Cette page explique dans le détail comment les parcs vous aident à gérer les déploiements multiclusters, et en spécifie la terminologie et les concepts clés. Les parcs sont un concept Google Cloud qui permet d'organiser logiquement des clusters et d'autres ressources. Ils vous permettent d'utiliser et de gérer des fonctionnalités multiclusters, et d'appliquer des règles cohérentes sur l'ensemble de vos systèmes. Les parcs sont essentiels au fonctionnement des fonctionnalités multicluster dans Google Cloud.
Ce guide se destine aux lecteurs techniques, y compris les architectes système, les opérateurs de plate-forme et les opérateurs de service, qui souhaitent exploiter plusieurs clusters et une infrastructure associée. Ces concepts sont utiles chaque fois que votre entreprise exécute plusieurs clusters, que ce soit dansGoogle Cloud, via plusieurs fournisseurs cloud ou sur site.
Avant de lire cette page, assurez-vous de connaître les concepts de base de Kubernetes, tels que les clusters et les espaces de noms. Si ce n'est pas le cas, consultez les pages Principes de base de Kubernetes, Documentation GKE et Préparer une application pour Cloud Service Mesh.
Terminologie
Voici quelques termes importants que nous employons au sujet des parcs.
Ressources compatibles avec les parcs
Les ressources compatibles avec les parcs sont des ressources de projet Google Cloud qui peuvent être regroupées logiquement et gérées en tant que parc unifié. Actuellement, les membres du parc ne peuvent être que des clusters Kubernetes.
Projet hôte du parc
L'implémentation des parcs, à l'instar de nombreuses autres ressources Google Cloud , est enracinée dans un projet Google Cloud , que nous appelons projet hôte du parc. Un projet Google Cloud donné ne peut être associé qu'à un seul parc (ou à aucun parc). Cette restriction renforce l'utilisation des projets Google Cloud pour assurer une isolation plus forte entre les ressources qui ne sont pas contrôlées ni consommées conjointement.
Infrastructure de regroupement
Le premier concept important des parcs est le concept de regroupement, c'est-à-dire le choix des ressources compatibles associées à intégrer à un parc. La décision de regrouper les questions nécessite de répondre aux questions suivantes :
- Les ressources sont-elles liées entre elles ?
- Les ressources qui disposent de grandes quantités de communication interservices bénéficient le plus de la gestion regroupée dans un parc.
- Les ressources d'un même environnement de déploiement (par exemple, votre environnement de production) doivent être gérées ensemble au sein d'un parc.
- Qui gère les ressources ?
- Le contrôle unifié des ressources (ou du moins approuvé mutuellement) est essentiel pour garantir l'intégrité du parc.
Pour illustrer ce point, prenons l'exemple d'une entreprise qui comporte plusieurs secteurs d'activité. Dans ce cas, les services communiquent rarement hors de leur secteur d'activité (par exemple, les cycles de mise à niveau diffèrent selon les secteurs d'activités) et peuvent disposer d'ensembles d'administrateurs différents pour chaque secteur. Dans ce cas, il peut être judicieux que chaque secteur d'activité dispose de son parc. Chaque secteur d'activité est également susceptible d'adopter plusieurs parcs pour séparer ses services de production et hors production.
Étant donné que d'autres concepts de base sont abordés dans les sections suivantes, vous découvrirez d'autres raisons de créer plusieurs parcs en fonction des besoins de votre entreprise.
Uniformité
Le concept d'uniformité est fondamental dans les parcs. Cela signifie que lorsque vous utilisez certaines fonctionnalités compatibles avec les parcs, certains objets Kubernetes tels que les espaces de noms portant le même nom dans différents clusters sont traités comme s'ils étaient identiques. Cette normalisation permet de faciliter l'administration des ressources de parc. Si vous utilisez des fonctionnalités qui exploitent l'uniformité, cette hypothèse d'uniformité fournit des conseils précis sur la configuration des espaces de noms, des services et des identités. Cependant, elle suit également ce que la plupart des entreprises mettent déjà en œuvre elles-mêmes.
