Questo documento illustra come configurare il logging e il monitoraggio per i componenti di sistema in Google Distributed Cloud (solo software) per VMware.
Per impostazione predefinita, Cloud Logging, Cloud Monitoring e Google Cloud Managed Service per Prometheus sono abilitati.
Per ulteriori informazioni sulle opzioni, consulta la Panoramica di logging e monitoraggio.
Risorse monitorate
Le risorse monitorate sono il modo in cui Google rappresenta risorse come cluster, nodi, pod e contenitori. Per scoprire di più, consulta la documentazione relativa ai tipi di risorse monitorate di Cloud Monitoring.
Per eseguire query su log e metriche, devi conoscere almeno questi etichette delle risorse:
project_id: ID progetto del progetto di monitoraggio-logging del cluster. Hai fornito questo valore nel campostackdriver.projectIDdel file di configurazione del cluster.location: una Google Cloud regione in cui vuoi instradare e archiviare le tue metriche di monitoraggio di Cloud. Specifica la regione durante l'installazione nel campostackdriver.clusterLocationdel file di configurazione del cluster. Ti consigliamo di scegliere una regione vicino al tuo data center on-premise.Devi specificare il routing e la posizione di archiviazione dei log di Cloud Logging nella configurazione del router dei log. Per ulteriori informazioni sul routing dei log, consulta la panoramica su routing e archiviazione.
cluster_name: il nome del cluster che hai scelto quando lo hai creato.Puoi recuperare il valore
cluster_nameper il cluster di amministrazione o di utenti esaminando la risorsa personalizzata Stackdriver:kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
dove
CLUSTER_KUBECONFIGè il percorso del file kubeconfig del cluster di amministrazione o del cluster utente per il quale è richiesto il nome del cluster.
Routing di log e metriche
Il forwarder dei log di Stackdriver (stackdriver-log-forwarder) invia i log da ogni macchina node a Cloud Logging. Analogamente, l'agente delle metriche GKE
(gke-metrics-agent) invia le metriche da ogni macchina del nodo a
Cloud Monitoring. Prima che i log e le metriche vengano inviati, l'operatore Stackdriver (stackdriver-operator) associa il valore del campo clusterLocation nella risorsa personalizzata stackdriver a ogni voce di log e metrica prima che vengano inoltrati a Google Cloud. Inoltre, i log e le metriche sono associati al Google Cloud project
specificato nella specifica della risorsa personalizzata stackdriver (spec.projectID). La risorsastackdriver recupera i valori per i campi clusterLocation e projectID
dai campi
stackdriver.clusterLocation
e
stackdriver.projectID
nella sezione clusterOperations della risorsa Cluster al momento della creazione del cluster.
Tutte le metriche e le voci di log inviate dagli agenti Stackdriver vengono inoltrate a un endpoint di importazione globale. Da qui, i dati vengono inoltrati all'endpoint Google Cloud regionale Google Cloud più vicino raggiungibile per garantire l'affidabilità del trasporto dei dati.
Una volta che l'endpoint globale riceve la metrica o la voce di log, ciò che accade dipende dal servizio:
Come viene configurato il routing dei log: quando l'endpoint di logging riceve un messaggio di log, Cloud Logging lo passa al router di log. I sink e i filtri nella configurazione del router dei log determinano il modo in cui instradare il messaggio. Puoi instradare le voci di log a destinazioni come i bucket di logging regionali, che archiviano la voce di log, o a Pub/Sub. Per ulteriori informazioni su come funziona il routing dei log e su come configurarlo, consulta la panoramica su routing e archiviazione.
