En este instructivo, se presenta una solución lista para usar que usa Google Distributed Cloud y el Sincronizador de configuración para implementar clústeres de Kubernetes en el perímetro a gran escala. Este instructivo es para desarrolladores y operadores de plataforma. Debes estar familiarizado con las siguientes tecnologías y conceptos:
- Guías de Ansible.
- Implementaciones perimetrales y sus desafíos
- Cómo trabajar con un proyecto de Google Cloud.
- Implementa una aplicación web en contenedor
- Interfaces de líneas de comandos de
gcloudykubectl
En este instructivo, se usan máquinas virtuales (VM) de Compute Engine para emular nodos implementados en el perímetro y una aplicación de punto de venta de muestra como carga de trabajo perimetral. Google Distributed Cloud y el Sincronizador de configuración proporcionan administración centralizada y control para tu clúster perimetral. El Sincronizador de configuración extrae de forma dinámica los parámetros de configuración nuevos de GitHub y aplica estas políticas y parámetros de configuración a tus clústeres.
Arquitectura de implementación perimetral
Una implementación perimetral de venta minorista es una buena manera de ilustrar la arquitectura que se usa en una implementación típica de Google Distributed Cloud.
Una tienda física de venta minorista es el punto de interacción más cercano entre una unidad de negocios empresarial y el consumidor. Los sistemas de software dentro de las tiendas deben ejecutar sus cargas de trabajo, recibir actualizaciones oportunas y, además, informar métricas críticas aisladas del sistema de administración central de la empresa. Además, estos sistemas de software deben diseñarse de modo que se puedan expandir a más ubicaciones de tiendas en el futuro. Si bien Google Distributed Cloud cumple con todos estos requisitos de los sistemas de software para tiendas, el perfil perimetral habilita un caso de uso importante: las implementaciones en entornos con recursos de hardware limitados, como la vidriera de una tienda minorista.
En el siguiente diagrama, se muestra una implementación de Google Distributed Cloud que usa el perfil perimetral en una tienda de venta minorista:
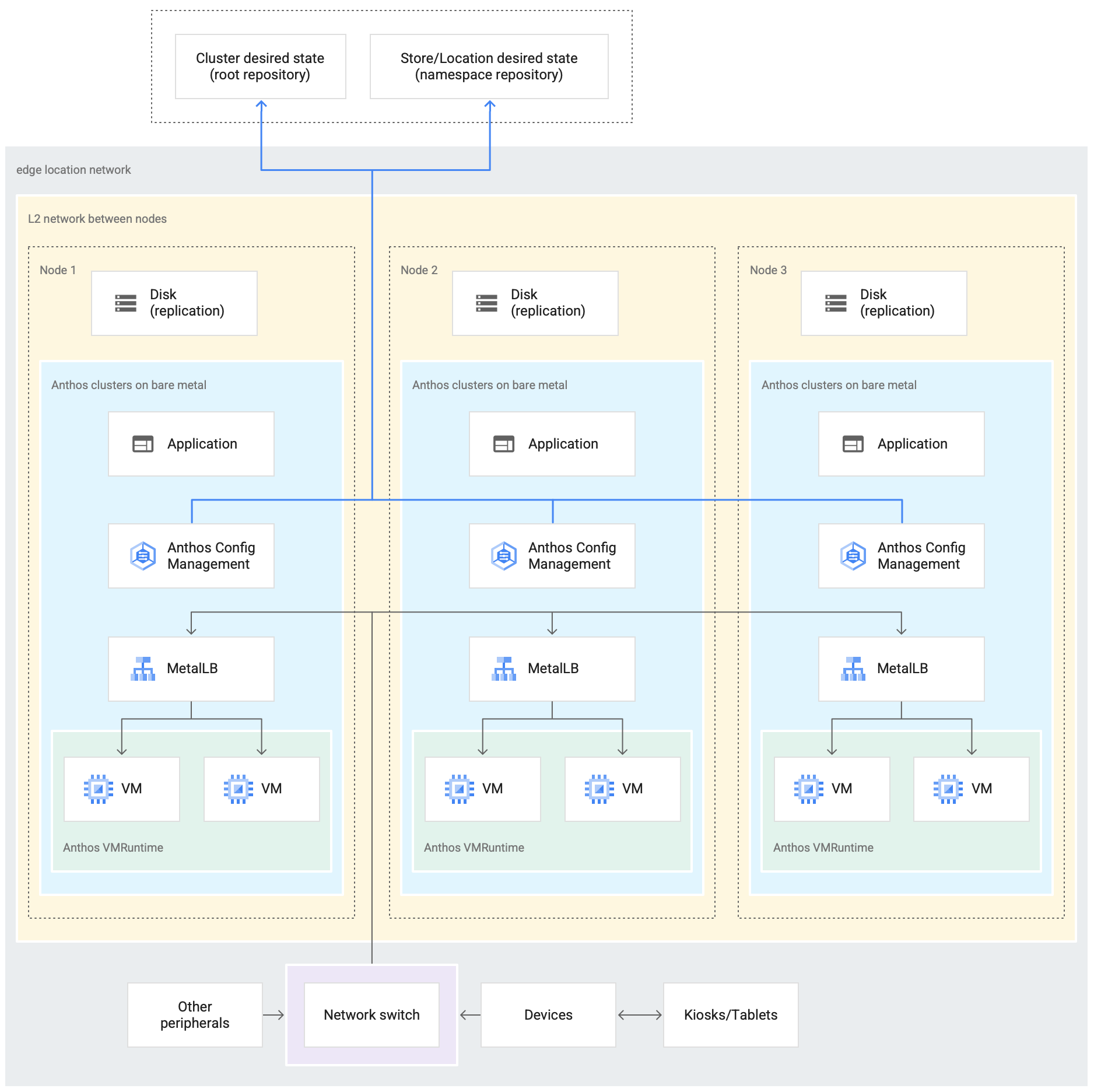
En el diagrama anterior, se muestra una tienda física de venta minorista típica. La tienda tiene dispositivos inteligentes, como lectores de tarjetas, máquinas de punto de venta, impresoras y cámaras.