Les différents types d'uniformité offrent des avantages différents, comme indiqué dans le tableau suivant :
| Propriété d'uniformité | Permet de... |
|---|---|
| Un espace de noms est considéré comme identique sur plusieurs clusters. |
|
| Une combinaison d'espace de noms et de nom de service est considérée comme identique sur plusieurs clusters. Les services portant le même nom dans le même espace de noms utilisent le même sélecteur d'étiquettes. |
|
| Une combinaison d'espace de noms et de compte de service (identité) est considérée comme identique sur plusieurs clusters. |
|
Comme cela le suggère, différentes fonctionnalités de parc reposent sur différents types d'uniformité. Un petit nombre de fonctionnalités n'utilisent pas du tout l'uniformité. Pour en savoir plus, consultez la section Quelles fonctionnalités utilisent l'uniformité ?, qui décrit les fonctionnalités que vous pouvez utiliser sans avoir à prendre en compte l'uniformité au niveau du parc et celles qui peuvent nécessiter une planification plus minutieuse.
Identité de l'espace de noms
Les espaces de noms sont un exemple fondamental illustrant l'uniformité dans un parc. Les espaces de noms portant le même nom dans différents clusters sont considérés comme identiques par de nombreuses fonctionnalités de parc. Une autre façon de considérer cette propriété est qu'un espace de noms est défini de manière logique dans un parc, même si l'instanciation de l'espace de noms n'existe que dans un sous-ensemble de ressources de parc.
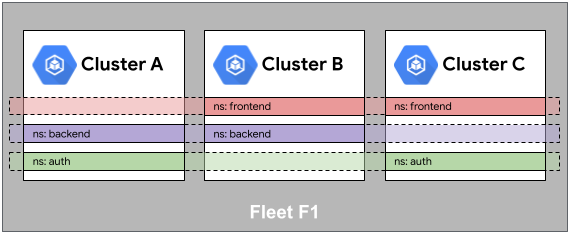
Prenons l'exemple de l'espace de noms backend suivant. Bien que l'espace de noms ne soit instancié que dans les clusters A et B, il est implicitement réservé dans le cluster C. Cela permet à un service dans l'espace de noms backend d'être également planifié dans le cluster C si nécessaire.
Entre autres, les espaces de noms sont alloués à l'ensemble du parc, et non au cluster. Ainsi, l'uniformité d'espace de noms nécessite une propriété de l'espace de noms cohérente au sein du parc.
Uniformité du service
Cloud Service Mesh et Multi Cluster Ingress utilisent le concept d'uniformité de services dans un espace de noms. Comme pour l'uniformité d'espace de noms, cela signifie que les services ayant le même espace de noms et le même nom de service sont considérés comme étant le même service.
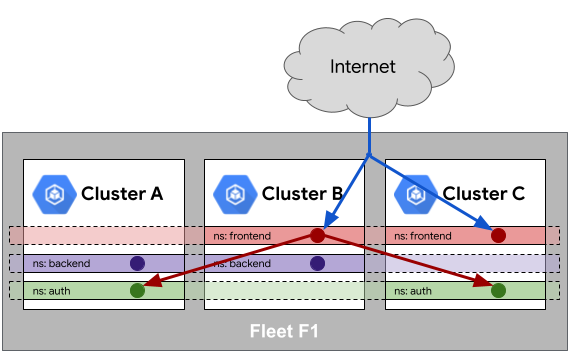
Les points de terminaison de service peuvent être fusionnés sur l'ensemble du maillage avec Cloud Service Mesh. Avec un objet Ingress multicluster, une ressource MultiClusterService (MCS) rend la fusion de points de terminaison plus explicite. Cependant, nous recommandons des pratiques semblables en matière d'attribution de noms. Pour cette raison, il est important de s'assurer que les services portant des noms identiques dans le même espace de noms correspondent bien à une même entité.
