Dokumen ini menunjukkan cara mengonfigurasi logging dan pemantauan untuk komponen sistem di Google Distributed Cloud (khusus software) untuk VMware.
Secara default, Cloud Logging, Cloud Monitoring, dan Google Cloud Managed Service for Prometheus diaktifkan.
Untuk informasi selengkapnya tentang opsi ini, lihat Ringkasan logging dan pemantauan.
Resource yang dimonitor
Resource yang dipantau adalah cara Google merepresentasikan resource seperti cluster, node, Pod, dan penampung. Untuk mempelajari lebih lanjut, lihat dokumentasi Jenis resource yang dimonitor Cloud Monitoring.
Untuk membuat kueri log dan metrik, Anda harus mengetahui setidaknya label resource berikut:
project_id: Project ID dari project monitoring logging cluster. Anda memberikan nilai ini di kolomstackdriver.projectIDfile konfigurasi cluster.location: Region Google Cloud tempat Anda ingin merutekan dan menyimpan metrik Cloud Monitoring. Anda menentukan region selama penginstalan di kolomstackdriver.clusterLocationpada file konfigurasi cluster. Sebaiknya pilih region yang dekat dengan pusat data lokal Anda.Anda menentukan perutean dan lokasi penyimpanan log Cloud Logging di konfigurasi Router Log. Untuk informasi selengkapnya tentang pemilihan rute log, lihat Ringkasan pemilihan rute dan penyimpanan.
cluster_name: Nama cluster yang Anda pilih saat membuat cluster.Anda dapat mengambil nilai
cluster_nameuntuk cluster admin atau pengguna dengan memeriksa resource kustom Stackdriver:kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
di mana
CLUSTER_KUBECONFIGadalah jalur ke file kubeconfig cluster admin atau cluster pengguna yang memerlukan nama cluster.
Pemilihan rute log dan metrik
Pengirim log Stackdriver (stackdriver-log-forwarder) mengirim log dari setiap mesin node ke Cloud Logging. Demikian pula, agen metrik GKE
(gke-metrics-agent) mengirimkan metrik dari setiap mesin node ke
Cloud Monitoring. Sebelum log dan metrik dikirim, Operator Stackdriver (stackdriver-operator) akan melampirkan nilai dari kolom clusterLocation di resource kustom stackdriver ke setiap entri log dan metrik sebelum dirutekan ke Google Cloud. Selain itu, log dan metrik dikaitkan dengan project Google Cloud yang ditentukan dalam spesifikasi resource kustom stackdriver (spec.projectID). Resource stackdriver mendapatkan nilai untuk kolom clusterLocation dan projectID dari kolom stackdriver.clusterLocation dan stackdriver.projectID di bagian clusterOperations dari resource Cluster pada waktu pembuatan cluster.
Semua metrik dan entri log yang dikirim oleh agen stackdriver dirutekan ke endpoint penyerapan global. Dari sana, data diteruskan ke endpoint Google Cloud regional terdekat yang dapat dijangkau untuk memastikan keandalan transpor data.
Setelah endpoint global menerima entri metrik atau log, hal yang terjadi selanjutnya bergantung pada layanan:
Cara pemilihan rute log dikonfigurasi: saat endpoint logging menerima pesan log, Cloud Logging akan meneruskan pesan tersebut melalui Router Log. Sink dan filter dalam konfigurasi Log Router menentukan cara merutekan pesan. Anda dapat merutekan entri log ke tujuan seperti bucket Logging regional, yang menyimpan entri log, atau ke Pub/Sub. Untuk mengetahui informasi selengkapnya tentang cara kerja pemilihan rute log dan cara mengonfigurasinya, lihat Ringkasan pemilihan rute dan penyimpanan.