La tienda también tiene tres dispositivos físicos de hardware de procesamiento (etiquetados Node 1, Node 2 y Node 3). Todos estos dispositivos están conectados a un switch de red central. Por lo tanto, los tres dispositivos de procesamiento están conectados entre sí a través de una red de capa 2. Los dispositivos de procesamiento conectados en red conforman la infraestructura física.
Google Distributed Cloud se ejecuta dentro de cada uno de los tres dispositivos de procesamiento. Estos dispositivos también tienen su propio almacenamiento en disco y están configurados para la replicación de datos entre ellos para tener alta disponibilidad.
En el diagrama, también se muestran los siguientes componentes clave que forman parte de una implementación de Google Distributed Cloud:
- El componente marcado como MetalLB es el balanceador de cargas en paquetes que se implementa con Google Distributed Cloud.
- El componente del Sincronizador de configuración permite sincronizar el estado del clúster con los repositorios de origen. Es un complemento opcional muy recomendado que requiere instalación y configuración por separado. Si deseas obtener más información para configurar el Sincronizador de configuración y la nomenclatura diferente, consulta la documentación del Sincronizador de configuración.
El repositorio raíz y el repositorio de espacio de nombres que se muestran en la parte superior del diagrama fuera de la ubicación de la tienda representan dos repositorios de origen.
Los cambios del clúster se envían a estos repositorios centrales de código fuente. Las implementaciones de Google Distributed Cloud en varias ubicaciones perimetrales extraen actualizaciones de los repositorios de origen. Este comportamiento se representa con las flechas que conectan los dos repositorios del diagrama con los componentes del Sincronizador de configuración dentro del clúster de GKE en Bare Metal que se ejecuta en los dispositivos.
Otro componente clave que se muestra como parte del clúster es el entorno de ejecución de VM en GDC. El entorno de ejecución de VM en GDC permite ejecutar las cargas de trabajo existentes basadas en VM dentro del clúster sin necesidad de crear contenedores. En la documentación del entorno de ejecución de VM en GDC, se explica cómo habilitarlo e implementar tus cargas de trabajo de VM en el clúster.
El componente marcado como Aplicación (Application) denota software implementado en el clúster por la tienda de venta minorista. La aplicación de punto de venta que se ve en los kioscos de una tienda minorista podría ser un ejemplo de esta aplicación.
Los cuadros en la parte inferior del diagrama representan los numerosos dispositivos (como kioscos, tablets o cámaras) dentro de una tienda minorista, los cuales están conectados a un interruptor de red central. Las herramientas de redes locales dentro del almacén permiten que las aplicaciones que se ejecutan dentro de la implementación de Google Distributed Cloud lleguen a estos dispositivos.
En la siguiente sección, verás la emulación de esta implementación de tienda minorista en Google Cloud con las VM de Compute Engine. Esta emulación es la que usarás en el instructivo que sigue para experimentar con Google Distributed Cloud.
Implementación perimetral emulada en Google Cloud
En el siguiente diagrama, se muestra todo lo que configuraste en Google Cloud en este instructivo. Este diagrama se correlaciona con el diagrama de la tienda minorista de la sección anterior. Esta implementación representa una ubicación perimetral emulada en la que se implementa la aplicación de punto de venta. En la arquitectura, también se muestra una carga de trabajo de la aplicación de muestra de punto de venta simple que usarás en este instructivo. Puedes acceder a la aplicación de punto de venta dentro del clúster con un navegador web como kiosco.