Dans l'exemple suivant, la charge du trafic Internet est équilibrée sur un service portant le même nom dans l'espace de noms frontend présent dans les clusters B et C. De même, à l'aide des propriétés de maillage de services au sein du parc, le service situé dans l'espace de noms frontend peut atteindre un service portant le même nom dans l'espace de noms auth présent dans les clusters A et C.
Uniformité d'identité lors de l'accès à des ressources externes
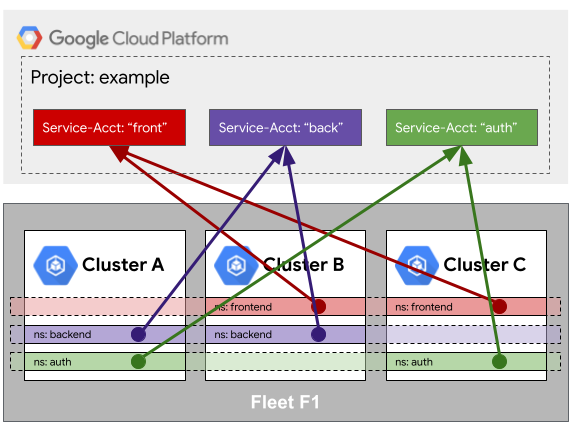
Avec la fédération d'identité de charge de travail de parc, les services dans un parc peuvent exploiter une identité commune lors de leur sortie pour accéder à des ressources externes telles que des services Google Cloud , des espaces de stockage, etc. Cette identité commune permet de donner aux services d'un parc un accès unique à une ressource externe plutôt que cluster par cluster.
Pour mieux illustrer ce point, prenons l'exemple suivant. Les clusters A, B et C sont inscrits dans le cadre d'une identité commune dans leur parc. Lorsque les services de l'espace de noms backend accèdent aux ressources Google Cloud , leur identité est mappée à un compte de service Google Cloud commun appelé back. Le compte de serviceGoogle Cloud back peut être autorisé sur plusieurs services gérés, de Cloud Storage à Cloud SQL. Lorsque de nouvelles ressources de parc telles que des clusters sont ajoutées dans l'espace de noms backend, elles héritent automatiquement des propriétés de similarité de l'identité de la charge de travail.
En raison de l'uniformité des identités, il est important que toutes les ressources d'un parc soient approuvées et bien validées. Pour reprendre l'exemple précédent, si le cluster C appartient à une équipe distincte non approuvée, il peut également créer un espace de noms backend et accéder aux services gérés comme s'il appartenait à backend dans le cluster A ou B.
Uniformité de l'identité dans un parc
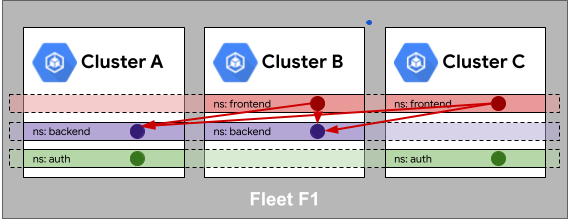
Dans le parc, l'uniformité d'identité est employée de la même manière que l'identité externe évoquée précédemment. À l'instar des services de parc, autorisés une seule fois pour un service externe, ils peuvent également l'être en interne.
Dans l'exemple suivant, nous utilisons Cloud Service Mesh pour créer un maillage de services multicluster où frontend a accès à backend.
Avec Cloud Service Mesh et les parcs, il n'est pas nécessaire de spécifier que les frontend des clusters B et C peuvent accéder aux backend des clusters A et B. Il suffit juste de spécifier que les frontend du parc peuvent accéder aux backend du parc. Cette propriété simplifie non seulement l'autorisation, mais rend également les limites de ressources plus flexibles. Désormais, les charges de travail peuvent facilement être déplacées d'un cluster à un autre sans affecter leur autorisation. Comme pour l'uniformité de l'identité de la charge de travail, la gouvernance des ressources de parc est essentielle pour garantir l'intégrité de la communication de service à service.
