이 페이지에서는 구성 동기화 리소스를 모니터링하는 데 사용할 수 있는 OpenTelemetry 측정항목에 대해 설명합니다.
가격 책정
구성 동기화 측정항목은 Google Cloud Managed Service for Prometheus를 사용하여 측정항목을 Cloud Monitoring에 로드합니다. Cloud Monitoring은 수집된 샘플의 수를 기준으로 이러한 측정항목의 수집에 대한 요금을 청구합니다.
자세한 내용은 Cloud Monitoring 가격 책정을 참조하세요.
구성 동기화에서 측정항목을 수집하는 방법
구성 동기화는 OpenCensus를 사용하여 측정항목을 생성 및 기록하고 OpenTelemetry를 사용하여 측정항목을 Prometheus 및 Cloud Monitoring으로 내보냅니다. 다음 가이드에서는 측정항목을 내보내는 방법을 설명합니다.
- Cloud Monitoring
- Prometheus
- 맞춤 모니터링 시스템 (권장하지 않음)
OpenTelemetry Collector를 구성하기 위해 구성 동기화는 기본적으로 otel-collector이라는 ConfigMap을 만듭니다. otel-collector 배포는 config-management-monitoring 네임스페이스에서 실행됩니다.
otel-collector ConfigMap을 만들면 prometheus 내보내기 도구가 구성되어 Prometheus가 스캔할 측정항목 엔드포인트를 노출합니다.
GKE 또는 Google Cloud 사용자 인증 정보로 구성된 다른 Kubernetes 환경에서 구성 동기화를 실행하면 구성 동기화가 otel-collector-google-cloud이라는 ConfigMap을 만듭니다. otel-collector-google-cloud는 otel-collector ConfigMap의 구성을 재정의합니다. 구성 동기화는 otel-collector 또는 otel-collector-google-cloud ConfigMap에 대한 변경사항을 되돌립니다.
otel-collector-google-cloud ConfigMap을 만들면 Cloud Monitoring으로 내보내는 cloudmonitoring 내보내기 도구와 Google의 내부 측정항목 서비스로 내보내는 kubernetes 내보내기 도구도 추가됩니다. kubernetes 내보내기 도구는 구성 동기화를 개선하기 위해 익명처리된 일부 측정항목을 Google에 전송합니다.
Cloud Monitoring은Google Cloud 프로젝트에 전송된 측정항목을 저장합니다. cloudmonitoring 및 kubernetes 내보내기 도구는 동일한Google Cloud 서비스 계정을 사용하며, 이 계정에는 Cloud Monitoring에 쓰기 위한 IAM 권한이 필요합니다. 이러한 권한을 구성하려면 Cloud Monitoring에 대한 측정항목 쓰기 권한 부여를 참조하세요.
OpenTelemetry 측정항목
구성 동기화 및 리소스 그룹 컨트롤러가 OpenCensus로 다음 측정항목을 수집하고 OpenTelemetry 수집기를 통해 사용할 수 있게 합니다. 태그 열에는 각 측정항목에 적용되는 구성 동기화 관련 태그가 나열됩니다. 태그가 있는 측정항목은 태그 값의 각 조합에 대해 하나씩 여러 측정을 나타냅니다.