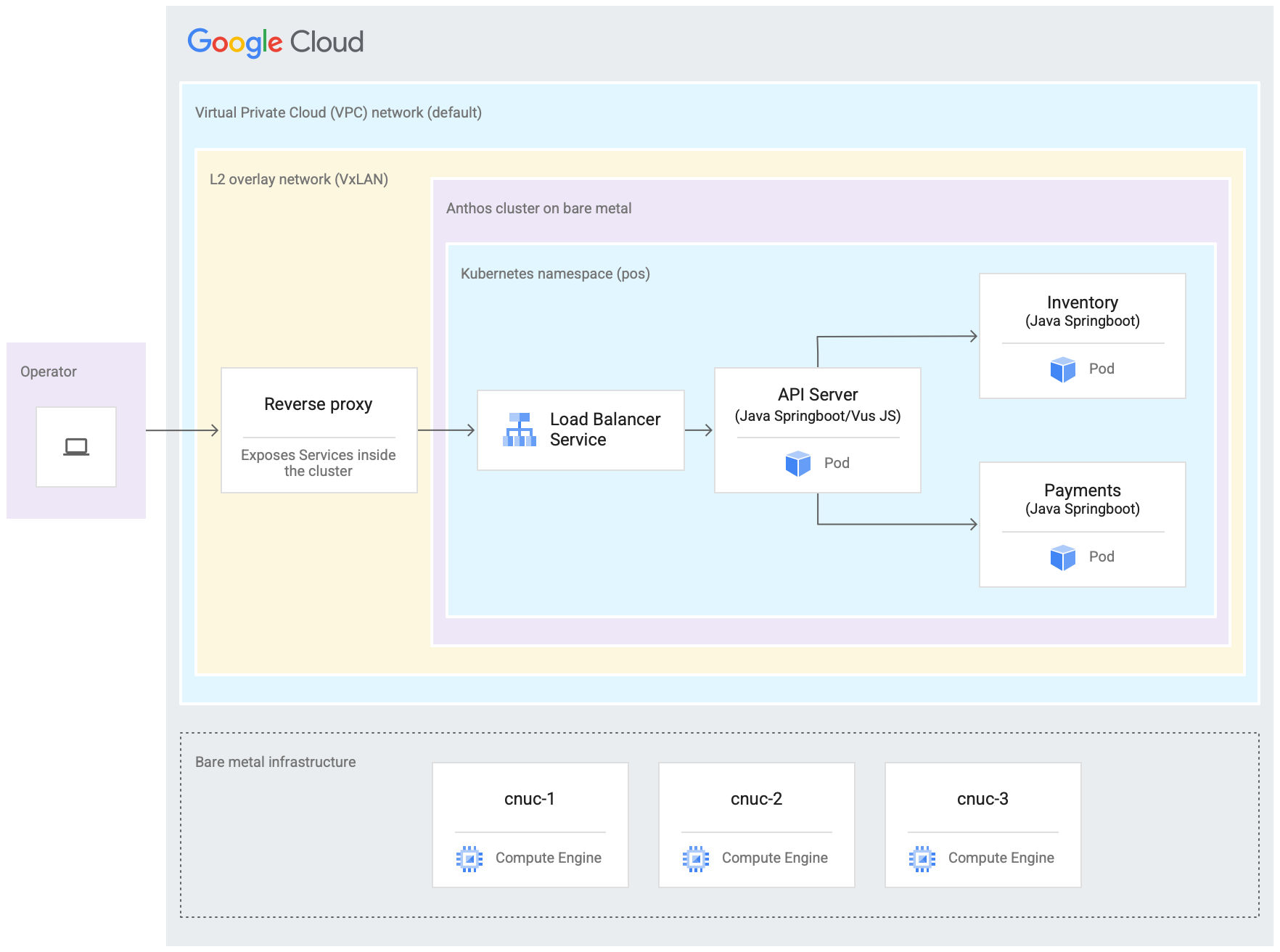
Las tres máquinas virtuales (VM) de Compute Engine del diagrama anterior representan el hardware físico (o nodos) en una ubicación perimetral típica. Este hardware se conectaría junto con conmutadores de red para formar la infraestructura de equipos físicos. En nuestro entorno emulado de Google Cloud, estas VM están conectadas entre sí a través de la red predeterminada de la nube privada virtual (VPC) en el proyecto de Google Cloud.
En una instalación típica de Google Distributed Cloud, puedes configurar tus propios balanceadores de cargas. Sin embargo, para este instructivo no configurarás un balanceador de cargas externo. En su lugar, usa el balanceador de cargas de MetalLB en paquete que se instala con Google Distributed Cloud. El balanceador de cargas de MetalLB en paquetes requiere conectividad de red de capa 2 entre los nodos. Por lo tanto, la conectividad de capa 2 entre las VM de Compute Engine se habilita mediante la creación de una red de superposición VxLAN sobre la red predeterminada de nube privada virtual (VPC).
Dentro del rectángulo etiquetado como "L2 Overlay network (VxLAN)", se muestran los componentes de software que se ejecutan dentro de las tres VM de Compute Engine. Este rectángulo incluye el clúster de GKE en Bare Metal y un proxy inverso. El clúster se representa con el rectángulo “Google Distributed Cloud”. Este rectángulo que representa el clúster incluye otro rectángulo marcado como "Espacio de nombres de Kubernetes (pos)". Esto representa un espacio de nombres de Kubernetes dentro del clúster. Todos los componentes dentro de este espacio de nombres de Kubernetes conforman la aplicación de punto de venta que se implementa en el clúster de GKE en Bare Metal. La aplicación de punto de venta tiene tres microservicios: Servidor de la API, Inventario y Pagos. Juntos, todos estos componentes representan una “aplicación” que se muestra en el diagrama anterior de la arquitectura de lanzamiento de Edge.
