本文档介绍了如何为 Google Distributed Cloud for VMware(纯软件)中的系统组件配置日志记录和监控。
默认情况下,Cloud Logging、Cloud Monitoring 和 Google Cloud Managed Service for Prometheus 处于启用状态。
如需详细了解选项,请参阅日志记录和监控概览。
受监控的资源
受监控的资源是 Google 如何表示资源(如集群、节点、Pod 和容器)。如需了解详情,请参阅 Cloud Monitoring 的受监控的资源类型文档。
如需查询日志和指标,您需要了解以下资源标签:
project_id:集群的日志记录监控项目的项目 ID。您在集群配置文件的stackdriver.projectID字段中提供了此值。location:您要在其中路由和存储 Cloud Monitoring 指标的 Google Cloud 区域。在安装期间,您需要在集群配置文件的stackdriver.clusterLocation字段中指定区域。我们建议您选择靠近您的本地数据中心的区域。您可以在日志路由器配置中指定 Cloud Logging 日志路由和存储位置。如需详细了解日志路由,请参阅路由和存储概览。
cluster_name:您在创建集群时选择的集群名称。您可以通过检查 Stackdriver 自定义资源来检索管理员或用户集群的
cluster_name值:kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
其中
CLUSTER_KUBECONFIG是需要集群名称的管理员集群或用户集群的 kubeconfig 文件的路径。
日志和指标路由
Stackdriver 日志转发器 (stackdriver-log-forwarder) 会将每个节点机器的日志发送到 Cloud Logging。同样,GKE 指标代理 (gke-metrics-agent) 会将每个节点机器的指标发送到 Cloud Monitoring。在发送日志和指标之前,Stackdriver Operator (stackdriver-operator) 会将 stackdriver 自定义资源的 clusterLocation 字段中的值附加到每个日志条目和指标,然后再将它们路由到 Google Cloud。此外,日志和指标还与 stackdriver 自定义资源规范 (spec.projectID) 中指定的 Google Cloud 项目相关联。stackdriver 资源会在创建集群时从集群资源的 clusterOperations 部分的 stackdriver.clusterLocation 和 stackdriver.projectID 字段获取 clusterLocation 和 projectID 字段的值。
Stackdriver 代理发送的所有指标和日志条目都会路由到全球注入端点。从此处,数据会转发到可访问的最近区域级 Google Cloud 端点,以确保数据传输的可靠性。
全球端点收到指标或日志条目后,接下来发生的情况取决于服务:
日志路由配置方式:当日志记录端点收到日志消息时,Cloud Logging 会通过日志路由器传递消息。日志路由器配置中的接收器和过滤器决定了如何路由消息。您可以将日志条目路由到目标位置(例如用于存储日志条目的区域级 Logging 存储桶),也可以路由到 Pub/Sub。如需详细了解日志路由的工作原理以及如何进行配置,请参阅路由和存储概览。
此路由流程中不考虑
stackdriver自定义资源中的clusterLocation字段或集群规范中的clusterOperations.location字段。对于日志,clusterLocation仅用于为日志条目添加标签,这对于在 Logs Explorer 中进行过滤很有帮助。指标路由配置方式:当指标端点收到指标条目时,Cloud Monitoring 会自动将该条目路由到指标指定的位置。指标中的位置来自
stackdriver自定义资源中的clusterLocation字段。规划配置:配置 Cloud Logging 和 Cloud Monitoring 时,请配置日志路由器,并使用最能满足您需求的位置来指定适当的
clusterLocation。例如,如果您希望日志和指标发送到同一位置,请将clusterLocation设置为日志路由器为您的 Google Cloud 项目使用的同一 Google Cloud 区域。根据需要更新配置:您可以根据业务要求(例如灾难恢复计划)随时更改日志和指标的目标位置设置。对 Google Cloud 和
stackdriver自定义资源的clusterLocation字段中的日志路由器配置所做的更改会立即生效。
使用 Cloud Logging
您无需执行任何操作即可为集群启用 Cloud Logging。不过,您必须指定要在其中查看日志的 Google Cloud 项目。您可以在集群配置文件的 stackdriver 部分中指定 Google Cloud 项目。
您可以使用 Google Cloud 控制台中的 Logs Explorer 来访问日志。例如,要访问容器的日志,请执行以下操作:
- 在您项目的 Google Cloud 控制台中打开 Logs Explorer。
- 通过以下方式查找容器的日志:
- 点击左上角的日志目录下拉框,然后选择 Kubernetes 容器。
- 选择集群名称,然后选择命名空间,然后从层次结构中选择容器。
查看引导集群中控制器的日志
-