Kolom
clusterLocationdi resource kustomstackdriveratau kolomclusterOperations.locationdalam spesifikasi Cluster tidak dipertimbangkan dalam proses pemilihan rute ini. Untuk log,clusterLocationhanya digunakan untuk memberi label pada entri log, yang dapat membantu pemfilteran di Logs Explorer.Cara konfigurasi perutean metrik: saat endpoint metrik menerima entri metrik, Cloud Monitoring akan merutekan entri secara otomatis ke lokasi yang ditentukan oleh metrik. Lokasi dalam metrik berasal dari kolom
clusterLocationdi resource kustomstackdriver.Rencanakan konfigurasi Anda: saat Anda mengonfigurasi Cloud Logging dan Cloud Monitoring, konfigurasikan Router Log dan tentukan
clusterLocationyang sesuai dengan lokasi yang paling mendukung kebutuhan Anda. Misalnya, jika Anda ingin log dan metrik dikirim ke lokasi yang sama, tetapkanclusterLocationke region Google Cloud yang sama dengan yang digunakan Log Router untuk project Google Cloud Anda.Perbarui konfigurasi jika diperlukan: Anda dapat melakukan perubahan kapan saja pada setelan tujuan untuk log dan metrik karena persyaratan bisnis, seperti rencana pemulihan dari bencana. Perubahan pada konfigurasi Log Router di kolom Google Cloud dan
clusterLocationdi resource kustomstackdriverakan segera diterapkan.
Menggunakan Cloud Logging
Anda tidak perlu melakukan tindakan apa pun untuk mengaktifkan Cloud Logging untuk cluster.
Namun, Anda harus menentukan project Google Cloud tempat Anda ingin melihat log. Dalam file konfigurasi cluster, Anda menentukan project Google Cloud di bagian stackdriver.
Anda dapat mengakses log menggunakan Logs Explorer di konsol Google Cloud . Misalnya, untuk mengakses log penampung:
- Buka Logs Explorer di Google Cloud console untuk project Anda.
- Temukan log untuk penampung dengan:
- Mengklik kotak drop-down katalog log kiri atas dan memilih Container Kubernetes.
- Memilih nama cluster, lalu namespace, lalu penampung dari hierarki.
Melihat log untuk pengontrol di cluster bootstrap
-
Di konsol Google Cloud , buka halaman Logs Explorer:
Jika Anda menggunakan kotak penelusuran untuk menemukan halaman ini, pilih hasil yang subjudulnya adalah Logging.
Untuk melihat semua log pengontrol di cluster bootstrap, jalankan kueri berikut di editor kueri:
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
Untuk melihat log pod tertentu, edit kueri untuk menyertakan nama pod tersebut:
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Menggunakan Cloud Monitoring
Anda tidak perlu melakukan tindakan apa pun untuk mengaktifkan Cloud Monitoring untuk cluster.
Namun, Anda harus menentukan project Google Cloud tempat Anda ingin melihat metrik.
Dalam file konfigurasi cluster, Anda menentukan project Google Cloud di
bagian stackdriver.
Anda dapat memilih dari lebih dari 1.500 metrik menggunakan Metrics Explorer. Untuk mengakses Metrics Explorer, lakukan hal berikut:
Di konsol Google Cloud , pilih Monitoring, atau gunakan tombol berikut:
Pilih Resource > Metrics Explorer.
Anda juga dapat melihat metrik di dasbor di Google Cloud konsol. Untuk informasi tentang cara membuat dasbor dan melihat metrik, lihat Membuat dasbor.
Melihat data pemantauan tingkat armada
Untuk melihat keseluruhan penggunaan resource fleet menggunakan data Cloud Monitoring, termasuk cluster Google Distributed Cloud, Anda dapat menggunakan ringkasan Google Kubernetes Engine di konsol Google Cloud . Lihat Mengelola cluster dari Google Cloud konsol untuk mengetahui selengkapnya.
Batas kuota Cloud Monitoring default
Pemantauan Google Distributed Cloud memiliki batas default 6.000 panggilan API per menit untuk setiap project. Jika Anda melebihi batas ini, metrik Anda mungkin tidak ditampilkan. Jika Anda memerlukan batas pemantauan yang lebih tinggi, mintalah melalui Google Cloud konsol.
Menggunakan Managed Service for Prometheus
Google Cloud Managed Service for Prometheus adalah bagian dari Cloud Monitoring dan tersedia secara default. Manfaat Managed Service for Prometheus mencakup hal-hal berikut:
Anda dapat terus menggunakan pemantauan berbasis Prometheus yang ada tanpa mengubah pemberitahuan dan dasbor Grafana.