구성 동기화 측정항목
| 이름 | 유형 | 태그 | 설명 |
|---|---|---|---|
| api_duration_seconds | 배포 | operation, status | API 서버 호출의 지연 시간 분포 |
| apply_duration_seconds | 배포 | 상태 | 신뢰 소스에서 선언된 리소스를 클러스터에 적용할 때의 지연 시간 분포 |
| apply_operations_total | 개수 | operation, status, controller | 신뢰 소스의 리소스를 클러스터에 동기화하기 위해 수행된 총 작업 수 |
| declared_resources | 최종 값 | Git에서 파싱된 선언된 리소스 수 | |
| internal_errors_total | 개수 | source | 구성 동기화에서 발생한 총 내부 오류 수 내부 오류가 발생하지 않은 경우 측정항목이 쿼리 결과에 표시되지 않을 수 있습니다. |
| last_sync_timestamp | 최종 값 | 상태 | Git에서의 최근 동기화의 타임스탬프 |
| parser_duration_seconds | 배포 | status, trigger, source | 정보 소스에서 클러스터로 동기화와 관련된 여러 단계의 지연 시간 분포 |
| pipeline_error_observed | 최종 값 | name, reconciler, component | RootSync 및 RepoSync 커스텀 리소스의 상태입니다. 값 1은 실패를 나타냅니다. |
| reconcile_duration_seconds | 배포 | 상태 | 조정자 관리자가 처리한 조정 이벤트의 지연 시간 분포입니다. |
| reconciler_errors | 최종 값 | component, errorclass | 신뢰 소스의 리소스를 클러스터에 동기화하는 동안 발생한 오류 수 |
| remediate_duration_seconds | 배포 | 상태 | 교정자 조정 이벤트의 지연 시간 분포 |
| resource_conflicts_total | 개수 | 캐시된 리소스와 클러스터 리소스 사이의 불일치로부터 발생한 총 리소스 충돌 수 리소스 충돌이 발생하지 않은 경우 측정항목이 쿼리 결과에 표시되지 않을 수 있습니다. | |
| resource_fights_total | 개수 | 너무 자주 동기화되고 있는 리소스의 총 개수. 0보다 큰 결과는 문제가 있음을 나타냅니다. 자세한 내용은 KNV2005: ResourceFightWarning을 참조하세요. 리소스 싸움이 발생하지 않은 경우 측정항목이 쿼리 결과에 표시되지 않을 수 있습니다. |
리소스 그룹 컨트롤러 측정항목
리소스 그룹 컨트롤러는 관리형 리소스를 추적하고 개별 리소스가 준비 또는 조정되었는지 확인하는 구성 동기화의 구성요소입니다. 사용 가능한 측정항목은 다음과 같습니다.
| 이름 | 유형 | 태그 | 설명 |
|---|---|---|---|
| rg_reconcile_duration_seconds | 배포 | stallreason | ResourceGroup CR을 조정하는 데 걸린 시간의 분포 |
| resource_group_total | 최종 값 | ResourceGroup CR의 현재 개수 | |
| resource_count | 최종 값 | resourcegroup | ResourceGroup으로 추적된 총 리소스 수 |
| ready_resource_count | 최종 값 | resourcegroup | ResourceGroup의 준비된 총 리소스 수 |
| resource_ns_count | 최종 값 | resourcegroup | ResourceGroup의 리소스에 사용된 네임스페이스의 수 |
| cluster_scoped_resource_count | 최종 값 | resourcegroup | ResourceGroup의 클러스터 범위 지정된 리소스 수 |
| crd_count | 최종 값 | resourcegroup | ResourceGroup의 CRD 수 |
| kcc_resource_count | 최종 값 | resourcegroup | ResourceGroup의 총 KCC 리소스 수 |
| pipeline_error_observed | 최종 값 | name, reconciler, component | RootSync 및 RepoSync 커스텀 리소스의 상태입니다. 값 1은 실패를 나타냅니다. |
구성 동기화 측정항목 라벨
측정항목 라벨을 사용하여 Cloud Monitoring 및 Prometheus의 측정항목 데이터를 집계할 수 있습니다. Monitoring 콘솔의 '그룹별' 드롭다운 목록에서 선택할 수 있습니다.
Cloud Monitoring 라벨과 Prometheus 측정항목 라벨에 대한 자세한 내용은 측정항목 모델 구성요소 및 Prometheus 데이터 모델을 참조하세요.
측정항목 라벨
다음 라벨은 Cloud Monitoring 및 Prometheus로 모니터링할 때 사용할 수 있는 구성 동기화 및 리소스 그룹 컨트롤러 측정항목에 사용됩니다.
| 이름 | 값 | 설명 |
|---|---|---|
operation |
create, patch, update, delete | 수행된 작업 유형 |
status |
success, error | 작업 실행 상태 |
reconciler |
rootsync, reposync | 조정자 유형 |
source |
parser, differ, remediator | 내부 오류의 소스 |
trigger |
retry, watchUpdate, managementConflict, resync, reimport | 조정 이벤트 트리거 |
name |
조정자 이름 | 조정자 이름 |
component |
parsing, source, sync, rendering, readiness | 구성요소 이름/현재 조정 단계 |
container |
reconciler, git-sync | 컨테이너 이름 |
resource |
cpu, memory | 리소스 유형 |
controller |
applier, remediator | 루트 또는 네임스페이스 조정자의 컨트롤러 이름 |
type |
ClusterRole, Namespace, NetworkPolicy, Role 등 모든 Kubernetes 리소스 | Kubernetes API의 종류 |
commit |
---- | 최신 동기화된 커밋의 해시 |
리소스 라벨
Prometheus 및 Cloud Monitoring에 전송되는 구성 동기화 측정항목에는 소스 포드 식별을 위해 설정된 다음 측정항목 라벨이 포함됩니다.