在 Google Cloud 控制台中,转到 Logs Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为 Logging 的结果。
如需查看引导集群中控制器的所有日志,请在查询编辑器中运行以下查询:
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
如需查看特定 Pod 的日志,请修改查询以添加相应 Pod 的名称:
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
使用 Cloud Monitoring
您无需执行任何操作即可为集群启用 Cloud Monitoring。不过,您必须指定要在其中查看指标的 Google Cloud 项目。您可以在集群配置文件的 stackdriver 部分中指定 Google Cloud 项目。
您可以使用 Metrics Explorer,从 1500 多个指标中进行选择。如需访问 Metrics Explorer,请执行以下操作:
在 Google Cloud 控制台中,选择 Monitoring,或使用以下按钮:
选择资源 > Metrics Explorer。
您还可以在 Google Cloud 控制台的信息中心内查看指标。如需了解如何创建信息中心和查看指标,请参阅创建信息中心。
查看舰队级监控数据
如需通过 Cloud Monitoring 数据(包括 Google Distributed Cloud 集群)全面了解舰队的资源利用率,您可以使用 Google Cloud 控制台中的 Google Kubernetes Engine 概览。如需了解详情,请参阅通过 Google Cloud 控制台管理集群。
默认 Cloud Monitoring 配额限制
Google Distributed Cloud 监控功能针对每个项目的默认限制为每分钟 6,000 次 API 调用。如果超出此限制,系统可能不会显示您的指标。 如果您需要更高的监控限制,请通过 Google Cloud 控制台申请。
使用 Managed Service for Prometheus
Google Cloud Managed Service for Prometheus 是 Cloud Monitoring 的一部分,默认情况下可供使用。Managed Service for Prometheus 的优势包括:
您可以继续使用基于 Prometheus 的现有监控,而无需更改提醒和 Grafana 信息中心。
如果您同时使用 GKE 和 Google Distributed Cloud,则可以对所有集群上的指标使用相同的 PromQL。您还可以使用 Google Cloud 控制台的 Metrics Explorer 中的 PROMQL 标签页。
启用和停用 Managed Service for Prometheus
从 Google Distributed Cloud 1.30.0-gke.1930 版开始,Managed Service for Prometheus 始终处于启用状态。在早期版本中,您可以修改 Stackdriver 资源 stackdriver,以启用或停用 Managed Service for Prometheus。如需针对 1.30.0-gke.1930 之前的集群版本停用 Managed Service for Prometheus,请将 stackdriver 资源中的 spec.featureGates.enableGMPForSystemMetrics 设置为 false。
查看指标数据
启用 Managed Service for Prometheus 后,以下组件的指标因在 Cloud Monitoring 中的存储和查询方式而具有不同的格式:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet 和 cadvisor
- kube-state-metrics
- node-exporter
在新格式中,您可以使用 Prometheus 查询语言 (PromQL) 查询上述指标。
PromQL 示例:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
使用 Managed Service for Prometheus 配置 Grafana 信息中心
如需将 Grafana 与来自 Managed Service for Prometheus 的指标数据搭配使用,请按照使用 Grafana 进行查询中的步骤进行身份验证并配置 Grafana 数据源,以查询来自 Managed Service for Prometheus 的数据。
GitHub 上的 anthos-samples 代码库中提供了一组示例 Grafana 信息中心。如需安装示例信息中心,请执行以下操作:
下载示例
.json文件:git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
如果您创建的 Grafana 数据源的名称与
Managed Service for Prometheus不同,请更改所有.json文件中的datasource字段:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
将 [DATASOURCE_NAME] 替换为 Grafana 中指向 Prometheus