No se puede acceder directamente al balanceador de cargas de MetalLB integrado del clúster de GKE en Bare Metal desde fuera de las VMs. En el diagrama, se muestra un proxy inverso de NGINX configurado para ejecutarse dentro de las VM y enrutar el tráfico que llega a las VM de Compute Engine hacia el balanceador de cargas. Esta es solo una solución alternativa para los fines de este instructivo, en el que los nodos perimetrales se emulan con las VM de Google Cloud Compute Engine. En una ubicación perimetral real, esto se puede hacer con la configuración de red adecuada.
Objetivos
- Usa VMs de Compute Engine para emular una infraestructura sin sistema operativo que se ejecuta en una ubicación perimetral.
- Crea un clúster de GKE en Bare Metal en la infraestructura perimetral emulada.
- Conectar y registrar el clúster con Google Cloud
- Implementar una carga de trabajo de aplicación de punto de venta de muestra en el clúster de GKE en Bare Metal
- Usa la consola de Google Cloud para verificar y supervisar la aplicación de punto de venta que opera en la ubicación perimetral.
- Usa el Sincronizador de configuración para actualizar la aplicación de punto de venta que se ejecuta en el clúster de GKE en Bare Metal.
Antes de comenzar
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Instala e initialize Google Cloud CLI.
Bifurca y clona el repositorio de anthos-samples
Todas las secuencias de comandos usadas en este instructivo se almacenan en el repositorio anthos-samples. La estructura de carpetas en /anthos-bm-edge-deployment/acm-config-sink se organiza de acuerdo con lo que espera el Sincronizador de configuración.
Clona este repositorio en tu propia cuenta de GitHub antes de continuar con los siguientes pasos.
Si aún no tienes una cuenta de GitHub, crea una.
Crea un token de acceso personal para usar en la configuración del Sincronizador de configuración. Esto es necesario para que los componentes del Sincronizador de configuración en el clúster se autentiquen con tu cuenta de GitHub cuando intenten sincronizar cambios nuevos.
- Selecciona solo el permiso
public_repo. - Guarda el token de acceso que creaste en un lugar seguro para usarlo más adelante.
- Selecciona solo el permiso
Bifurca el repositorio
anthos-samplesen tu propia cuenta de GitHub:- Ve al repositorio anhos-samples.
- Haz clic en el ícono Fork ubicado en la esquina superior derecha de la página.
- Haz clic en la cuenta de usuario de GitHub en la que deseas bifurcar el repositorio. Se te redireccionará de forma automática a la página con la versión bifurcada del repositorio
anthos-samples.
Abre una terminal en tu entorno local.
Clona el repositorio bifurcado mediante la ejecución del siguiente comando, en el que GITHUB_USERNAME es el nombre de usuario de tu cuenta de GitHub:
git clone https://github.com/GITHUB_USERNAME/anthos-samples cd anthos-samples/anthos-bm-edge-deployment
Configura el entorno de la estación de trabajo
Para completar la implementación perimetral que se describe en este documento, necesitas una estación de trabajo con acceso a Internet y las siguientes herramientas instaladas:
- Docker
- Herramienta de interfaz de línea de comandos de Envsubst (por lo general, preinstalada en Linux y otros SO similares a Unix)
Ejecuta todos los comandos del instructivo en la estación de trabajo que configurarás en esta sección.
En tu estación de trabajo, inicializa las variables de entorno en una nueva instancia de shell:
export PROJECT_ID="PROJECT_ID" export REGION="us-central1" export ZONE="us-central1-a" # port on the admin Compute Engine instance you use to set up an nginx proxy # this allows to reach the workloads inside the cluster via the VM IP export PROXY_PORT="8082" # should be a multiple of 3 since N/3 clusters are created with each having 3 nodes export GCE_COUNT="3" # url to the fork of: https://github.com/GoogleCloudPlatform/anthos-samples export ROOT_REPO_URL="https://github.com/GITHUB_USERNAME/anthos-samples" # this is the username used to authenticate to your fork of this repository export SCM_TOKEN_USER="GITHUB_USERNAME" # access token created in the earlier step export SCM_TOKEN_TOKEN="ACCESS_TOKEN"Reemplaza los siguientes valores:
- PROJECT_ID: tu ID del proyecto de Google Cloud.
- GITHUB_USERNAME: es tu nombre de usuario de GitHub.
- ACCESS_TOKEN: Es el token de acceso personal que creaste para tu repositorio de GitHub.
Mantén los valores predeterminados de las otras variables de entorno. Se explican en las siguientes secciones.
En tu estación de trabajo, inicializa Google Cloud CLI:
gcloud config set project "${PROJECT_ID}" gcloud services enable compute.googleapis.com gcloud config set compute/region "${REGION}" gcloud config set compute/zone "${ZONE}"En tu estación de trabajo, crea la cuenta de servicio de Google Cloud para las instancias de Compute Engine. Esta secuencia de comandos crea el archivo de claves JSON para la cuenta de servicio nueva en
<REPO_ROOT>/anthos-bm-edge-deployment/build-artifacts/consumer-edge-gsa.json. También configura el llavero de claves y la clave de Cloud Key Management Service para la encriptación de claves privadas SSH../scripts/create-primary-gsa.shEl siguiente ejemplo es solo una parte de la secuencia de comandos. Para ver la secuencia de comandos completa, haz clic en Ver en GitHub.