Né il campo
clusterLocationnella risorsa personalizzatastackdriverné il campoclusterOperations.locationnella specifica del cluster vengono presi in considerazione in questa procedura di instradamento. Per i log,clusterLocationviene utilizzato per etichettare solo le voci del log, il che può essere utile per applicare i filtri in Esplora log.Come viene configurato il routing delle metriche: quando l'endpoint delle metriche riceve una voce metrica, Cloud Monitoring la inoltra automaticamente alla posizione specificata dalla metrica. La posizione nella metrica proviene dal campo
clusterLocationnella risorsa personalizzatastackdriver.Pianifica la configurazione: quando configuri Cloud Logging e Cloud Monitoring, configura il router dei log e specifica un
clusterLocationappropriato con le località che supportano al meglio le tue esigenze. Ad esempio, se vuoi che i log e le metriche vengano inviati alla stessa posizione, impostaclusterLocationsulla stessa regione utilizzata da Log Router per il tuo progetto. Google Cloud Google CloudAggiorna la configurazione in base alle esigenze: puoi apportare modifiche in qualsiasi momento alle impostazioni di destinazione per i log e le metriche in base ai requisiti aziendali, come i piani di ripristino dei disastri. Le modifiche alla configurazione di Log Router nel campo Google Cloud e
clusterLocationdella risorsa personalizzatastackdrivervengono applicate rapidamente.
Utilizzo di Cloud Logging
Non devi fare nulla per attivare Cloud Logging per un cluster.
Tuttavia, devi specificare il Google Cloud progetto in cui vuoi visualizzare i log. Nel
file di configurazione del cluster, specifica il Google Cloud progetto nella
sezione stackdriver.
Puoi accedere ai log utilizzando la funzionalità Esplora log nella Google Cloud console. Ad esempio, per accedere ai log di un contenitore:
- Apri Esplora log nella console Google Cloud del tuo progetto.
- Per trovare i log di un contenitore:
- Fai clic sulla casella del menu a discesa del catalogo dei log in alto a sinistra e seleziona Container Kubernetes.
- Seleziona il nome del cluster, quindi lo spazio dei nomi e infine un contenitore dalla gerarchia.
Visualizzazione dei log per i controller nel cluster di bootstrap
-
Nella Google Cloud console, vai alla pagina Esplora log:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Logging.
Per visualizzare tutti i log dei controller nel cluster di bootstrap, esegui la seguente query nell'editor di query:
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
Per visualizzare i log di un pod specifico, modifica la query in modo da includere il nome del pod:
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Utilizzo di Cloud Monitoring
Non devi fare nulla per attivare il monitoraggio di Cloud per un cluster.
Tuttavia, devi specificare il Google Cloud progetto in cui vuoi visualizzare le metriche.
Nel file di configurazione del cluster, specifica il Google Cloud progetto nella sezione stackdriver.
Puoi scegliere tra oltre 1500 metriche utilizzando Metrics Explorer. Per accedere a Metrics Explorer:
Nella Google Cloud console, seleziona Monitoraggio o utilizza il pulsante seguente:
Seleziona Risorse > Metrics Explorer.
Puoi anche visualizzare le metriche nelle dashboard della Google Cloud console. Per informazioni sulla creazione di dashboard e sulla visualizzazione delle metriche, consulta Creare dashboard.
Visualizzazione dei dati di monitoraggio a livello di parco risorse
Per una visione complessiva dell'utilizzo delle risorse del tuo parco risorse utilizzando i dati di Cloud Monitoring, inclusi i cluster Google Distributed Cloud, puoi utilizzare la panoramica di Google Kubernetes Engine nella Google Cloud console. Per scoprire di più, consulta Gestire i cluster dalla Google Cloud console.
Limiti di quota predefiniti di Cloud Monitoring
Il monitoraggio di Google Distributed Cloud ha un limite predefinito di 6000 chiamate API al minuto per ogni progetto. Se superi questo limite, le metriche potrebbero non essere visualizzate. Se hai bisogno di un limite di monitoraggio superiore, richiedilo tramite la Google Cloud console.
Utilizzo di Managed Service per Prometheus
Google Cloud Managed Service per Prometheus fa parte di Cloud Monitoring ed è disponibile per impostazione predefinita. I vantaggi di Managed Service per Prometheus includono quanto segue:
Puoi continuare a utilizzare il monitoraggio basato su Prometheus esistente senza alterare gli avvisi e le dashboard di Grafana.
