클러스터링된 테이블 관리
이 문서에서는 BigQuery의 클러스터링된 테이블에 대한 정보를 가져오고 액세스를 제어하는 방법을 설명합니다.
자세한 내용은 다음을 참조하세요.
- BigQuery의 클러스터링된 테이블 지원에 대해 알아보려면 클러스터링된 테이블 소개를 참고하세요.
- 클러스터링된 테이블을 만드는 방법은 클러스터링된 테이블 만들기를 참고하세요.
시작하기 전에
테이블에 대한 정보를 가져오려면 bigquery.tables.get 권한이 있어야 합니다. 다음과 같은 사전 정의된 IAM 역할에는 bigquery.tables.get 권한이 포함되어 있습니다.
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
또한 사용자에게 bigquery.datasets.create 권한이 있으면 사용자가 데이터 세트를 만들 때 이에 대한 bigquery.dataOwner 액세스 권한이 부여됩니다.
bigquery.dataOwner 액세스 권한이 있는 사용자는 데이터 세트에서 테이블 정보를 가져올 수 있습니다.
BigQuery의 IAM 역할과 권한에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
클러스터링된 테이블에 대한 액세스 제어
테이블 및 뷰에 대한 액세스를 구성하려면 허용되는 리소스 범위 순서(가장 큰 크기부터 가장 작은 크기 순서)대로 나열된 다음 수준의 항목에 IAM 역할을 부여하면 됩니다.
- Google Cloud 리소스 계층 구조의 상위 수준(예: 프로젝트, 폴더 또는 조직 수준)
- 데이터 세트 수준
- 테이블 또는 보기 수준
다음 방법을 사용해서 테이블 내에서 데이터 액세스를 제한할 수도 있습니다.
IAM으로 보호되는 모든 리소스에 대한 액세스 권한은 적층식입니다. 예를 들어 항목이 프로젝트와 같은 높은 수준에서 액세스할 수 없는 경우 데이터 세트 수준에서 항목에 액세스 권한을 부여하면 해당 항목에서 데이터 세트의 테이블과 뷰에 액세스할 수 있습니다. 마찬가지로, 항목이 높은 수준 또는 데이터 세트 수준에서 액세스할 수 없는 경우 테이블 또는 뷰 수준에서 항목에 액세스 권한을 부여할 수 있습니다.
프로젝트, 폴더 또는 조직 수준과 같이 Google Cloud리소스 계층 구조의 상위 수준에서 IAM 역할을 부여하면 포괄적인 리소스 집합에 대한 액세스 권한이 항목에 부여됩니다. 예를 들어 프로젝트 수준에서 항목에 역할을 부여하면 프로젝트의 모든 데이터 세트에 적용되는 권한이 항목에 부여됩니다.
데이터 세트 수준에서 역할을 부여하면 항목이 상위 수준에서 액세스할 수 없는 경우에도 특정 데이터 세트의 테이블과 뷰에서 항목이 수행할 수 있는 작업이 지정됩니다. 데이터 세트 수준의 액세스 권한 제어 구성에 대한 자세한 내용은 데이터 세트에 대한 액세스 제어를 참조하세요.
테이블 또는 뷰 수준에서 역할을 부여하면 항목이 상위 수준에서 액세스할 수 없는 경우에도 테이블과 뷰에서 항목이 수행할 수 있는 작업이 지정됩니다. 테이블 수준의 액세스 권한 제어 구성에 대한 자세한 내용은 테이블 및 뷰에 대한 액세스 제어를 참조하세요.
IAM 커스텀 역할을 만들 수도 있습니다. 커스텀 역할을 만들 경우 항목이 수행하도록 하려는 특정 작업에 따라 권한을 부여합니다.
IAM으로 보호되는 리소스에는 '거부' 권한을 설정할 수 없습니다.
역할 및 권한에 대한 자세한 내용은 IAM 문서의 역할 이해 및 BigQuery IAM 역할 및 권한을 참조하세요.
클러스터링된 테이블 정보 가져오기
다음 옵션 중 하나를 선택합니다.