Jika menggunakan GKE dan Google Distributed Cloud, Anda dapat menggunakan PromQL yang sama untuk metrik di semua cluster. Anda juga dapat menggunakan tab PROMQL di Metrics Explorer di konsol Google Cloud .
Mengaktifkan dan menonaktifkan Managed Service for Prometheus
Mulai dari rilis Google Distributed Cloud 1.30.0-gke.1930, Layanan Terkelola untuk Prometheus selalu diaktifkan. Pada versi sebelumnya, Anda dapat mengedit resource Stackdriver, stackdriver, untuk mengaktifkan atau menonaktifkan Managed Service for Prometheus. Untuk menonaktifkan Managed Service for Prometheus untuk versi cluster sebelum 1.30.0-gke.1930, tetapkan spec.featureGates.enableGMPForSystemMetrics di resource stackdriver ke false.
Melihat data metrik
Saat Managed Service for Prometheus diaktifkan, metrik untuk komponen berikut memiliki format yang berbeda untuk cara penyimpanan dan kueri di Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet dan cadvisor
- kube-state-metrics
- node-exporter
Dalam format baru, Anda dapat membuat kueri metrik sebelumnya menggunakan PromQL atau Monitoring Query Language (MQL).
Contoh PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Untuk menggunakan MQL, tetapkan resource yang dimonitor ke prometheus_target, dan tambahkan jenis Prometheus sebagai akhiran ke metrik.
Contoh MQL:
fetch prometheus_target | metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram' | align delta(5m) | every 5m | group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Mengonfigurasi dasbor Grafana dengan Managed Service for Prometheus
Untuk menggunakan Grafana dengan data metrik dari Managed Service for Prometheus, ikuti langkah-langkah di Kueri menggunakan Grafana untuk mengautentikasi dan mengonfigurasi sumber data Grafana guna membuat kueri data dari Managed Service for Prometheus.
Kumpulan dasbor Grafana contoh disediakan di repositori anthos-samples di GitHub. Untuk menginstal dasbor contoh, lakukan hal berikut:
Download contoh file
.json:git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Jika sumber data Grafana Anda dibuat dengan nama yang berbeda dengan
Managed Service for Prometheus, ubah kolomdatasourcedi semua file.json:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Ganti [DATASOURCE_NAME] dengan nama sumber data di Grafana yang diarahkan ke layanan
