text-bison モデルと ML.GENERATE_TEXT 関数を使用してテキストを生成する
このチュートリアルでは、text-bison@002 大規模言語モデルに基づいてリモートモデルを作成する方法を説明します。このモデルを ML.GENERATE_TEXT 関数と組み合わせて使用して、複数のテキスト生成タスクを実行します。このチュートリアルでは、bigquery-public-data.imdb.reviews 一般公開テーブルを使用します。
必要な権限
- データセットを作成するには、
bigquery.datasets.createIdentity and Access Management(IAM)権限が必要です。 接続リソースを作成するには、次の IAM 権限が必要です。
bigquery.connections.createbigquery.connections.get
接続のサービス アカウントに権限を付与するには、次の権限が必要です。
resourcemanager.projects.setIamPolicy
モデルを作成するには、次の権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
推論を実行するには、次の権限が必要です。
bigquery.models.getDatabigquery.jobs.create
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
- BigQuery ML: You incur costs for the data that you process in BigQuery.
- Vertex AI: You incur costs for calls to the Vertex AI service that's represented by the remote model.
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
BigQuery の料金の詳細については、BigQuery ドキュメントの BigQuery の料金をご覧ください。
Vertex AI の料金の詳細については、Vertex AI の料金のページをご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Connection, and Vertex AI APIs.
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
![[データセットを作成] のメニュー オプション。](https://cloud.google.com/static/bigquery/images/create-dataset.png?authuser=0&hl=ja)
[データセットを作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
接続を作成する
クラウド リソース接続を作成し、接続のサービス アカウントを取得します。前の手順で作成したデータセットと同じロケーションに接続を作成します。
次のオプションのいずれかを選択します。
コンソール
[BigQuery] ページに移動します。
[エクスプローラ] ペインで、 [データを追加] をクリックします。
[データを追加] ダイアログが開きます。
[フィルタ] ペインの [データソースの種類] セクションで、[データベース] を選択します。
または、[データソースの検索] フィールドに「
Vertex AI」と入力します。[注目のデータソース] セクションで、[Vertex AI] をクリックします。
[Vertex AI Models: BigQuery Federation] ソリューション カードをクリックします。
[接続タイプ] リストで、[Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)] を選択します。
[接続 ID] フィールドに接続の名前を入力します。
[接続を作成] をクリックします。
[接続へ移動] をクリックします。
[接続情報] ペインで、次の手順で使用するサービス アカウント ID をコピーします。
bq
コマンドライン環境で接続を作成します。
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
--project_idパラメータは、デフォルト プロジェクトをオーバーライドします。次のように置き換えます。
REGION: 接続のリージョンPROJECT_ID: 実際の Google Cloud プロジェクト IDCONNECTION_ID: 接続の ID
接続リソースを作成すると、BigQuery は、一意のシステム サービス アカウントを作成し、それを接続に関連付けます。
トラブルシューティング: 次の接続エラーが発生した場合は、Google Cloud SDK を更新します。
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
後の手順で使用するため、サービス アカウント ID を取得してコピーします。
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
出力は次のようになります。
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Terraform
google_bigquery_connection リソースを使用します。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証を設定するをご覧ください。
次の例では、US リージョンに my_cloud_resource_connection という名前の Cloud リソース接続を作成します。
Google Cloud プロジェクトで Terraform 構成を適用するには、次のセクションの手順を完了します。
Cloud Shell を準備する
- Cloud Shell を起動します。
-
Terraform 構成を適用するデフォルトの Google Cloud プロジェクトを設定します。
このコマンドは、プロジェクトごとに 1 回だけ実行する必要があります。これは任意のディレクトリで実行できます。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 構成ファイルに明示的な値を設定すると、環境変数がオーバーライドされます。
ディレクトリを準備する
Terraform 構成ファイルには独自のディレクトリ(ルート モジュールとも呼ばれます)が必要です。
-
Cloud Shell で、ディレクトリを作成し、そのディレクトリ内に新しいファイルを作成します。ファイルの拡張子は
.tfにする必要があります(例:main.tf)。このチュートリアルでは、このファイルをmain.tfとします。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
チュートリアルを使用している場合は、各セクションまたはステップのサンプルコードをコピーできます。
新しく作成した
main.tfにサンプルコードをコピーします。必要に応じて、GitHub からコードをコピーします。Terraform スニペットがエンドツーエンドのソリューションの一部である場合は、この方法をおすすめします。
- 環境に適用するサンプル パラメータを確認し、変更します。
- 変更を保存します。
-
Terraform を初期化します。これは、ディレクトリごとに 1 回だけ行います。
terraform init
最新バージョンの Google プロバイダを使用する場合は、
-upgradeオプションを使用します。terraform init -upgrade
変更を適用する
-
構成を確認して、Terraform が作成または更新するリソースが想定どおりであることを確認します。
terraform plan
必要に応じて構成を修正します。
-
次のコマンドを実行します。プロンプトで「
yes」と入力して、Terraform 構成を適用します。terraform apply
Terraform に「Apply complete!」というメッセージが表示されるまで待ちます。