Aprovisiona las instancias de Compute Engine
En esta sección, crearás las VM de Compute Engine en las que se instalará Google Distributed Cloud. También debes verificar la conectividad a estas VMs antes de continuar a la sección de instalación.
En tu estación de trabajo, crea claves SSH que se usan para la comunicación entre las instancias de Compute Engine.
ssh-keygen -f ./build-artifacts/consumer-edge-machineEncriptar la clave privada SSH con Cloud Key Management Service
gcloud kms encrypt \ --key gdc-ssh-key \ --keyring gdc-ce-keyring \ --location global \ --plaintext-file build-artifacts/consumer-edge-machine \ --ciphertext-file build-artifacts/consumer-edge-machine.encryptedGenera el archivo de configuración del entorno
.envrcy obtenlo como fuente. Después de crearlo, inspecciona el archivo.envrcpara asegurarte de que las variables de entorno se hayan reemplazado por los valores correctos.envsubst < templates/envrc-template.sh > .envrc source .envrcEl siguiente es un ejemplo de un archivo
.envrcque se genera mediante el reemplazo de las variables de entorno en el archivotemplates/envrc-template.sh. Observa que las líneas que se actualizaron están destacadas:Crear instancias de Compute Engine en las que esté instalado Google Distributed Cloud
./scripts/cloud/create-cloud-gce-baseline.sh -c "$GCE_COUNT" | \ tee ./build-artifacts/gce-info
Instala Google Distributed Cloud con Ansible
La secuencia de comandos que se usa en esta guía crea clústeres de GKE en Bare Metal en grupos de tres instancias de Compute Engine. La variable de entorno GCE_COUNT controla la cantidad de clústeres creados. Por ejemplo, puedes establecer la variable de entorno GCE_COUNT en 6 para crear dos clústeres de GKE en Bare Metal con 3 instancias de VM cada uno. De forma predeterminada,
la variable de entorno GCE_COUNT se establece en 3. Por lo tanto, en esta guía, se creará un clúster con 3 instancias de Compute Engine. Las instancias de VM se nombran con un prefijo cnuc- seguido de un número. La primera instancia de VM de cada clúster actúa como la estación de trabajo de administrador desde la que se activa la instalación. El clúster también recibe el mismo nombre que la VM de la estación de trabajo de administrador (por ejemplo, cnuc-1, cnuc-4, cnuc-7).
La guía de Ansible realiza las siguientes acciones:
- Configura las instancias de Compute Engine con las herramientas necesarias, como
docker,bmctl,gcloudynomos. - Instala Google Distributed Cloud en las instancias de Compute Engine configuradas.
- Crea un clúster independiente de GKE en Bare Metal llamado
cnuc-1. - Registra el clúster
cnuc-1en Google Cloud. - Instala el Sincronizador de configuración en el clúster
cnuc-1. - Configura el Sincronizador de configuración para sincronizarlo con la configuración del clúster que se encuentra en
anthos-bm-edge-deployment/acm-config-sinken el repositorio bifurcado. - Genera el
Login tokenpara el clúster.
Completa los siguientes pasos para configurar y comenzar el proceso de instalación:
En tu estación de trabajo, crea la imagen de Docker que se usará para la instalación. Esta imagen tiene todas las herramientas necesarias para el proceso de instalación, como Ansible, Python y Google Cloud CLI.
gcloud builds submit --config docker-build/cloudbuild.yaml docker-build/Cuando la compilación se ejecuta de forma correcta, produce un resultado como el siguiente:
... latest: digest: sha256:99ded20d221a0b2bcd8edf3372c8b1f85d6c1737988b240dd28ea1291f8b151a size: 4498 DONE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ID CREATE_TIME DURATION SOURCE IMAGES STATUS 2238baa2-1f41-440e-a157-c65900b7666b 2022-08-17T19:28:57+00:00 6M53S gs://my_project_cloudbuild/source/1660764535.808019-69238d8c870044f0b4b2bde77a16111d.tgz gcr.io/my_project/consumer-edge-install (+1 more) SUCCESSGenera el archivo de inventario de Ansible a partir de una plantilla.
envsubst < templates/inventory-cloud-example.yaml > inventory/gcp.yamlEjecuta la secuencia de comandos de instalación que inicia un contenedor de Docker a partir de la imagen compilada con anterioridad. La secuencia de comandos usa Docker de forma interna para generar el contenedor con una activación de volumen en el directorio de trabajo actual. Una vez que se complete esta secuencia de comandos de forma correcta, debes estar dentro del contenedor de Docker que se creó. Activas la instalación de Ansible desde este contenedor.
./install.shCuando la secuencia de comandos se ejecuta correctamente, produce un resultado como el siguiente:
... Check the values above and if correct, do you want to proceed? (y/N): y Starting the installation Pulling docker install image... ============================== Starting the docker container. You will need to run the following 2 commands (cut-copy-paste) ============================== 1: ./scripts/health-check.sh 2: ansible-playbook all-full-install.yaml -i inventory 3: Type 'exit' to exit the Docker shell after installation ============================== Thank you for using the quick helper script! (you are now inside the Docker shell)Desde el interior del contenedor de Docker, verifica el acceso a las instancias de Compute Engine.
