Before you can protect an SAP HANA database, you must onboard the Compute Engine instance.
Discover and protect the SAP HANA database application
- LVM backups fail for any third party backup backint setup
- Recovery is compromised due to break in the recovery chain
- A Full+Incremental backup can get orphan incrementals causing recovery issues.
Use the following instructions to discover and protect SAP HANA scale-out instances:
Select Add Application from the management console's App Manager > Applications page.
Select SAP HANA in the Add Application wizard.
Follow the wizard:
Select the database to manage from the Select section.
Apply the policy template and the resource profile in the Manage section, you created these in Define policy templates and resource profiles.
Click Application Settings in the Configure section.
Select the Backup Capture Method from the Application Settings window. The method is based on your needs and the information in Protect the SAP production environment against data loss, errors, and corruption.
In the Application Settings tab, you can change application-specific settings. Be sure to address the following:
HANA DB user store key: This is the SAP HANA hdbuserstore key for the system database created earlier. This field is mandatory.
Percentage of reserve space in volume group: This is needed for volume level backup to determine the required amount of temporary free space in LVM volume group for snapshots. The recommended value is 20%.
Backup capture method:
Use Persistent Disk Snapshot: This is the standard Persistent Disk snapshot used by Compute Engine. Select this for HANA databases running in a Compute Engine instance. If you can use this method, see .
Use volume level backup: Use volume level LVM snapshots with CBT on Linux to a block-based staging disk. This option uses the SAP HANA savepoint API to enable you to create incremental-forever backups. This requires the HANA database data and log volume to be LVM-managed. If you are using NFS protocol staging disks, then you cannot use volume-level backups.
Use Full+Incremental backup: This is the older file-based backup and recovery. This "file dump" method does not support creation of virtual databases. You can select this for block and for NFS staging disks. This method only supports older Backint backup and physical recovery.
Retention of production DB logs in hours: At the end of every log backup, the log purge will run and delete all the logs older than the number of hours specified here. For example if the number of hours specified is 4 hours then all the logs older than ((the start time of the log backup) - (4 hours)) will be purged. The default value is 2 hours.
Retention of production catalog in days: This is the retention of catalog metadata in days. The HANA catalog metadata (m_backup_catalog table) will be purged of logs older than the specified number of days. For example if the number of days specified is 14 days then data from HANA catalog will be purged older than ((the current day) - (14 days)). The default value is 7 days.
Click Save > Next, then click Finish.
You can see the database in the App Manager Applications list with a green shield indicating that the backup plan has been applied.
Back up HANA 1+n and HANA scale-out databases
This section includes information about protecting HANA 1+n and HANA scale-out.
Protect HANA 1+n
To protect a HANA 1+n replication cluster as a single application, after
application discovery the application has the cluster host as
sid name_cluster. For example, if sr1 is the HANA instance, then the
application name is sr1 and the hostname is sr1_cluster in the
App Manager Applications list.
The HANA log backup destination must be shared between two nodes. When failover occurs, the database and log backup automatically fails over to the current primary, and log backups are performed from the current primary, capturing the last logs from the old primary as well as new logs from the new primary. Follow the preparation steps in Prepare your SAP HANA databases for protection.
HANA 1+n is always discovered as cluster application containing all node details in the metadata. After application discovery, the application has the cluster host as (HANA sid name)cluster(site id)_(HANA hardware id). For example, if sr1 is the HANA instance, then the application name is sr1 and the hostname is sr1cluster<…> in the App Manager Applications list.
It is a good idea to run a force discovery after any changes to cluster node configuration—such as after adding or deleting a node from the cluster. If a node is removed or added after discovery and protection, the configuration is not updated automatically in Backup and DR metadata, and may cause backup issues.
Prerequisites for protecting SAP HANA 1+n instances and databases
Before protecting SAP HANA instances, ensure the following:
- All SAP HANA servers or Compute Engine instances of the SAP HANA cluster must have been onboarded to Backup and DR Service.
- All SAP HANA servers or Compute Engine instances of the SAP HANA cluster must have the Backup and DR agent installed.
All SAP HANA servers or Compute Engine instances of the SAP HANA cluster must have a secret applied under App Manage > Manage > Host > Backup and DR Agent Settings > Secret.
If hosts have virtual IPs configured, add only the virtual IP and hostname of the host during discovery.
The Backup and DR agent must be installed on all nodes.
Ports need to be opened on the hosts to allow communication on port 5106. This requires an ingress firewall rule where the backup/recovery appliance is the source, the host running the agent is the target and the target port is 5106. There is no need to add port 5106 to the default ingress rule created for the appliance, as this specifies the appliance as the target.
HANA log backup location must be set on shared—NFS.