Se utilizzi sia GKE sia Google Distributed Cloud, puoi utilizzare lo stesso PromQL per le metriche su tutti i tuoi cluster. Puoi anche utilizzare la scheda PromQL in Metrics Explorer nella Google Cloud console.
Abilitazione e disattivazione di Managed Service per Prometheus
A partire dalla release 1.30.0-gke.1930 di Google Distributed Cloud,
Managed Service per Prometheus è sempre abilitato. Nelle versioni precedenti, puoi modificare la risorsa Stackdriver stackdriver per attivare o disattivare Managed Service per Prometheus. Per disattivare Managed Service per Prometheus per le versioni del cluster precedenti alla 1.30.0-gke.1930, imposta spec.featureGates.enableGMPForSystemMetrics nella risorsa stackdriver su false.
Visualizzazione dei dati delle metriche
Quando Managed Service per Prometheus è abilitato, le metriche per i seguenti componenti hanno un formato diverso per la modalità di archiviazione ed esecuzione di query in Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet e cadvisor
- kube-state-metrics
- node-exporter
Nel nuovo formato, puoi eseguire query sulle metriche precedenti utilizzando PromQL o Monitoring Query Language (MQL).
Esempio di query PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Per utilizzare MQL, imposta la risorsa monitorata su prometheus_target e aggiungi il tipo Prometheus come suffisso alla metrica.
Esempio di MQL:
fetch prometheus_target | metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram' | align delta(5m) | every 5m | group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Configurazione delle dashboard di Grafana con Managed Service per Prometheus
Per utilizzare Grafana con i dati delle metriche di Managed Service per Prometheus, segui la procedura descritta in Eseguire query utilizzando Grafana per autenticare e configurare un'origine dati Grafana in modo da eseguire query sui dati di Managed Service per Prometheus.
Un insieme di dashboard Grafana di esempio è fornito nel repository anthos-samples su GitHub. Per installare le dashboard di esempio:
Scarica i file