frontend服务的数据源名称。通过浏览器访问 Grafana 界面,然后在信息中心菜单下选择 + 导入。
上传
.json文件,或复制并粘贴文件内容,然后选择加载。文件内容成功加载后,选择导入。您还可以根据需要在导入之前更改信息中心名称和 UID。
如果 Google Distributed Cloud 和数据源配置正确,则导入的信息中心应该会成功加载。例如,以下屏幕截图显示了
cluster-capacity.json配置的信息中心。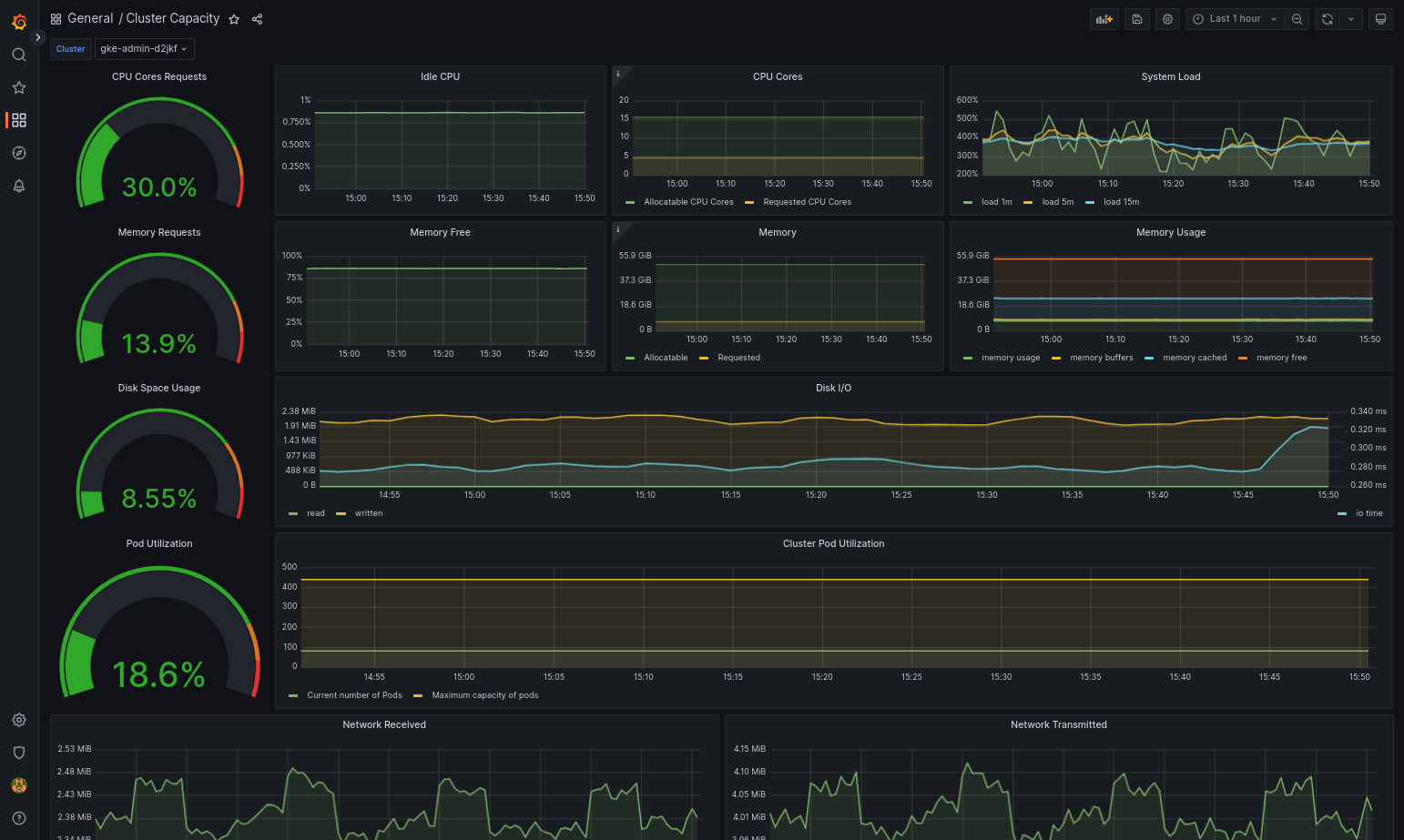
其他资源
如需详细了解 Managed Service for Prometheus,请参阅以下内容:
使用 Prometheus 和 Grafana
从 1.16 版开始,Prometheus 和 Grafana 在新创建的集群中不可用。我们建议您使用 Managed Service for Prometheus 作为集群内监控的替代工具。
如果您将启用了 Prometheus 和 Grafana 的 1.15 集群升级到 1.16,则 Prometheus 和 Grafana 将继续按原样工作,但不再更新,也无法获得安全补丁。
如果您想在升级到 1.16 后删除所有 Prometheus 和 Grafana 资源,请运行以下命令:
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
作为使用早期版本的 Google Distributed Cloud 中包含的 Prometheus 和 Grafana 组件的替代方案,您可以切换到 Prometheus 和 Grafana 的开源社区版本。
已知问题
在用户集群中,升级时会自动停用 Prometheus 和 Grafana。不过,配置和指标数据不会丢失。
如需解决此问题,请在升级后打开 monitoring-sample 进行修改,并将 enablePrometheus 设置为 true。
从 Grafana 信息中心访问监控指标
Grafana 会显示从您的集群收集的指标。如需查看这些指标,您需要访问 Grafana 的信息中心:
获取在用户集群的
kube-system命名空间中运行的 Grafana pod 的名称:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
其中,[USER_CLUSTER_KUBECONFIG] 是用户集群的 kubeconfig 文件。
Grafana pod 有一个侦听 TCP localhost 端口 3000 的 HTTP 服务器。您可以将本地端口转发到 pod 中的端口 3000,以便通过网络浏览器查看 Grafana 的信息中心。
例如,假设 pod 的名称为
grafana-0。如需将端口 50000 转发到 pod 中的端口 3000,请输入以下命令:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
在网络浏览器中,转到
http://localhost:50000。在登录页面,输入
admin作为用户名和密码。如果登录成功,系统会提示您更改密码。更改默认密码后,系统会加载用户集群的 Grafana 首页信息中心。
如需访问其他信息中心,请点击页面左上角的首页下拉菜单。
如需查看使用 Grafana 的示例,请参阅创建 Grafana 信息中心。
访问提醒
Prometheus Alertmanager 会从 Prometheus 服务器收集提醒。您可以在 Grafana 信息中心查看这些提醒。如需查看提醒,您需要访问信息中心:
alertmanager-0pod 中的容器侦听 TCP 端口 9093。将本地端口转发到 pod 中的 9093 端口:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
在网络浏览器中,转到
http://localhost:50001。
更改 Prometheus Alertmanager 配置
您可以通过修改用户集群的 monitoring.yaml 文件来更改 Prometheus Alertmanager 的默认配置。如果您希望将提醒指向特定目标位置,而不是将其保留在信息中心,则应执行此操作。您可以在 Prometheus 的配置文档中了解如何配置 Alertmanager。
如需更改 Alertmanager 配置,请执行以下步骤:
制作用户集群的
monitoring.yaml清单文件的副本:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
如需配置 Alertmanager,请更改
spec.alertmanager.yml下的字段。完成后,保存已更改的清单。将清单应用到您的集群:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
创建 Grafana 信息中心
您已经部署了一个公开指标的应用,验证该指标是否已公开,并验证 Prometheus 是否会抓取该指标。现在,您可以将应用级指标添加到自定义 Grafana 信息中心。
如需创建 Grafana 信息中心,请执行以下步骤:
- 如有必要,请访问 Grafana。
- 在首页信息中心内,点击页面左上角的首页下拉菜单。
- 在右侧菜单中,点击新信息中心。
- 在新面板部分中,点击图表。系统会显示一个空的图表信息中心。
- 点击面板标题,然后点击修改。底部的图表面板将打开并显示指标标签页。
