations en temps réel. Grâce à l’universalité de GKE, vous bénéficiez d’une expérience et d’une administration cohérente du cloud jusqu’à l’Edge quel que soit le workload IA envisagé.
Pour en savoir plus sur comment exploiter et combiner vos données à l’Edge et les dernières technologies IA de Google Cloud sur des infrastructures Google Distributed Cloud Edge : Google Distributed Cloud by Google Cloud
Pour en savoir plus sur Google Distributed Cloud, une famille de produits qui vous permet de libérer vos données avec les dernières avancées en matière d'IA à partir de déploiements en périphérie, de centres de données privés, de nuages aériens et de nuages hybrides. Disponible pour les entreprises et le secteur public, vous pouvez désormais tirer parti de l'IA, de la sécurité et des logiciels open source de Google, les meilleurs de leur catégorie, avec l'indépendance et le contrôle dont vous avez besoin, partout où se trouvent vos clients.
Pour plonger davantage dans les cas d’usage de l’IA à l’Edge et l’exploitation de Google Distributed Cloud et des hardwares Edge TPU, retrouvez en replay nos sessions Google Cloud Next 2023 dédiées à ces sujets :
- Running AI at the edge to deliver modern customer experiences Session ARC 101
- Mind the air gap: How cloud is addressing today’s sovereignty needs Session ARC100
- What’s next for architects and IT professionals Spotlight SPTL202
- Hardware-verse: Experience real-time visual inspection at the edge Interactive Demo HWV-101
- Hardware-verse: Address sovereignty needs with air-gapped private cloud—Interactive Demo HWV-102
- Hardware-verse: Supercharge your generative AI model development with Cloud TPUs Interactive Demo HWV-103
Retrouvez également nos guides pratiques “pas à pas” sur la configuration des GPU :