- Google Cloud プロジェクトを開いて結果を表示します。Google Cloud コンソールの UI でリソースに移動して、Terraform によって作成または更新されたことを確認します。
接続のサービス アカウントに権限を付与する
接続のサービス アカウントに Vertex AI ユーザーロールを付与します。このロールは、始める前にで作成または選択したプロジェクトで付与する必要があります。別のプロジェクトでロールを付与すると、「bqcx-1234567890-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com does not have the permission to access resource」というエラーが発生します。
ロールを付与する手順は次のとおりです。
[IAM と管理] ページに移動します。
[アクセス権を付与] をクリックします。
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービス アカウント ID を入力します。
[ロールを選択] フィールドで、[Vertex AI]、[Vertex AI ユーザーロール] の順に選択します。
[保存] をクリックします。
リモートモデルを作成する
ホストされる Vertex AI 大規模言語モデル(LLM)に相当するリモートモデルを作成します。
SQL
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで、次のステートメントを実行します。
CREATE OR REPLACE MODEL `bqml_tutorial.llm_model` REMOTE WITH CONNECTION `LOCATION.CONNECTION_ID` OPTIONS (ENDPOINT = 'text-bison@002');
次のように置き換えます。
LOCATION: 接続のロケーションCONNECTION_ID: BigQuery 接続の IDGoogle Cloud コンソールで接続の詳細を表示する場合、これは [接続 ID] に表示される完全修飾接続 ID の最後のセクションの値です。例:
projects/myproject/locations/connection_location/connections/myconnection
クエリが完了するまでに数秒かかります。完了後、モデル
llm_modelが [エクスプローラ] ペインのbqml_tutorialデータセットに表示されます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果はありません。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
キーワード抽出を行う
リモートモデルと ML.GENERATE_TEXT 関数を使用して、IMDB 映画レビューに対してキーワード抽出を行います。
SQL
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力して、5 つの映画レビューでキーワード抽出を行います。
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
出力は次のようになります(わかりやすくするために、生成されていない列は省略しています)。
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " Keywords:\n- British Airways\n- | {"blocked":false,"categories": | | Extract the key words from | | | acting\n- story\n- kid\n- switch off" | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | | "Finance","Health","Insult", | | see this on the British | | | | "Profanity","Religion & Belief", | | Airways plane. It was | | | | "Sexual","Toxic"] | | terribly bad acting and | | | | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | " - Family movie\n- ITV station\n- THE | {"blocked":false,"categories": | | Extract the key words from | | | REAL HOWARD SPITZ\n- Roald Dahl\n- | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | DOCTOR WHO\n- Pulp fiction\n- Child | "Health","Illicit Drugs","Insult", | | a family movie that was | | | abuse\n- KINDERGARTEN COP\n- PC\n- | "Legal","Profanity","Public Safety", | | broadcast on my local | | | Children's author\n- Vadim Jean\n- | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | Haphazard\n- Kelsey Grammar\n- | "safetyRatings":[{"category": | | couple of nights ago. | | | Dead pan\n- Ridiculous camera angles" | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+結果には次の列が含まれます。
generated_text: 生成されたテキスト。safety_attributes: 安全属性と、ブロック カテゴリのいずれかに応じたコンテンツがブロックされているかどうかに関する情報。安全性属性の詳細については、Vertex PaLM API をご覧ください。ml_generate_text_status: 対応する行の API レスポンス ステータス。オペレーションが成功した場合、この値は空になります。prompt: 感情分析に使用されるプロンプト。bigquery-public-data.imdb.reviewsテーブルのすべての列。
省略可: 前の手順で行ったように、関数から返された JSON を手動で解析するのではなく、
flatten_json_output引数を使用して、生成されたテキストと安全性属性を別々の列に返します。クエリエディタで、次のステートメントを実行します。
SELECT * FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT('Extract the key words from the text below: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens, TRUE AS flatten_json_output));
出力は次のようになります(わかりやすくするために、生成されていない列は省略しています)。