| 이름 | 설명 |
|---|---|
k8s.node.name |
Kubernetes 포드를 호스팅하는 노드의 이름 |
k8s.pod.namespace |
포드의 네임스페이스 |
k8s.pod.uid |
포드의 UID |
k8s.pod.ip |
포드의 IP |
k8s.deployment.name |
포드를 소유하는 배포 이름 |
reconciler 포드에서 Prometheus 및 Cloud Monitoring으로 전송되는 구성 동기화 측정항목에는 조정자를 구성하는 데 사용되는 RootSync 또는 RepoSync를 식별하도록 설정된 다음 측정항목 라벨도 있습니다.
| 이름 | 설명 |
|---|---|
configsync.sync.kind |
이 조정자를 구성하는 리소스 종류: RootSync 또는 RepoSync |
configsync.sync.name |
이 조정자를 구성하는 RootSync 또는 RepoSync의 이름 |
configsync.sync.namespace |
이 조정자를 구성하는 RootSync 또는 RepoSync의 네임스페이스 |
Cloud Monitoring 리소스 라벨
Cloud Monitoring 리소스 라벨은 스토리지에서 측정항목의 색인을 생성하기 위해 사용됩니다. 즉, 카디널리티가 중요한 성능 요인인 측정항목 라벨과 달리 카디널리티 효과가 무시 가능한 수준입니다. 자세한 내용은 모니터링 리소스 유형을 참조하세요.
k8s_container 리소스 유형은 소스 컨테이너를 식별하기 위해 다음 리소스 라벨을 설정합니다.
| 이름 | 설명 |
|---|---|
container_name |
컨테이너 이름 |
pod_name |
포드의 이름 |
namespace_name |
포드의 네임스페이스 |
location |
노드를 호스팅하는 클러스터의 리전 또는 영역 |
cluster_name |
노드를 호스팅하는 클러스터의 이름 |
project |
클러스터를 호스팅하는 프로젝트의 ID |
커스텀 측정항목 필터링 구성
구성 동기화가 Prometheus, Cloud Monitoring, Google의 내부 모니터링 서비스로 내보내는 커스텀 측정항목을 조정할 수 있습니다. 커스텀 측정항목을 조정하여 포함된 측정항목을 미세 조정하거나 다른 백엔드를 구성합니다.
커스텀 측정항목을 수정하려면 otel-collector-custom이라는 ConfigMap을 만든 다음 수정합니다. 이 ConfigMap을 사용하면 구성 동기화에서 수정사항을 되돌리지 않습니다. otel-collector 또는 otel-collector-google-cloud ConfigMap을 수정하면 구성 동기화에서 모든 변경사항을 되돌립니다.
이 ConfigMap을 조정하는 방법에 대한 예시는 오픈소스 구성 동기화 문서의 커스텀 측정항목 필터링을 참조하세요.
pipeline_error_observed 측정항목 이해
pipeline_error_observed 측정항목은 동기화되지 않았거나 원하는 상태로 조정되지 않은 리소스를 포함하는 RepoSync 또는 RootSync CR을 빠르게 식별할 수 있게 해주는 측정항목입니다.