- 从数据源下拉菜单中选择用户。点击添加查询,然后在搜索字段中输入
foo。 - 点击屏幕右上角的返回信息中心按钮。此时会显示您的信息中心。
- 如需保存信息中心,请点击屏幕右上角的保存信息中心。为信息中心选择一个名称,然后点击保存。
停用 Prometheus 和 Grafana
从 1.16 版开始,Prometheus 和 Grafana 不再由 monitoring-sample 对象中的 enablePrometheus 字段控制。如需了解详情,请参阅使用 Prometheus 和 Grafana。
示例:将应用级指标添加到 Grafana 信息中心
以下部分将引导您逐步添加应用的指标。在此部分中,您需要完成以下任务:
- 部署一个示例应用以公开名为
foo的指标。 - 验证 Prometheus 是否会公开并抓取该指标。
- 创建一个自定义 Grafana 信息中心。
部署示例应用
示例应用在单个 pod 中运行。pod 的容器公开了 foo 指标,其常量值为 40。
创建以下 pod 清单 pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
然后将 pod 清单应用到您的用户集群:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
验证指标是否已公开并已抓取
prometheus-examplepod 中的容器侦听 TCP 端口 8080。将本地端口转发到 pod 中的端口 8080:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
如需验证应用是否公开指标,请运行以下命令:
curl localhost:50002/metrics | grep foo该命令返回以下输出:
# HELP foo Custom metric # TYPE foo gauge foo 40
prometheus-0pod 中的容器侦听 TCP 端口 9090。将本地端口转发到 pod 中的端口 9090:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
如需验证 Prometheus 是否正在抓取指标,请转到 http://localhost:50003/targets,此网址应该会将您转到
prometheus-io-pods目标组下的prometheus-0pod。如需查看 Prometheus 格式的指标,请转到 http://localhost:50003/graph。在搜索字段中输入
foo,然后点击执行。该页面应该会显示相应指标。
配置 Stackdriver 自定义资源
创建集群时,Google Distributed Cloud 会自动创建 Stackdriver 自定义资源。您可以在自定义资源中修改规范,以替换 Stackdriver 组件中 CPU 和内存请求的默认值和限制,也可以单独替换默认存储空间大小和存储类别。
替换请求的默认值以及 CPU 和内存的限制
如需替换这些默认设置,请执行以下操作:
在命令行编辑器中打开 Stackdriver 自定义资源:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
其中,KUBECONFIG 是集群的 kubeconfig 文件的路径。该集群可以是管理员集群或用户集群。
在 Stackdriver 自定义资源中,在
spec部分下添加resourceAttrOverride字段:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITY请注意,
resourceAttrOverride字段将替换指定组件的所有现有默认限制和请求。resourceAttrOverride支持以下组件:- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
示例文件如下所示:
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5Gi保存更改并退出命令行编辑器。
检查 Pod 的运行状况:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
例如,运行状况良好的 Pod 如下所示:
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
检查组件的 Pod 规范,确保资源设置正确。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
其中,
POD_NAME是您刚刚更改的 Pod 的名称。例如stackdriver-prometheus-k8s-0回答如下所示:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
替换存储空间大小默认值
如需替换这些默认设置,请执行以下操作:
在命令行编辑器中打开 Stackdriver 自定义资源:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
在
spec部分下添加storageSizeOverride字段。您可以使用组件stackdriver-prometheus-k8s或stackdriver-prometheus-app。此部分将采用如下格式:storageSizeOverride: STATEFULSET_NAME: SIZE