frontendPrometheus.Akses UI Grafana dari browser, lalu pilih + Import di bagian menu Dashboards.
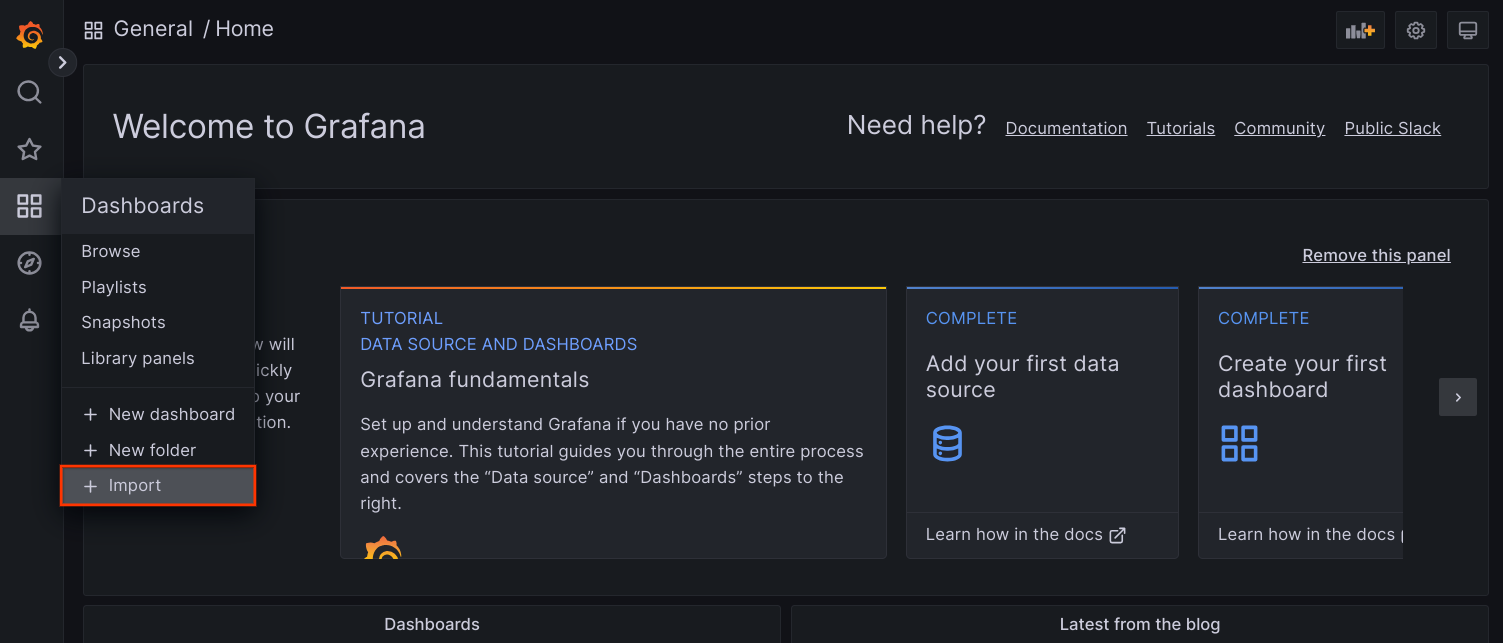
Upload file
.json, atau salin dan tempel konten file, lalu pilih Muat. Setelah konten file berhasil dimuat, pilih Impor. Secara opsional, Anda juga dapat mengubah nama dasbor dan UID sebelum mengimpor.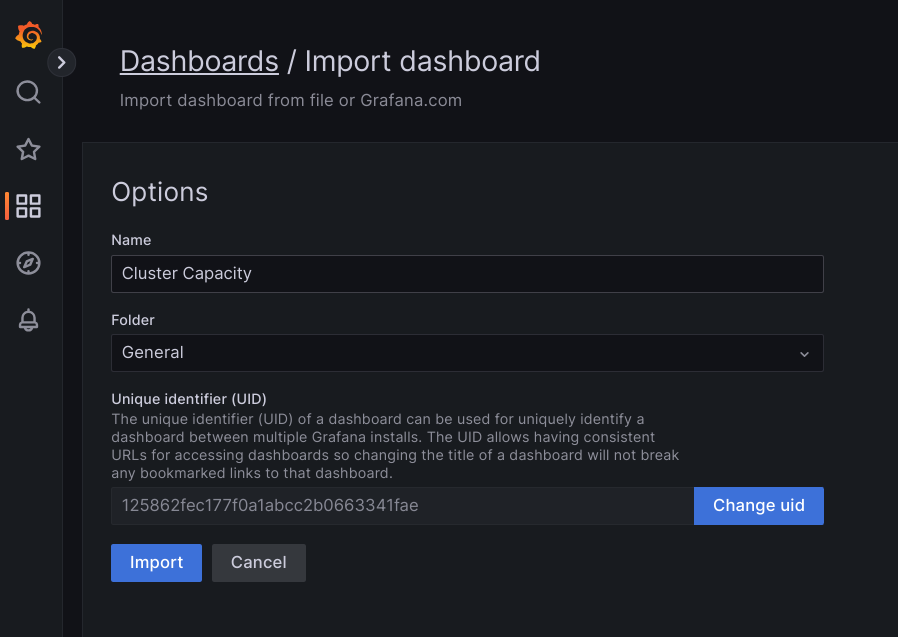
Dasbor yang diimpor akan berhasil dimuat jika Google Distributed Cloud dan sumber data Anda dikonfigurasi dengan benar. Misalnya, screenshot berikut menampilkan dasbor yang dikonfigurasi oleh
cluster-capacity.json.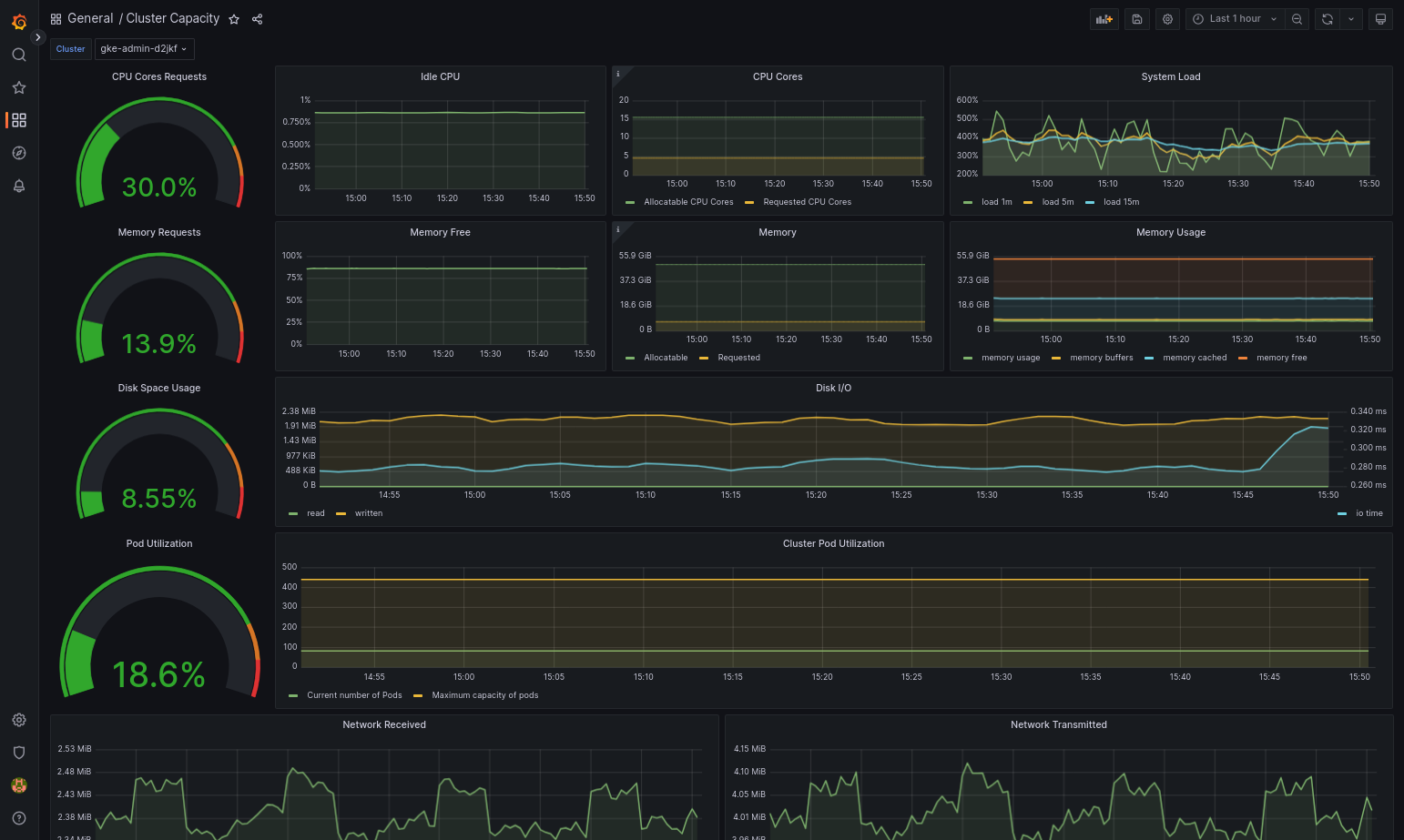
Referensi lainnya
Untuk informasi selengkapnya tentang Managed Service for Prometheus, lihat referensi berikut:
Menggunakan Prometheus dan Grafana
Mulai versi 1.16, Prometheus dan Grafana tidak tersedia di cluster yang baru dibuat. Sebaiknya gunakan Managed Service for Prometheus sebagai pengganti pemantauan dalam cluster.
Jika Anda mengupgrade cluster 1.15 yang mengaktifkan Prometheus dan Grafana ke 1.16, Prometheus dan Grafana akan terus berfungsi seperti biasa, tetapi tidak akan diupdate atau diberi patch keamanan.