Quelles fonctionnalités utilisent l'uniformité ?
Un certain nombre de fonctionnalités de parc ne reposent pas du tout sur l'uniformité. Elles peuvent être activées et utilisées sans avoir à déterminer si vous souhaitez supposer une forme d'uniformité dans votre parc. D'autres fonctionnalités (y compris Config Sync et Policy Controller) peuvent utiliser l'uniformité (par exemple, si vous souhaitez sélectionner un espace de noms sur plusieurs clusters de membres du parc pour la configuration à partir d'une seule source de référence), mais ne l'exigent pas pour tous les cas d'utilisation. Enfin, certaines fonctionnalités, comme Multi Cluster Ingress et la fédération d'identité de charge de travail à l'échelle du parc, supposent toujours une certaine forme de similitude entre les clusters. Elles doivent donc être adoptées avec précaution en fonction de vos besoins et des charges de travail existantes.
Certaines fonctionnalités de parc (telles que la fédération d'identité de charge de travail de parc) nécessitent que l'ensemble de votre parc soit prêt pour les hypothèses d'uniformité qu'elles utilisent. D'autres fonctionnalités, comme la gestion des équipes, vous permettent d'intégrer progressivement l'uniformité au niveau de l'espace de noms ou du niveau d'accès de l'équipe.
Le tableau suivant indique les fonctionnalités qui require un ou plusieurs des concepts d'uniformité décrits dans cette section.
| Fonctionnalité | Compatible avec l'adoption progressive de l'uniformité | Dépend de l'uniformité de l'espace de noms | Dépend de l'uniformité du service | Dépend de l'uniformité de l'identité |
|---|---|---|---|---|
| Parcs | N/A | Non | Non | Non |
| Autorisation binaire | N/A | Non | Non | Non |
| Chiffrement transparent entre les nœuds | N/A | Non | Non | Non |
| Règle de réseau basée sur le nom de domaine complet | N/A | Non | Non | Non |
| Passerelle Connect | N/A | Non | Non | Non |
| Config Sync | N/A | Non | Non | Non |
| Policy Controller | N/A | Non | Non | Non |
| Stratégie de sécurité GKE | N/A | Non | Non | Non |
| Advanced Vulnerability Insights | N/A | Non | Non | Non |
| Stratégie de conformité | N/A | Non | Non | Non |
| Séquençage du déploiement | N/A | Non | Non | Non |
| Gestion d'équipe | Oui | Oui | Oui | Non |
| Multi Cluster Ingress | Oui | Oui | Oui | Oui |
| Services multicluster | Oui | Oui | Oui | Oui |
| Fédération d'identité de charge de travail de parc | Non | Oui | Oui | Oui |
| Cloud Service Mesh | Non | Oui | Oui | Oui |
Exclusivité
Les ressources compatibles d'un parc ne peuvent faire partie que d'un seul parc à la fois. Il s'agit d'une restriction appliquée par les outils et les composants Google Cloud . Cette restriction garantit qu'il n'existe qu'une seule source fiable pour un cluster. Sans exclusivité, même les composants les plus simples seraient difficiles à utiliser, ce qui oblige votre entreprise à comprendre et à configurer l'interaction de plusieurs composants provenant de plusieurs parcs.
Confiance élevée
L'uniformité des services, l'uniformité d'identité de la charge de travail et celle du maillage reposent sur un principe de confiance élevé entre les membres d'un parc. Cela permet d'assurer une gestion optimale de ces ressources jusqu'au parc, plutôt que de gérer les ressources par ressource (c'est-à-dire, par cluster pour les ressources Kubernetes), et de faire en sorte que la ressource limite du cluster soit moins importante.