.jsondi esempio:git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Se l'origine dati Grafana è stata creata con un nome diverso da
Managed Service for Prometheus, modifica il campodatasourcein tutti i file.json:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Sostituisci [DATASOURCE_NAME] con il nome dell'origine dati in Grafana che rimanda al servizio Prometheus
frontend.Accedi all'interfaccia utente di Grafana dal browser e seleziona + Importa nel menu Dashboard.
Carica il file
.jsono copia e incolla i contenuti del file e seleziona Carica. Una volta caricati i contenuti del file, seleziona Importa. Facoltativamente, puoi anche modificare il nome e l'UID della dashboard prima dell'importazione.
La dashboard importata dovrebbe caricarsi correttamente se Google Distributed Cloud e l'origine dati sono configurati correttamente. Ad esempio, lo screenshot seguente mostra la dashboard configurata da
cluster-capacity.json.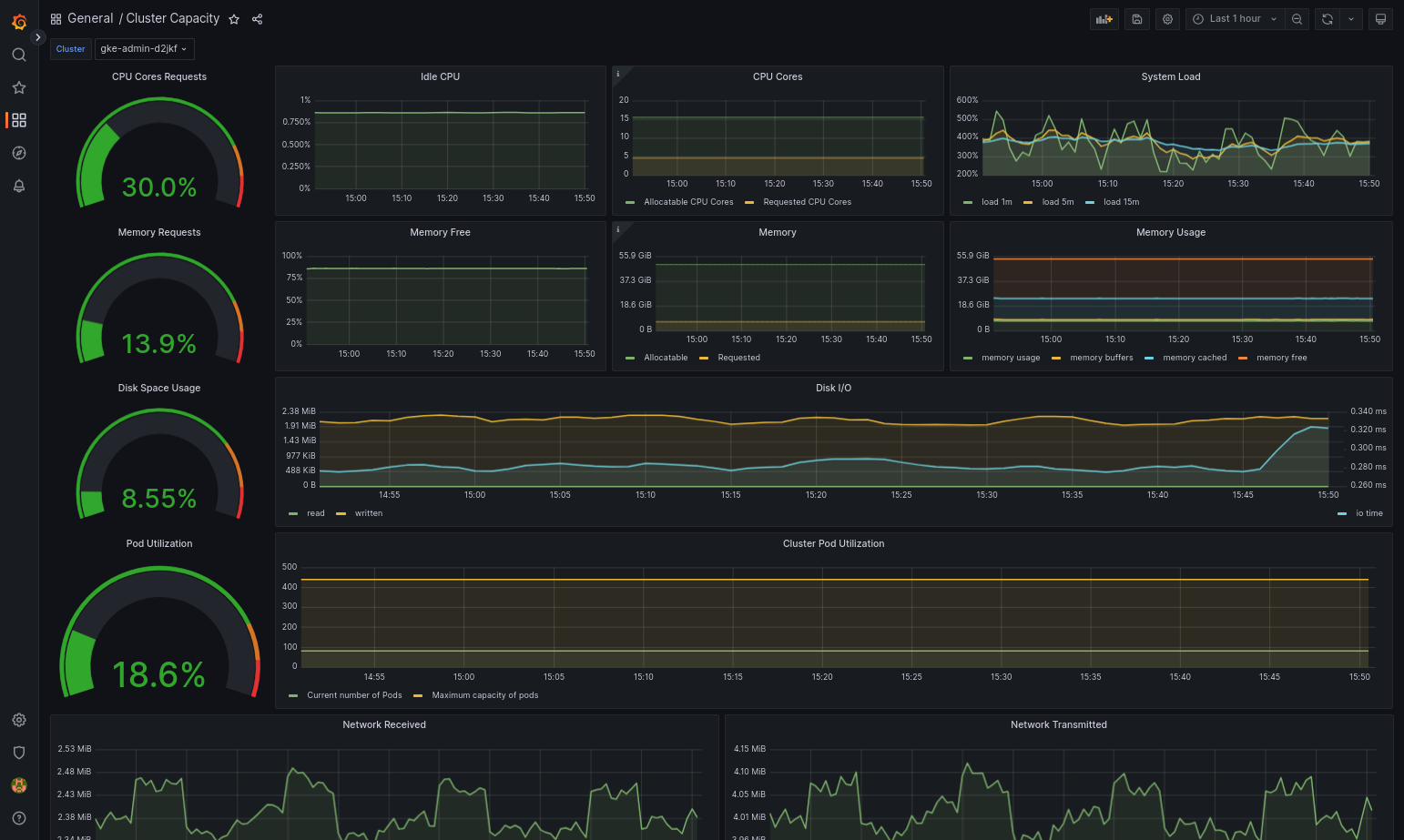
Risorse aggiuntive
Per ulteriori informazioni su Managed Service per Prometheus, consulta le seguenti risorse:
Le metriche del piano di controllo GKE sono compatibili con PromQL
Utilizzare Managed Service per Prometheus per le applicazioni utente su Google Distributed Cloud
Utilizzo di Prometheus e Grafana
A partire dalla versione 1.16, Prometheus e Grafana non sono disponibili nei cluster appena creati. Ti consigliamo di utilizzare Managed Service per Prometheus come sostituzione del monitoraggio all'interno del cluster.
Se esegui l'upgrade a 1.16 di un cluster 1.15 in cui sono abilitati Prometheus e Grafana, Prometheus e Grafana continueranno a funzionare così come sono, ma non verranno aggiornati o non riceveranno patch di sicurezza.
Se vuoi eliminare tutte le risorse Prometheus e Grafana dopo l'upgrade alla versione 1.16, esegui il seguente comando:
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
In alternativa all'utilizzo dei componenti Prometheus e Grafana inclusi nelle versioni precedenti di Google Distributed Cloud, puoi passare a una versione della community open source di Prometheus e Grafana.