Jika Anda ingin menghapus semua resource Prometheus dan Grafana setelah mengupgrade ke 1.16, jalankan perintah berikut:
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
Sebagai alternatif untuk menggunakan komponen Prometheus dan Grafana yang disertakan dalam Google Distributed Cloud versi sebelumnya, Anda dapat beralih ke versi komunitas open source Prometheus dan Grafana.
Masalah umum
Di cluster pengguna, Prometheus dan Grafana otomatis dinonaktifkan selama upgrade. Namun, data konfigurasi dan metrik tidak akan hilang.
Untuk mengatasi masalah ini, setelah upgrade, buka monitoring-sample untuk
pengeditan dan tetapkan enablePrometheus ke true.
Mengakses metrik pemantauan dari dasbor Grafana
Grafana menampilkan metrik yang dikumpulkan dari cluster Anda. Untuk melihat metrik ini, Anda harus mengakses dasbor Grafana:
Dapatkan nama Pod Grafana yang berjalan di namespace
kube-systemcluster pengguna:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
dengan [USER_CLUSTER_KUBECONFIG] adalah file kubeconfig cluster pengguna.
Pod Grafana memiliki server HTTP yang memproses port localhost TCP 3000. Teruskan port lokal ke port 3000 di Pod, sehingga Anda dapat melihat dasbor Grafana dari browser web.
Misalnya, anggap nama Pod adalah
grafana-0. Untuk meneruskan port 50000 ke port 3000 di Pod, masukkan perintah ini:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
Dari browser web, buka
http://localhost:50000.Di halaman login, masukkan
adminuntuk nama pengguna dan sandi.Jika login berhasil, Anda akan melihat perintah untuk mengubah sandi. Setelah Anda mengubah sandi default, Dasbor Beranda Grafana cluster pengguna akan dimuat.
Untuk mengakses dasbor lain, klik menu drop-down Beranda di sudut kiri atas halaman.
Untuk contoh penggunaan Grafana, lihat Membuat dasbor Grafana.
Mengakses pemberitahuan
Prometheus Alertmanager mengumpulkan pemberitahuan dari server Prometheus. Anda dapat melihat pemberitahuan ini di dasbor Grafana. Untuk melihat pemberitahuan, Anda perlu mengakses dasbor:
Penampung di Pod
alertmanager-0memproses port TCP 9093. Teruskan port lokal ke port 9093 di Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
Dari browser web, buka
http://localhost:50001.
Mengubah konfigurasi Prometheus Alertmanager
Anda dapat mengubah konfigurasi default Prometheus Alertmanager dengan mengedit
file monitoring.yaml cluster pengguna. Anda harus melakukannya jika ingin mengarahkan pemberitahuan ke tujuan tertentu, bukan menyimpannya di dasbor. Anda
dapat mempelajari cara mengonfigurasi Alertmanager dalam dokumentasi
Konfigurasi Prometheus.
Untuk mengubah konfigurasi Alertmanager, lakukan langkah-langkah berikut:
Buat salinan file manifes
monitoring.yamlcluster pengguna:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Untuk mengonfigurasi Alertmanager, buat perubahan pada kolom di bagian
spec.alertmanager.yml. Setelah selesai, simpan manifes yang diubah.Terapkan manifes ke cluster Anda:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Membuat dasbor Grafana
Anda telah men-deploy aplikasi yang mengekspos metrik, memverifikasi bahwa metrik diekspos, dan memverifikasi bahwa Prometheus mengambil metrik. Sekarang Anda dapat menambahkan metrik tingkat aplikasi ke dasbor Grafana kustom.
Untuk membuat dasbor Grafana, lakukan langkah-langkah berikut:
- Jika perlu, dapatkan akses ke Grafana.
- Dari Dasbor Beranda, klik menu drop-down Beranda di sudut kiri atas halaman.
- Dari menu sebelah kanan, klik Dasbor baru.
- Dari bagian Panel baru, klik Grafik. Dasbor grafik kosong akan muncul.
- Klik Judul panel, lalu klik Edit. Panel Grafik di bagian bawah akan membuka tab Metrik.