RootSync 또는 RepoSync의 동기화 성공에 대해 모든 구성요소(
rendering,source,sync,readiness)를 포함하는 측정항목은 값 0으로 관측됩니다.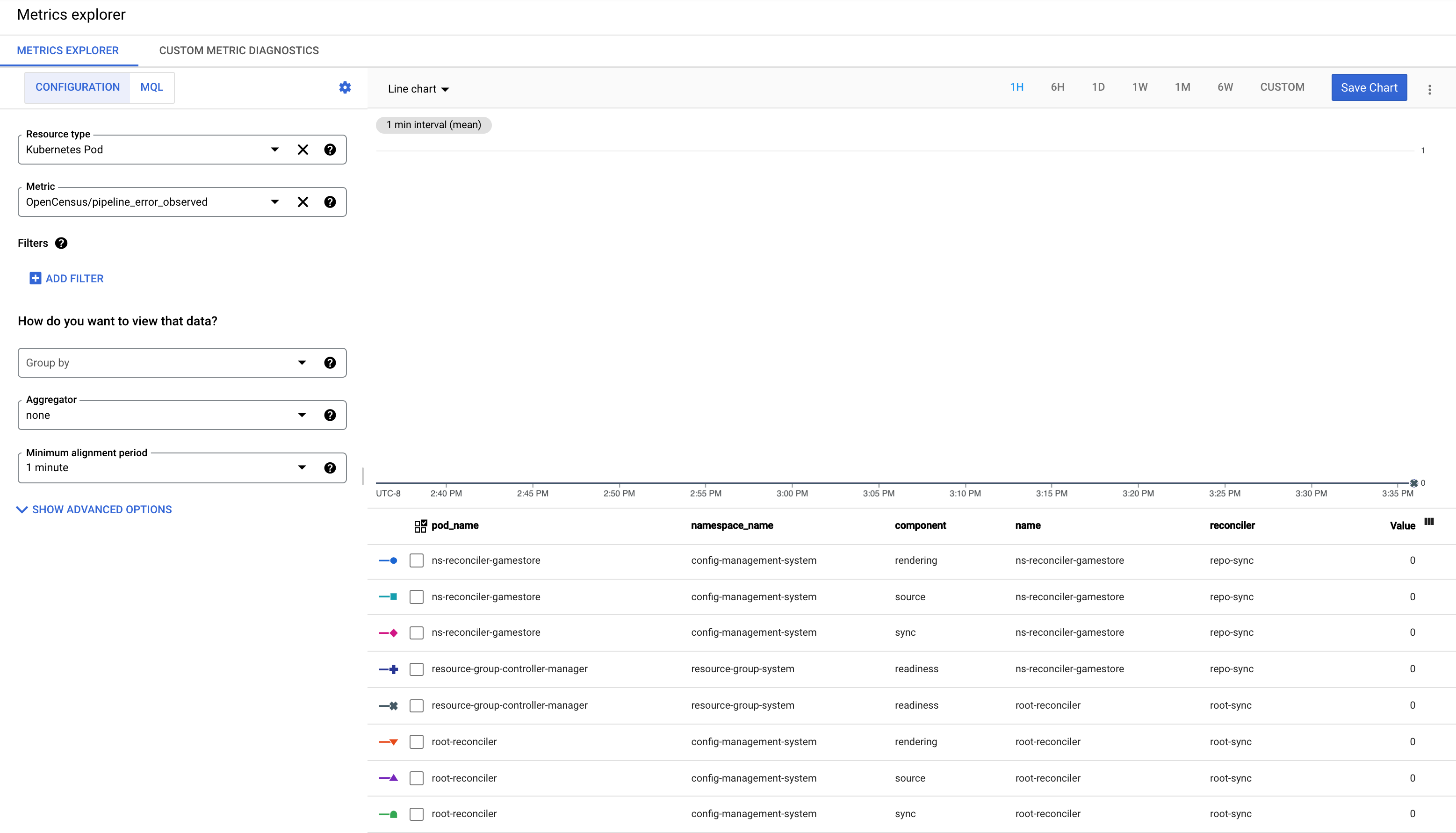
최신 커밋으로 자동 렌더링이 실패하면 구성요소가
rendering인 측정항목이 값 1로 관측됩니다.최신 커밋을 체크아웃할 때 오류가 발생하거나 최신 커밋에 잘못된 구성이 포함된 경우 구성요소
source가 포함된 측정항목이 값 1로 관측됩니다.어떤 리소스가 클러스터에 적용되지 않으면 구성요소
sync가 포함된 측정항목이 값 1로 관측됩니다.리소스가 적용되었지만 원하는 상태에 도달하지 못하면
readiness구성요소가 있는 측정항목이 값 1로 관측됩니다. 예를 들어 배포가 클러스터에 적용되지만 해당 포드가 성공적으로 생성되지 않습니다.
다음 단계
- RootSync 및 RepoSync 객체를 모니터링하는 방법 자세히 알아보기
- 구성 동기화 SLI 사용 방법 알아보기