En d'autres termes, au sein d'un parc, les clusters offrent une protection contre les problèmes de rayons d'impact, de disponibilité (du plan de contrôle et de l'infrastructure sous-jacente), des voisins bruyants, etc. Toutefois, ils ne constituent pas une forte limite d'isolation pour la stratégie et la gouvernance, car les administrateurs de tout membre dans un parc peuvent potentiellement affecter les opérations de services d'autres membres.
Par conséquent, nous recommandons de conserver les clusters non approuvés par l'administrateur du parc dans leurs propres parcs afin qu'ils soient isolés. Si nécessaire, les services individuels peuvent ensuite être autorisés au-delà de la limite du parc.
Niveaux d'accès d'équipe
Un niveau d'accès d'équipe est un mécanisme permettant de subdiviser davantage votre parc en groupes de clusters, ce qui vous permet de définir les ressources compatibles avec le parc attribuées à une équipe de développement spécifique. Selon votre cas d'utilisation, un cluster membre d'un parc peut être associé à aucune équipe, à une ou à plusieurs équipes, ce qui permet à plusieurs équipes de partager des clusters. Vous pouvez également utiliser les niveaux d'accès d'équipe pour mettre en séquence les déploiements de mise à niveau des clusters sur l'ensemble de votre parc, bien que cela nécessite que chaque cluster ne soit associé qu'à une seule équipe.
Un niveau d'accès d'équipe peut être associé à des espaces de noms de parc explicitement définis, tandis que l'espace de noms est considéré comme identique dans tout le niveau d'accès. Vous bénéficiez ainsi d'un contrôle plus précis sur les espaces de noms que l'uniformité d'espace de noms par défaut fournie uniquement par les parcs.
Composants compatibles avec les parcs
Les composants suivants exploitent tous les concepts de parc tels que l'espace de noms et l'uniformité d'identité, afin de simplifier l'utilisation de vos clusters et services. Pour connaître les exigences ou les limites concernant l'utilisation des parcs avec chaque composant, consultez la section Configuration requise.
Pools d'identités de charge de travail
Un parc propose un pool d'identités de charge de travail commun, qui peut être utilisé pour authentifier et autoriser les charges de travail de manière uniforme, au sein d'un maillage de services et à destination de services externes.Cloud Service Mesh
Cloud Service Mesh est une suite d'outils qui vous aide à surveiller et à gérer un maillage de services pour en assurer la fiabilité, sur Google Cloud, sur site ainsi que dans les autres environnements compatibles. Vous pouvez former un maillage de services entre différents clusters faisant partie du même parc.Config Sync
Config Sync vous permet de déployer et de surveiller des packages de configuration déclaratifs pour votre système stockés dans une source centrale de vérité, telle qu'un dépôt Git, en exploitant les concepts fondamentaux de Kubernetes tels que les espaces de noms, les libellés et les annotations. Avec Config Sync, la configuration est définie au niveau du parc, mais appliquée localement dans chacune des ressources membres.Policy Controller
Policy Controller vous permet de mettre en place et d'appliquer des règles déclaratives à vos clusters Kubernetes. Les règles servent de garde-fous et peuvent vous aider à appliquer les bonnes pratiques, à assurer la sécurité et à gérer la conformité de vos clusters et de votre parc.Multi Cluster Ingress
Multi Cluster Ingress utilise le parc pour définir l'ensemble de clusters et de points de terminaison de service sur lesquels le trafic peut être équilibré, ce qui permet de bénéficier de services à faible latence et à haute disponibilité.
Étape suivante
- Découvrez comment utiliser plusieurs clusters pour répondre à vos besoins techniques et métier dans la section Cas d'utilisation de multicluster.
- Êtes-vous prêt à appliquer ces concepts à vos propres systèmes ? Consultez la section Planifier les ressources du parc.