./scripts/health-check.shCuando la secuencia de comandos se ejecuta correctamente, produce un resultado como el siguiente:
... cnuc-2 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-3 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-1 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"}Desde el contenedor de Docker, ejecuta la guía de Ansible para instalar Google Distributed Cloud en instancias de Compute Engine. Cuando finalices, verás el
Login Tokendel clúster impreso en la pantalla.ansible-playbook all-full-install.yaml -i inventory | tee ./build-artifacts/ansible-run.logCuando la instalación se ejecuta de forma correcta, produce un resultado como el siguiente:
... TASK [abm-login-token : Display login token] ************************************************************************** ok: [cnuc-1] => { "msg": "eyJhbGciOiJSUzI1NiIsImtpZCI6Imk2X3duZ3BzckQyWmszb09sZHFMN0FoWU9mV1kzOWNGZzMyb0x2WlMyalkifQ.eymljZS1hY2NvdW iZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImVkZ2Etc2EtdG9rZW4tc2R4MmQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2Nvd 4CwanGlof6s-fbu8" } skipping: [cnuc-2] skipping: [cnuc-3] PLAY RECAP *********************************************************************************************************** cnuc-1 : ok=205 changed=156 unreachable=0 failed=0 skipped=48 rescued=0 ignored=12 cnuc-2 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2 cnuc-3 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2
Accede al clúster de GKE en Bare Metal en la consola de Google Cloud
Una vez que la guía de Ansible se ejecuta hasta su finalización, se instala un clúster independiente de GKE en Bare Metal dentro de las VM de Compute Engine. Este clúster también se registra en Google Cloud mediante el agente de Connect. Sin embargo, para ver los detalles de este clúster, debes acceder a él desde la consola de Google Cloud. Para acceder al clúster de GKE, completa los siguientes pasos.
Copia el token del resultado de la guía de Ansible en la sección anterior.
En la consola de Google Cloud, ve a la página Clústeres de Kubernetes y usa el token copiado para acceder al clúster
cnuc-1.Ir a la página Clústeres de Kubernetes
- En la lista de clústeres, haz clic en Acciones junto al clúster
cnuc-1y, luego, en Acceder. - Selecciona Token y pega el token copiado.
- Haz clic en Login.
- En la lista de clústeres, haz clic en Acciones junto al clúster
- En la consola de Google Cloud, ve a la página Configuración en la sección Funciones.
En la pestaña Packages, verifica la columna Sync status en la tabla del clúster.
Verifica que el estado sea Sincronizado. Si el estado es Sincronizado, significa que el Sincronizador de configuración sincronizó de forma correcta los archivos de configuración de GitHub con el clúster implementado, cnuc-1.
Configura un proxy para el tráfico externo
El clúster de GKE en Bare Metal instalado en los pasos anteriores usa un balanceador de cargas en paquetes llamado MetalLB.
Solo se puede acceder a este servicio de balanceador de cargas a través de una dirección IP de nube privada virtual (VPC). Para enrutar el tráfico que ingresa a través de su IP externa al balanceador de cargas en paquetes, configura un servicio de proxy inverso en el host de administrador (cnuc-1). Este servicio te permite acceder al servidor de API de la aplicación de punto de venta a través de la IP externa del host de administrador (cnuc-1).
Las secuencias de comandos de instalación de los pasos anteriores instalados NGINX en los hosts de administrador junto con un archivo de configuración de muestra Actualiza este archivo para usar la dirección IP del servicio del balanceador de cargas y reiniciar NGINX.
En tu estación de trabajo, usa SSH para acceder a la estación de trabajo de administrador:
ssh -F ./build-artifacts/ssh-config abm-admin@cnuc-1Desde el interior de la estación de trabajo de administrador, configura el proxy inverso de NGINX para enrutar el tráfico al servicio del balanceador de cargas del servidor de la API. Obtén la dirección IP del servicio de Kubernetes del balanceador de cargas:
ABM_INTERNAL_IP=$(kubectl get services api-server-lb -n pos | awk '{print $4}' | tail -n 1)Actualiza el archivo de configuración de la plantilla con la dirección IP recuperada:
sudo sh -c "sed 's/<K8_LB_IP>/${ABM_INTERNAL_IP}/g' \ /etc/nginx/nginx.conf.template > /etc/nginx/nginx.conf"Reinicia NGINX para asegurarte de que se aplique la configuración nueva:
sudo systemctl restart nginxVerifica y verifica el estado del servidor NGINX para informar “activo (en ejecución)”:
sudo systemctl status nginxCuando NGINX se ejecuta de forma correcta, produce un resultado como el del siguiente ejemplo:
● nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2021-09-17 02:41:01 UTC; 2s ago Docs: man:nginx(8) Process: 92571 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Process: 92572 ExecStart=/usr/sbin/nginx -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Main PID: 92573 (nginx) Tasks: 17 (limit: 72331) Memory: 13.2M CGroup: /system.slice/nginx.service ├─92573 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; ├─92574 nginx: worker process ├─92575 nginx: worker process ├─92577 nginx: .... ... ...Sal de la sesión de SSH en la estación de trabajo de administrador:
exitSal de la sesión de shell en el contenedor de Docker. Después de salir de la instancia de administrador, aún te encuentras en el contenedor de Docker que se usó para la instalación:
exit
Accede a la aplicación de punto de venta
Con la configuración del proxy externo, puedes acceder a la aplicación que se ejecuta dentro del clúster de GKE. Para acceder a la aplicación de muestra de punto de venta, completa los siguientes pasos.