- Dari menu drop-down Sumber Data, pilih pengguna. Klik Tambahkan kueri, lalu masukkan
foodi kolom penelusuran. - Klik tombol Kembali ke dasbor di pojok kanan atas layar. Dasbor Anda akan ditampilkan.
- Untuk menyimpan dasbor, klik Simpan dasbor di pojok kanan atas layar. Pilih nama untuk dasbor, lalu klik Simpan.
Menonaktifkan Prometheus dan Grafana
Mulai versi 1.16, Prometheus dan Grafana tidak lagi dikontrol oleh kolom enablePrometheus dalam objek monitoring-sample.
Lihat Menggunakan Prometheus dan Grafana untuk mengetahui detailnya.
Contoh: Menambahkan metrik tingkat aplikasi ke dasbor Grafana
Bagian berikut akan memandu Anda menambahkan metrik untuk aplikasi. Di bagian ini, Anda akan menyelesaikan tugas-tugas berikut:
- Deploy aplikasi contoh yang mengekspos metrik bernama
foo. - Pastikan Prometheus mengekspos dan meng-scrap metrik.
- Buat dasbor Grafana kustom.
Men-deploy aplikasi contoh
Contoh aplikasi berjalan di satu Pod. Penampung Pod mengekspos
metrik, foo, dengan nilai konstan 40.
Buat manifes Pod berikut, pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Kemudian, terapkan manifes Pod ke cluster pengguna Anda:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Memverifikasi bahwa metrik ditampilkan dan diambil
Penampung di pod
prometheus-examplememproses port TCP 8080. Teruskan port lokal ke port 8080 di Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
Untuk memverifikasi bahwa aplikasi mengekspos metrik, jalankan perintah berikut:
curl localhost:50002/metrics | grep fooPerintah ini menampilkan output berikut:
# HELP foo Custom metric # TYPE foo gauge foo 40
Penampung di Pod
prometheus-0memproses port TCP 9090. Teruskan port lokal ke port 9090 di Pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Untuk memverifikasi bahwa Prometheus mengambil metrik, buka http://localhost:50003/targets, yang akan mengarahkan Anda ke Pod
prometheus-0di grup targetprometheus-io-pods.Untuk melihat metrik di Prometheus, buka http://localhost:50003/graph. Dari kolom penelusuran, masukkan
foo, lalu klik Jalankan. Halaman akan menampilkan metrik.
Mengonfigurasi resource kustom Stackdriver
Saat Anda membuat cluster, Google Distributed Cloud otomatis membuat resource kustom Stackdriver. Anda dapat mengedit spesifikasi di resource kustom untuk mengganti nilai default untuk permintaan dan batas CPU serta memori untuk komponen Stackdriver, dan Anda dapat mengganti ukuran penyimpanan dan class penyimpanan default secara terpisah.
Mengganti nilai default untuk permintaan dan batas CPU dan memori
Untuk mengganti setelan default ini, lakukan hal berikut:
Buka resource kustom Stackdriver di editor command line:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dengan KUBECONFIG adalah jalur ke file kubeconfig Anda untuk cluster. Cluster ini dapat berupa cluster admin atau cluster pengguna.
Di resource kustom Stackdriver, tambahkan kolom
resourceAttrOverridedi bagianspec:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYPerhatikan bahwa kolom
resourceAttrOverrideakan mengganti semua batas dan permintaan default yang ada untuk komponen yang Anda tentukan. Komponen berikut didukung olehresourceAttrOverride:- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
Contoh file terlihat seperti berikut:
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5GiSimpan perubahan dan keluar dari editor command line.
Periksa kondisi Pod Anda:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
Misalnya, Pod yang sehat terlihat seperti berikut:
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
Periksa spesifikasi Pod komponen untuk memastikan resource ditetapkan dengan benar.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
dengan
POD_NAMEadalah nama Pod yang baru saja Anda ubah. Misalnya,stackdriver-prometheus-k8s-0Responsnya akan terlihat seperti berikut:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Mengganti ukuran penyimpanan default
Untuk mengganti setelan default ini, lakukan hal berikut:
Buka resource kustom Stackdriver di editor command line:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Tambahkan kolom
storageSizeOverridedi bagianspec. Anda dapat menggunakan komponenstackdriver-prometheus-k8sataustackdriver-prometheus-app. Bagian ini menggunakan format ini:storageSizeOverride: STATEFULSET_NAME: SIZE
Contoh ini menggunakan statefulset
stackdriver-prometheus-k8sdan ukuran120Gi.apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiSimpan, lalu keluar dari editor command line.