此示例使用有状态集
stackdriver-prometheus-k8s和大小120Gi。apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120Gi保存并退出命令行编辑器。
检查 Pod 的运行状况:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
检查组件的 Pod 规范,确保已正确替换存储空间大小。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
回答如下所示:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
替换存储类别默认值
前提条件
您必须先创建要使用的存储类别。
如需替换 Logging 和 Monitoring 组件声明的永久性卷的默认存储类别,请执行以下操作:
在命令行编辑器中打开 Stackdriver 自定义资源:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
其中,KUBECONFIG 是集群的 kubeconfig 文件的路径。该集群可以是管理员集群或用户集群。
在
spec部分下添加storageClassName字段:storageClassName: STORAGECLASS_NAME
请注意,
storageClassName字段会替换现有默认存储类别,并应用于声明了永久性卷的所有 Logging 和 Monitoring 组件。示例文件如下所示:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class 保存更改。
检查 Pod 的运行状况:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
例如,运行状况良好的 Pod 如下所示:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
检查组件的 Pod 规范,确保正确设置了存储类别。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
例如,使用有状态集
stackdriver-prometheus-k8s时,响应将如下所示:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
停用优化的指标
默认情况下,集群中运行的指标代理会收集一组优化的容器、kubelet 和 kube-state-metrics 指标并报告给 Stackdriver。如果您需要其他指标,我们建议您从 Google Distributed Cloud 指标列表中寻找替代指标。
以下是一些您可能使用的替代指标示例:
| 已停用的指标 | 替代指标 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
如需停用优化的 kube-state-metrics 指标默认设置(不推荐),请执行以下操作:
在命令行编辑器中打开 Stackdriver 自定义资源:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
其中,KUBECONFIG 是集群的 kubeconfig 文件的路径。该集群可以是管理员集群或用户集群。
将
optimizedMetrics字段设置为false:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class 保存更改并退出命令行编辑器。
已知问题:Cloud Monitoring 错误条件
(问题 ID 159761921)
在某些情况下,在每个新集群中部署的默认 Cloud Monitoring pod 可能会无响应。例如,升级集群后,重启 statefulset/prometheus-stackdriver-k8s 中的 pod 时,存储数据可能会损坏。
具体而言,当损坏的数据阻止 prometheus-stackdriver-sidecar 向集群存储空间 PersistentVolume 写入内容时,监控 pod stackdriver-prometheus-k8s-0 可能会陷入循环。
您可以按照以下步骤手动诊断并恢复错误。
诊断 Cloud Monitoring 故障
如果监控 pod 失败,日志将报告以下内容:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
从 Cloud Monitoring 错误恢复
如需手动恢复 Cloud Monitoring,请执行以下操作:
停止集群监控。缩减
stackdriver运算符以防止监控协调:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
删除监控流水线工作负载:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
删除监控流水线 PersistentVolumeClaims (PVC):
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
重启集群监控。扩展 Stackdriver 运算符以重新安装新的监控流水线并恢复协调:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1