사용 사례
이 참조 아키텍처는 다음 시나리오를 지원합니다.
- 마지막 백업 이후 일부 다운타임과 데이터 손실을 톨러레이션(toleration)할 수 있는 데이터베이스가 있는 경우
- 서버 또는 VM 이미지 스냅샷이 아닌 데이터베이스 수준에서 사용자 오류, 손상 또는 물리적 장애로부터 AlloyDB Omni 데이터베이스를 보호하려는 경우
- 로컬 또는 원격으로 최대한 특정 시점까지 데이터베이스를 복구할 수 있어야 하는 경우
참조 아키텍처 작동 방식
표준 가용성 참조 아키텍처는 AlloyDB Omni 데이터베이스가 호스트 서버에서 독립형 인스턴스로, 가상 머신(AlloyDB Omni 설치)으로 또는 Kubernetes 클러스터(Kubernetes에 AlloyDB Omni 설치)에서 실행되는지 여부에 관계없이 AlloyDB Omni 데이터베이스 백업 및 복구를 다룹니다.
표준 가용성은 기본 구현이며 필요한 추가 하드웨어나 서비스를 최소화하지만 데이터베이스가 커질수록 복구 시간 목표(RTO)가 증가합니다. 백업할 데이터가 많을수록 데이터베이스를 복원하고 복구하는 데 시간이 오래 걸립니다. 데이터 손실은 백업 유형에 따라 다릅니다. 데이터 파일만 주기적으로 백업하는 경우 복원할 때 마지막 백업 이후의 데이터가 손실됩니다.
RPO 감소
PostgreSQL 연속 보관처리 기능을 사용하면 낮은 목표 복구 시간(RPO)을 달성하고 백업을 통해 PITR(point-in-time recovery)을 사용 설정할 수 있습니다. 이 프로세스에는 미리 쓰기 로깅(WAL) 파일 보관처리와 원격 스토리지 위치로 미리 쓰기 로깅 데이터 스트리밍이 포함될 수도 있습니다.
미리 쓰기 로깅 파일이 가득 차거나 특정 간격으로만 보관처리되는 경우 전체 데이터베이스 손실(현재 미리 쓰기 로깅 파일 포함)로 인해 복구가 마지막으로 보관처리된 미리 쓰기 로깅 파일로 제한됩니다. 즉, 목표 복구 시간(RPO)에서 잠재적인 데이터 손실을 고려해야 합니다. 반대로 미리 쓰기 로깅 데이터를 지속적으로 전송하면 데이터 손실이 발생하지 않습니다.
연속 백업을 수행할 때 특정 시점으로 복구할 수 있습니다. PITR(point-in-time recovery)을 사용하면 실수로 인한 테이블 삭제나 잘못된 일괄 업데이트와 같은 오류가 발생하기 전의 상태로 복원할 수 있습니다. 하지만 임시 보조 데이터베이스를 사용하지 않는 한 이 복구 방법은 목표 복구 시간(RPO)에 영향을 미칩니다.
백업 전략
AlloyDB Omni Postgres 수준 백업이 로컬 또는 원격 스토리지에 저장되도록 구성할 수 있습니다. 로컬 스토리지에서 더 빠르게 백업과 복구를 수행할 수 있지만 전체 호스트나 VM이 실패할 때 원격 스토리지가 일반적으로 오류를 더 강력하게 처리합니다.
Kubernetes 이외의 환경에서 백업
Kubernetes 이외의 배포의 경우 다음 PostgreSQL 도구를 사용하여 백업을 예약할 수 있습니다.
- pgBackRest. 자세한 내용은 AlloyDB Omni용 pgBackRest 설정을 참조하세요.
- Barman. 자세한 내용은 AlloyDB Omni용 Barman 설정을 참조하세요.
또는 소규모 데이터베이스의 경우 데이터베이스의 논리적 백업을 수행할 수 있습니다(단일 데이터베이스의 경우 pg_dump 또는 전체 클러스터의 경우 pg_dumpall 사용). pg_restore를 사용하여 복원할 수 있습니다.
AlloyDB Omni 연산자를 사용하는 Kubernetes에서 백업
Kubernetes 클러스터에 배포된 AlloyDB Omni의 경우 각 데이터베이스 클러스터의 백업 계획을 사용하여 연속 백업을 구성할 수 있습니다. 자세한 내용은 Kubernetes에서 백업 및 복원을 참조하세요.