Problema noto
Nei cluster utente, Prometheus e Grafana vengono disattivati automaticamente durante gli upgrade. Tuttavia, i dati di configurazione e delle metriche non vengono persi.
Per risolvere il problema, dopo l'upgrade, apri monitoring-sample per la modifica e imposta enablePrometheus su true.
Accesso alle metriche di monitoraggio dalle dashboard di Grafana
Grafana mostra le metriche raccolte dai tuoi cluster. Per visualizzare queste metriche, devi accedere alle dashboard di Grafana:
Ottieni il nome del pod Grafana in esecuzione nello spazio dei nomi
kube-systemdi un cluster utente:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
dove [USER_CLUSTER_KUBECONFIG] è il file kubeconfig del cluster utente.
Il pod Grafana ha un server HTTP in ascolto sulla porta localhost TCP 3000. Inoltra una porta locale alla porta 3000 nel pod in modo da poter visualizzare le dashboard di Grafana da un browser web.
Ad esempio, supponiamo che il nome del pod sia
grafana-0. Per inoltrare la porta 50000 alla porta 3000 nel pod, inserisci questo comando:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
Da un browser web, vai a
http://localhost:50000.Nella pagina di accesso, inserisci
adminper il nome utente e la password.Se l'accesso va a buon fine, ti verrà chiesto di cambiare la password. Dopo aver modificato la password predefinita, dovrebbe essere caricata la dashboard della casa di Grafana del cluster di utenti.
Per accedere ad altre dashboard, fai clic sul menu a discesa Home nell'angolo in alto a sinistra della pagina.
Per un esempio di utilizzo di Grafana, consulta Creare una dashboard Grafana.
Accedere agli avvisi
Prometheus Alertmanager raccoglie gli avvisi dal server Prometheus. Puoi visualizzare questi avvisi in una dashboard di Grafana. Per visualizzare gli avvisi, devi accedere alla dashboard:
Il container nel pod
alertmanager-0è in ascolto sulla porta TCP 9093. Inoltra una porta locale alla porta 9093 nel pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
Da un browser web, vai a
http://localhost:50001.
Modifica della configurazione di Prometheus Alertmanager
Puoi modificare la configurazione predefinita di Prometheus Alertmanager modificando il file monitoring.yaml del tuo cluster di utenti. Devi farlo se vuoi indirizzare gli avvisi a una destinazione specifica anziché mantenerli nella dashboard. Puoi scoprire come configurare Alertmanager nella documentazione relativa alla configurazione di Prometheus.
Per modificare la configurazione di Alertmanager:
Crea una copia del file manifest
monitoring.yamldel cluster utente:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Per configurare Alertmanager, apporta modifiche ai campi in
spec.alertmanager.yml. Al termine, salva il file manifest modificato.Applica il manifest al cluster:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Creare una dashboard Grafana
Hai eseguito il deployment di un'applicazione che espone una metrica, ne hai verificato l'esposizione e hai verificato che Prometheus la estrae. Ora puoi aggiungere la metrica a livello di applicazione a una dashboard Grafana personalizzata.
Per creare una dashboard Grafana:
- Se necessario, accedi a Grafana.
- Nella dashboard della casa, fai clic sul menu a discesa Casa nell'angolo in alto a sinistra della pagina.
- Nel menu a destra, fai clic su Nuova dashboard.
- Nella sezione Nuovo riquadro, fai clic su Grafico. Viene visualizzata una dashboard del grafico vuota.
- Fai clic su Titolo riquadro e poi su Modifica. Il riquadro Grafico in basso si apre nella scheda Metriche.
- Nel menu a discesa Origine dati, seleziona user. Fai clic su Aggiungi
query e inserisci
foonel campo Cerca. - Fai clic sul pulsante Torna alla dashboard nell'angolo in alto a destra dello schermo. Viene visualizzata la dashboard.
- Per salvare la dashboard, fai clic su Salva dashboard nell'angolo in alto a destra della schermata. Scegli un nome per la dashboard, quindi fai clic su Salva.