Periksa kondisi Pod Anda:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Periksa spesifikasi Pod komponen untuk memastikan ukuran penyimpanan diganti dengan benar.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Responsnya akan terlihat seperti berikut:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Mengganti default kelas penyimpanan
Prasyarat
Anda harus membuat StorageClass yang ingin digunakan terlebih dahulu.
Untuk mengganti class penyimpanan default untuk volume persisten yang diklaim oleh komponen logging dan pemantauan:
Buka resource kustom Stackdriver di editor command line:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dengan KUBECONFIG adalah jalur ke file kubeconfig Anda untuk cluster. Cluster ini dapat berupa cluster admin atau cluster pengguna.
Tambahkan kolom
storageClassNamedi bagianspec:storageClassName: STORAGECLASS_NAME
Perhatikan bahwa kolom
storageClassNamemenggantikan class penyimpanan default yang ada, dan berlaku untuk semua komponen logging dan pemantauan dengan volume persisten yang diklaim. Contoh file terlihat seperti berikut:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Simpan perubahan.
Periksa kondisi Pod Anda:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Misalnya, Pod yang sehat terlihat seperti berikut:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Periksa spesifikasi Pod komponen untuk memastikan class penyimpanan ditetapkan dengan benar.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Misalnya, menggunakan set stateful
stackdriver-prometheus-k8s, responsnya akan terlihat seperti berikut:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Menonaktifkan metrik yang dioptimalkan
Secara default, agen metrik yang berjalan di cluster mengumpulkan dan melaporkan kumpulan metrik penampung, kubelet, dan kube-state-metrics yang dioptimalkan ke Stackdriver. Jika Anda memerlukan metrik tambahan, sebaiknya temukan penggantinya dari daftar metrik GKE Enterprise.
Berikut beberapa contoh penggantian yang dapat Anda gunakan:
| Metrik yang dinonaktifkan | Penggantian |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Untuk menonaktifkan setelan default metrik kube-state-metrics yang dioptimalkan (tidak direkomendasikan), lakukan hal berikut:
Buka resource kustom Stackdriver di editor command line:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
dengan KUBECONFIG adalah jalur ke file kubeconfig Anda untuk cluster. Cluster ini dapat berupa cluster admin atau cluster pengguna.
Tetapkan kolom
optimizedMetricskefalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class Simpan perubahan, lalu keluar dari editor command line.
Masalah umum: Kondisi error Cloud Monitoring
(ID Masalah 159761921)
Dalam kondisi tertentu, pod Cloud Monitoring default, yang di-deploy secara default di setiap cluster baru, dapat menjadi tidak responsif.
Saat cluster diupgrade, misalnya, data penyimpanan dapat menjadi
rusak saat pod di statefulset/prometheus-stackdriver-k8s dimulai ulang.
Secara khusus, pemantauan pod stackdriver-prometheus-k8s-0 dapat
terperangkap dalam loop saat data yang rusak mencegah prometheus-stackdriver-sidecar
menulis ke penyimpanan cluster PersistentVolume.
Anda dapat mendiagnosis dan memulihkan error secara manual dengan mengikuti langkah-langkah di bawah.
Mendiagnosis kegagalan Cloud Monitoring
Jika pod pemantauan gagal, log akan melaporkan hal berikut:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Memulihkan dari error Cloud Monitoring
Untuk memulihkan Cloud Monitoring secara manual:
Hentikan pemantauan cluster. Skalakan operator
stackdriverke bawah untuk mencegah rekonsiliasi pemantauan:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Hapus workload pipeline pemantauan:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Hapus PersistentVolumeClaims (PVC) pipeline pemantauan:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Mulai ulang pemantauan cluster. Menskalakan operator stackdriver untuk menginstal ulang pipeline pemantauan baru dan melanjutkan rekonsiliasi:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1