+----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | ml_generate_text_llm_result | ml_generate_text_rai_result | ml_generate_text_status | prompt | ... | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | Keywords: | {"blocked":false,"categories": | | Extract the key words from | | | - British Airways | ["Death, Harm & Tragedy","Derogatory", | | the text below: I had to | | | - acting | "Finance","Health","Insult", | | see this on the British | | | - story | "Profanity","Religion & Belief", | | Airways plane. It was | | | - kid | "Sexual","Toxic"] | | terribly bad acting and | | | - switch off | "safetyRatings":[{"category": | | a dumb story. Not even | | | | "Dangerous Content","probabilityScore"... | | a kid would enjoy this... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+ | - Family movie | {"blocked":false,"categories": | | Extract the key words from | | | - ITV station | ["Death, Harm & Tragedy","Derogatory", | | the text below: This is | | | - THE REAL HOWARD SPITZ | "Health","Illicit Drugs","Insult", | | a family movie that was | | | - Roald Dahl | "Legal","Profanity","Public Safety", | | broadcast on my local | | | - DOCTOR WHO | "Sexual","Toxic","Violent"], | | ITV station at 1.00 am a | | | - Pulp Fiction | "safetyRatings":[{"category": | | couple of nights ago. | | | - ... | "Dangerous Content","probabilityScore"... | | This might be a strange... | | +----------------------------------------+---------------------------------------------+-------------------------+----------------------------+-----+結果には次の列が含まれます。
ml_generate_text_llm_result: 生成されたテキスト。ml_generate_text_rai_result: 安全属性と、ブロック カテゴリのいずれかに応じたコンテンツがブロックされているかどうかに関する情報。安全性属性の詳細については、Vertex PaLM API をご覧ください。ml_generate_text_status: 対応する行の API レスポンス ステータス。オペレーションが成功した場合、この値は空になります。prompt: キーワード抽出に使用されるプロンプト。bigquery-public-data.imdb.reviewsテーブルのすべての列。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
predict 関数を使用して、リモートモデルを実行します。
次のような結果になります: 
感情分析を行う
リモートモデルと ML.GENERATE_TEXT 関数を使用して、IMDB 映画レビューに対して感情分析を行います。
SQL
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタで次のステートメントを実行して、5 つの映画レビューの感情分析を行います。
SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result) FROM ML.GENERATE_TEXT( MODEL `bqml_tutorial.llm_model`, ( SELECT CONCAT( 'perform sentiment analysis on the following text, return one the following categories: positive, negative: ', review) AS prompt, * FROM `bigquery-public-data.imdb.reviews` LIMIT 5 ), STRUCT( 0.2 AS temperature, 100 AS max_output_tokens));
出力は次のようになります(わかりやすくするために、生成されていない列は省略しています)。
+----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | generated_text | safety_attributes | ml_generate_text_status | prompt | ... | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Finance","Health","Insult", | | return one the following | | | | "Profanity","Religion & Belief", | | categories: positive, | | | | "Sexual","Toxic"] | | negative: I had to see | | | | "safetyRatings":[{"category": | | this on the British | | | | "Dangerous Content","probabilityScore"... | | Airways plane. It was... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+ | "negative" | {"blocked":false,"categories": | | perform sentiment analysis | | | | ["Death, Harm & Tragedy","Derogatory", | | on the following text, | | | | "Health","Illicit Drugs","Insult", | | return one the following | | | | "Legal","Profanity","Public Safety", | | categories: positive, | | | | "Sexual","Toxic","Violent"], | | negative: This is a family | | | | "safetyRatings":[{"category": | | movie that was broadcast | | | | "Dangerous Content","probabilityScore"... | | on my local ITV station... | | +----------------+---------------------------------------------+-------------------------+----------------------------+-----+結果には、キーワード抽出を行うで説明したものと同じ列が含まれます。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
predict 関数を使用して、リモートモデルを実行します。
次のような結果になります: 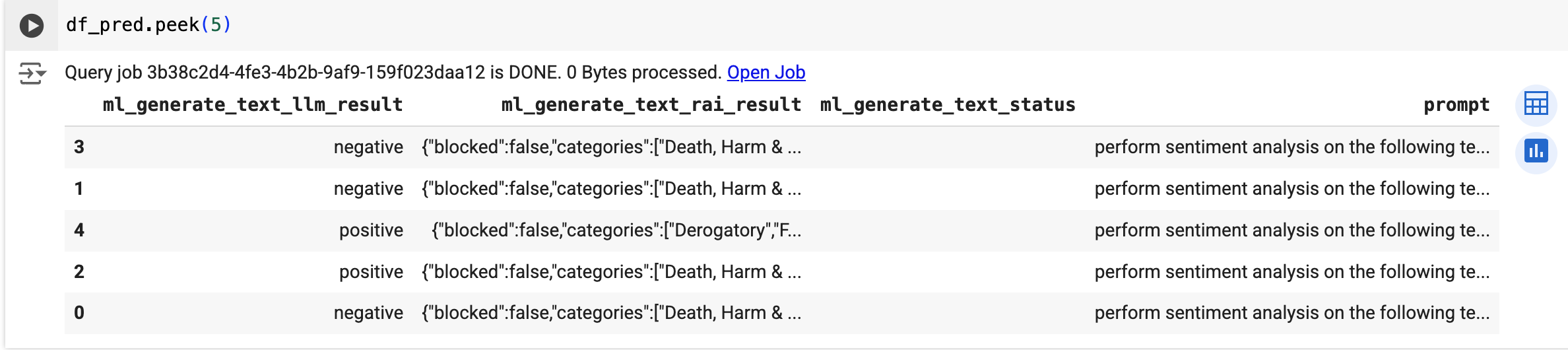
クリーンアップ
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.