Disattivazione di Prometheus e Grafana
A partire dalla versione 1.16, Prometheus e Grafana non sono più controllati dal campo enablePrometheus nell'oggetto monitoring-sample.
Per informazioni dettagliate, vedi Utilizzare Prometheus e Grafana.
Esempio: aggiunta di metriche a livello di applicazione a una dashboard Grafana
Le sezioni seguenti illustrano la procedura per aggiungere le metriche per un'applicazione. In questa sezione, completa le seguenti attività:
- Esegui il deployment di un'applicazione di esempio che espone una metrica denominata
foo. - Verifica che Prometheus esponga e estragga la metrica.
- Crea una dashboard Grafana personalizzata.
Esegui il deployment dell'applicazione di esempio
L'applicazione di esempio viene eseguita in un unico pod. Il contenitore del pod espone una metrica, foo, con un valore costante di 40.
Crea il seguente manifest del pod, pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Quindi applica il manifest del pod al cluster di utenti:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Verifica che la metrica sia esposta e sottoposta a scraping
Il container nel pod
prometheus-examplerimane in ascolto sulla porta TCP 8080. Inoltra una porta locale alla porta 8080 nel pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
Per verificare che l'applicazione esponga la metrica, esegui il seguente comando:
curl localhost:50002/metrics | grep fooIl comando restituisce il seguente output:
# HELP foo Custom metric # TYPE foo gauge foo 40
Il container nel pod
prometheus-0è in ascolto sulla porta TCP 9090. Inoltra una porta locale alla porta 9090 nel pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Per verificare che Prometheus stia eseguendo lo scraping della metrica, vai all'indirizzo http://localhost:50003/targets, che dovrebbe indirizzarti al pod
prometheus-0nel gruppo di destinazioneprometheus-io-pods.Per visualizzare le metriche in Prometheus, vai alla pagina http://localhost:50003/graph. Nel campo di ricerca, inserisci
fooe poi fai clic su Esegui. La pagina deve mostrare la metrica.
Configurazione della risorsa personalizzata Stackdriver
Quando crei un cluster, Google Distributed Cloud crea automaticamente una risorsa personalizzata Stackdriver. Puoi modificare la specifica nella risorsa personalizzata per ignorare i valori predefiniti per le richieste e i limiti di CPU e memoria per un componente Stackdriver e puoi ignorare separatamente la dimensione e la classe di archiviazione predefinite.
Sostituire i valori predefiniti per le richieste e i limiti di CPU e memoria
Per sostituire questi valori predefiniti:
Apri la risorsa personalizzata Stackdriver in un editor a riga di comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dove KUBECONFIG è il percorso del file kubeconfig per il cluster. Può trattarsi di un cluster di amministrazione o di un cluster utente.
Nella risorsa personalizzata Stackdriver, aggiungi il campo
resourceAttrOverridenella sezionespec:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYTieni presente che il campo
resourceAttrOverridesostituisce tutti i limiti e le richieste predefinite esistenti per il componente specificato. I seguenti componenti sono supportati daresourceAttrOverride:- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
Un file di esempio ha il seguente aspetto:
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5GiSalva le modifiche ed esci dall'editor a riga di comando.
Controlla lo stato dei pod:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
Ad esempio, un pod funzionante ha il seguente aspetto:
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
Controlla le specifiche del pod del componente per assicurarti che le risorse siano impostate correttamente.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
dove
POD_NAMEè il nome del pod che hai appena modificato. Ad esempio,stackdriver-prometheus-k8s-0La risposta è la seguente:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Sostituire le dimensioni dello spazio di archiviazione predefinite
Per sostituire questi valori predefiniti:
Apri la risorsa personalizzata Stackdriver in un editor a riga di comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Aggiungi il campo
storageSizeOverridenella sezionespec. Puoi utilizzare il componentestackdriver-prometheus-k8sostackdriver-prometheus-app. La sezione ha questo formato:storageSizeOverride: STATEFULSET_NAME: SIZE
In questo esempio vengono utilizzati il statefulset
stackdriver-prometheus-k8se la dimensione120Gi.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiSalva ed esci dall'editor a riga di comando.