En tu estación de trabajo, obtén la dirección IP externa de la instancia de administrador de Compute Engine y accede a la IU de la aplicación de punto de venta:
EXTERNAL_IP=$(gcloud compute instances list \ --project ${PROJECT_ID} \ --filter="name:cnuc-1" \ --format="get(networkInterfaces[0].accessConfigs[0].natIP)") echo "Point the browser to: ${EXTERNAL_IP}:${PROXY_PORT}"Cuando las secuencias de comandos se ejecutan de forma correcta, producen resultados como los siguientes:
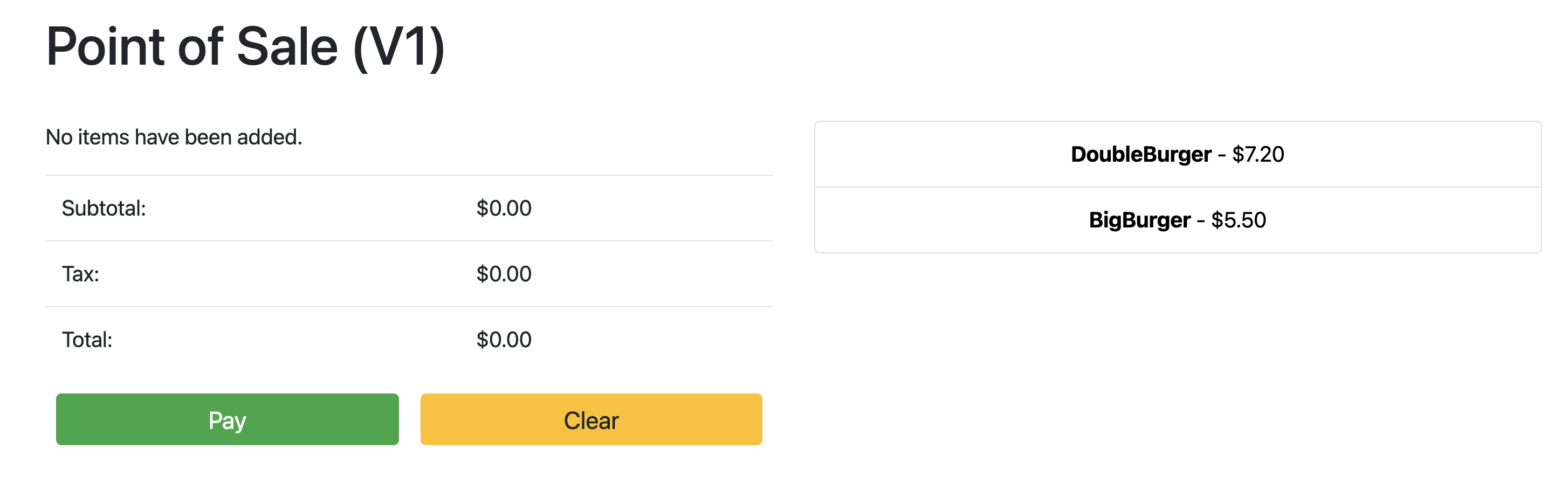
Point the browser to: 34.134.194.84:8082Abre tu navegador web y navega a la dirección IP que se muestra en el resultado del comando anterior. Puedes acceder a la aplicación de punto de venta de muestra y probarla, tal como se muestra en la siguiente captura de pantalla de ejemplo:
Usa el Sincronizador de configuración para actualizar el servidor de la API
La aplicación de ejemplo puede actualizarse a una versión más reciente si actualizas los archivos de configuración en el repositorio raíz. El Sincronizador de configuración detecta las actualizaciones y realiza los cambios en tu clúster de forma automática. En este ejemplo, el repositorio raíz es el repositorio anthos-samples que clonaste al comienzo de esta guía. Para ver cómo la aplicación de punto de venta de muestra puede pasar por una implementación de actualización a una versión más reciente, completa los siguientes pasos.
En tu estación de trabajo, actualiza el campo
imagepara cambiar la versión del servidor de la API dev1av2. La configuración de YAML para la implementación se encuentra en el archivo enanthos-bm-edge-deployment/acm-config-sink/namespaces/pos/api-server.yaml.Agrega, confirma y envía los cambios al repositorio bifurcado:
git add acm-config-sink/namespaces/pos/api-server.yaml git commit -m "chore: updated api-server version to v2" git pushEn la consola de Google Cloud, ve a la página Sincronizador de configuración para verificar el estado de especificaciones de configuración. Verifica que el estado sea Sincronizado.
En la consola de Google Cloud, ve a la página Cargas de trabajo de Kubernetes Engine para verificar que la Implementación esté actualizada.