Protect HANA scale-out
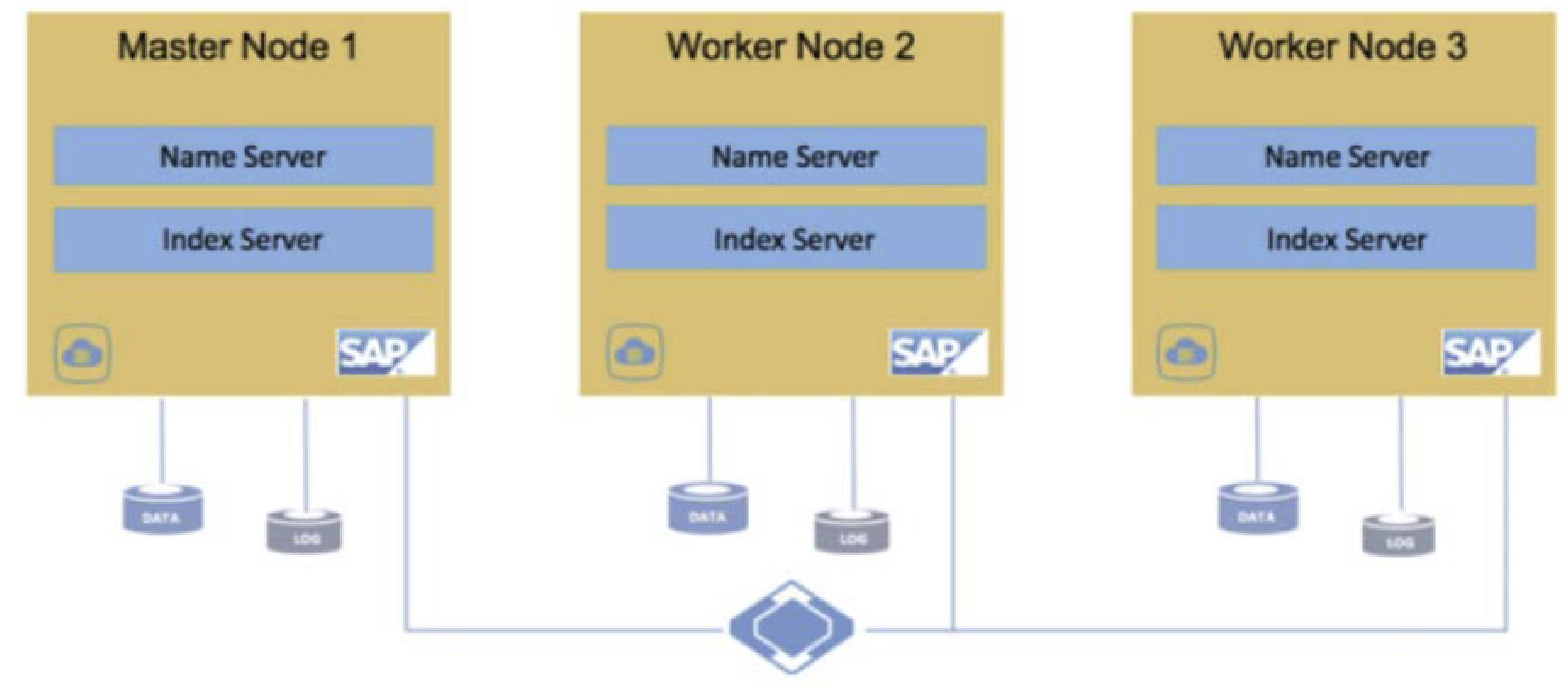
Prerequisites for protecting SAP HANA scale-out
Before protecting SAP HANA scale-out, be sure that the following is complete:
- If hosts have virtual IPs configured, add only the virtual IP and the associated hostname of the host during discovery.
- The Backup and DR agent must be installed on all nodes.
- Ports need to be opened on the hosts to allow communication on port 5106. This requires an ingress firewall rule where the backup/recovery appliance is the source, the host running the agent is the target and the target port is 5106. Also, there is no need to add port 5106 to the default ingress rule created for the appliance, as this specifies the appliance as the target.
- For backint file based—Full+Incremental—backup, the HANA log backup location must be set to shared—NFS. See Add the host to the management console.
For storage snapshot protection
- Data and log volume are non-shared across all nodes
- Data and log volumes are logical volume manager managed
- Ensure mnt000* directories exist on the local mount points to identify the primary and secondary nodes
Follow the setup procedures in Prepare your SAP HANA databases for protection.
Backup and DR Service documentation for SAP HANA scale-out
This page is one in a series of pages specific to protecting and recovering SAP HANA scale-out instances with Backup and DR Service. You can find additional information in the following pages:
- Backup and DR for SAP HANA scale-out
- Prepare SAP HANA scale-out instances for backup
- Add an SAP HANA scale-out host, and discover and protect its databases
- Configure staging disk format and backup method for SAP HANA scale-out
- Set application details and settings for SAP HANA scale-out instances
- Back up HANA 1+n and HANA scale-out databases
- Restore and recover SAP HANA scale-out instances
- Mount an SAP HANA scale-out backup as a standard mount
- Mount an SAP HANA scale-out backup as a virtual database
- Mount and migrate an SAP HANA scale-out backup for instant recovery to any target