Controlla lo stato dei pod:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Controlla le specifiche del pod del componente per assicurarti che le dimensioni dello spazio di archiviazione siano sostituite correttamente.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
La risposta è la seguente:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Sostituire le impostazioni predefinite della classe di archiviazione
Prerequisito
Devi prima creare un StorageClass da utilizzare.
Per eseguire l'override della classe di archiviazione predefinita per i volumi permanenti rivendicati dai componenti di logging e monitoraggio:
Apri la risorsa personalizzata Stackdriver in un editor a riga di comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dove KUBECONFIG è il percorso del file kubeconfig per il cluster. Può trattarsi di un cluster di amministrazione o di un cluster utente.
Aggiungi il campo
storageClassNamenella sezionespec:storageClassName: STORAGECLASS_NAME
Tieni presente che il campo
storageClassNamesostituisce la classe di archiviazione predefinita esistente e si applica a tutti i componenti di monitoraggio e registrazione con volumi permanenti rivendicati. Un file di esempio ha il seguente aspetto:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Salva le modifiche.
Controlla lo stato dei pod:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Ad esempio, un pod funzionante ha il seguente aspetto:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Controlla le specifiche del pod di un componente per assicurarti che la classe di archiviazione sia impostata correttamente.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Ad esempio, utilizzando l'insieme stateful
stackdriver-prometheus-k8s, la risposta è la seguente:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Disattivare le metriche ottimizzate
Per impostazione predefinita, gli agenti delle metriche in esecuzione nel cluster raccolgono e segnalano a Stackdriver un insieme ottimizzato di metriche relative a container, Kubelet e Kube-state-metrics. Se hai bisogno di metriche aggiuntive, ti consigliamo di trovarne una sostituzione nell'elenco delle metriche di GKE Enterprise.
Ecco alcuni esempi di sostituzioni che potresti utilizzare:
| Metrica disabilitata | Sostituzioni |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Per disattivare l'impostazione predefinita delle metriche kube-state-metrics ottimizzate (non consigliata), procedi nel seguente modo:
Apri la risorsa personalizzata Stackdriver in un editor a riga di comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dove KUBECONFIG è il percorso del file kubeconfig per il cluster. Può trattarsi di un cluster di amministrazione o di un cluster utente.
Imposta il campo
optimizedMetricssufalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class Salva le modifiche ed esci dall'editor a riga di comando.
Problema noto: condizione di errore di Cloud Monitoring
(ID problema 159761921)
In determinate condizioni, il pod Cloud Monitoring predefinito, impiegato per impostazione predefinita in ogni nuovo cluster, può non rispondere.
Ad esempio, quando viene eseguito l'upgrade dei cluster, i dati di archiviazione possono essere danneggiati quando i pod in statefulset/prometheus-stackdriver-k8s vengono riavviati.
In particolare, il pod di monitoraggio stackdriver-prometheus-k8s-0 può essere bloccato in un loop quando i dati danneggiati impediscono la scrittura prometheus-stackdriver-sidecar nell'archiviazione del cluster PersistentVolume.
Puoi diagnosticare e recuperare manualmente l'errore seguendo i passaggi riportati di seguito.
Diagnostica dell'errore di Cloud Monitoring
Quando il pod di monitoraggio non funziona, i log segnalano quanto segue:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Ripristino da un errore di Cloud Monitoring
Per recuperare Cloud Monitoring manualmente:
Interrompi il monitoraggio del cluster. Riduci l'operatore
stackdriverper evitare la riconciliazione del monitoraggio:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Elimina i carichi di lavoro della pipeline di monitoraggio:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Elimina i PersistentVolumeClaim (PVC) della pipeline di monitoraggio:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Riavvia il monitoraggio del cluster. Esegui l'upgrade dell'operatore Stackdriver per reinstallare una nuova pipeline di monitoraggio e riprendere la riconciliazione:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1