콘솔
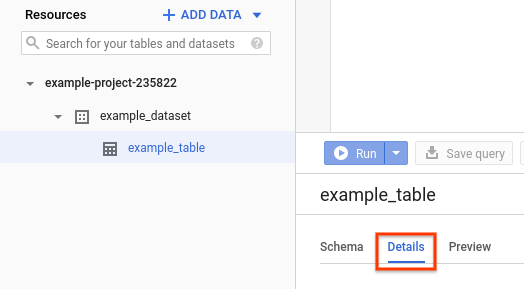
Google Cloud 콘솔에서 리소스 창으로 이동합니다.
데이터 세트 이름을 클릭하여 펼친 다음 확인하려는 테이블 이름을 클릭합니다.
세부정보를 클릭합니다.
클러스터링 열을 포함한 테이블의 세부정보가 표시됩니다.
SQL
클러스터링된 테이블의 경우 INFORMATION_SCHEMA.COLUMNS 뷰에서 CLUSTERING_ORDINAL_POSITION 열을 쿼리하여 테이블의 클러스터링 열에서 열의 1부터 시작하는 오프셋을 찾을 수 있습니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
클러스터링 서수 위치는 column1은 1, column2는 2입니다.
INFORMATION_SCHEMA의 TABLES, TABLE_OPTIONS, COLUMNS, COLUMN_FIELD_PATH 뷰를 통해 더 많은 테이블 메타데이터를 사용할 수 있습니다.
bq
bq show 명령어를 실행하여 모든 테이블 정보를 표시합니다. 테이블 스키마 정보만 표시하려면 --schema 플래그를 사용합니다. --format 플래그를 사용하면 출력을 제어할 수 있습니다.
기본 프로젝트가 아닌 다른 프로젝트의 테이블에 대한 정보를 가져오려면 프로젝트 ID를 project_id:dataset 형식으로 데이터 세트에 추가합니다.
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDDATASET: 데이터 세트의 이름TABLE: 테이블의 이름
예:
다음 명령어를 입력하여 mydataset에 있는 myclusteredtable과 관련된 모든 정보를 표시합니다. mydataset)에 대한 모든 정보를 표시합니다.
bq show --format=prettyjson mydataset.myclusteredtable
출력은 다음과 같이 표시됩니다.
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
bigquery.tables.get 메서드를 호출하고 관련 매개변수를 모두 제공합니다.
데이터 세트의 클러스터링된 테이블 나열
클러스터링된 테이블을 나열하는 데 필요한 권한과 테이블을 나열하는 단계는 표준 테이블과 동일합니다. 자세한 내용은 데이터 세트의 테이블 나열을 참고하세요.
클러스터링 사양 수정
테이블의 클러스터링 사양을 변경 또는 삭제하거나 클러스터링된 테이블의 클러스터링된 열 집합을 변경할 수 있습니다. 클러스터링된 열 집합을 업데이트하는 방법은 연속 스트리밍 삽입을 사용하는 테이블에 유용합니다. 이러한 테이블은 다른 방법으로는 쉽게 바꿀 수 없기 때문입니다.
파티션을 나누지 않았거나 파티션을 나눈 테이블에 새 클러스터링 사양을 적용하려면 다음 단계를 수행합니다.
bq 도구에서 새 클러스터링과 일치하도록 테이블의 클러스터링 사양을 업데이트합니다.
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
다음을 바꿉니다.
CLUSTER_COLUMN: 클러스터링된 열(예:mycolumn)DATASET: 테이블이 포함된 데이터 세트의 이름(예:mydataset)ORIGINAL_TABLE: 원본 테이블의 이름(예:mytable).
tables.update또는tables.patchAPI 메서드를 호출하여 클러스터링 사양을 수정할 수도 있습니다.새 클러스터링 사양에 따라 모든 행을 클러스터링하려면 다음
UPDATE문을 실행합니다.UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
다음 단계
- 클러스터링된 테이블 쿼리에 대한 자세한 내용은 클러스터링된 테이블 쿼리를 참고하세요.
- BigQuery의 파티션을 나눈 테이블 지원 개요는 파티션을 나눈 테이블 소개를 참조하세요.
- 파티션을 나눈 테이블을 만드는 방법은 파티션을 나눈 테이블 만들기를 참고하세요.