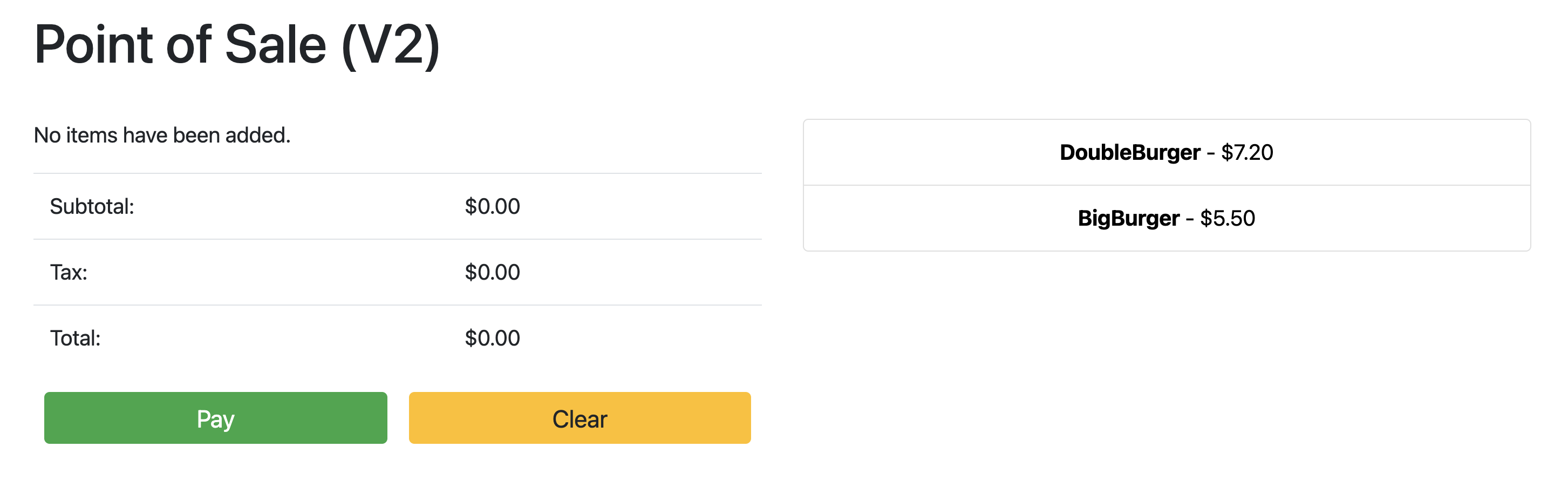
Cuando el estado de Implementación sea Correcto, apunta el navegador a la dirección IP de la sección anterior para ver la aplicación de punto de venta. Ten en cuenta que la versión del título muestra “V2”, lo que indica que se implementó el cambio de tu aplicación, como se muestra en la siguiente captura de pantalla de ejemplo:
Es posible que debas actualizar de manera forzada la pestaña del navegador para ver los cambios.
Limpia
A fin de evitar cargos innecesarios de Google Cloud, borra los recursos que se usaron para esta guía cuando termines. Puedes borrar estos recursos de forma manual o borrar el proyecto de Google Cloud, lo que también elimina todos los recursos. Además, también puedes limpiar los cambios realizados en tu estación de trabajo local:
Estación de trabajo local
Los siguientes archivos deben actualizarse para borrar los cambios que realizaron las secuencias de comandos de instalación.
- Quita las direcciones IP de la VM de Compute Engine que se agregan al archivo
/etc/hosts. - Quita la configuración SSH para
cnuc-*en el archivo~/.ssh/config. - Quita las huellas digitales de la VM de Compute Engine del archivo
~/.ssh/known_hosts.
Borrar proyecto
Si creaste un proyecto dedicado para este procedimiento, borra el proyecto de Google Cloud de la consola de Cloud.
Manual
Si usaste un proyecto existente para este procedimiento, haz lo siguiente:
- Cancela el registro de todos los clústeres de Kubernetes que tengan un nombre con el prefijo
cnuc-. - Borra todas las VM de Compute Engine con un nombre con el prefijo
cnuc-. - Borra el bucket de Cloud Storage con un nombre con el prefijo
abm-edge-boot. - Borra las reglas de firewall
allow-pod-ingressyallow-pod-egress. - Borra el secreto de Secret Manager
install-pub-key.
Próximos pasos
Puedes expandir esta guía si agregas otra ubicación perimetral. Si configuras la variable de entorno GCE_COUNT en 6 y vuelves a ejecutar los mismos pasos de las secciones anteriores, se crean tres instancias nuevas de Compute Engine (cnuc-4, cnuc-5 y cnuc-6) y un nuevo clúster independiente de GKE en Bare Metal llamado cnuc-4.
También puedes intentar actualizar las opciones de configuración de los clústeres en tu repositorio bifurcado para aplicar de forma selectiva diferentes versiones de la aplicación de punto de venta a los dos clústeres, cnuc-1 y cnuc-4, mediante ClusterSelectors.
Para obtener detalles sobre los pasos individuales de esta guía, las secuencias de comandos involucradas, consulta el repositorio de anthos-samples.