클라우드 공급업체에서 제공하는 옵션을 포함하여 AlloyDB Omni 백업을 로컬로 또는 Cloud Storage에 원격으로 저장할 수 있습니다. 자세한 내용은 잠재적인 백업 대상을 보여주는 그림 1을 참조하세요.
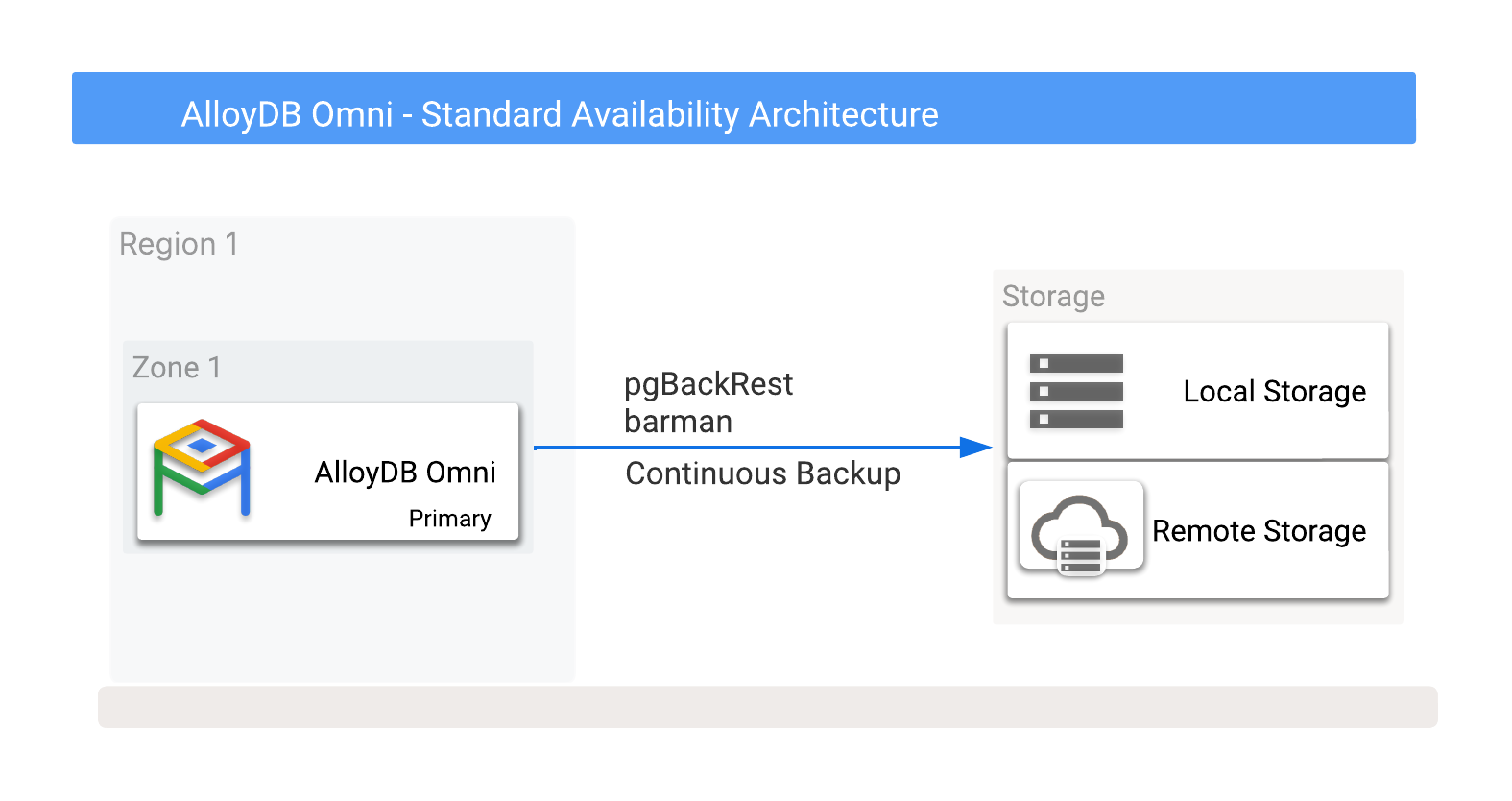
그림 1. 백업 옵션이 있는 AlloyDB Omni
백업을 로컬 또는 원격 스토리지 옵션으로 처리할 수 있습니다. 로컬 백업은 I/O 처리량만 사용하므로 빠르지만 원격 백업의 경우 일반적으로 지연 시간이 더 길고 네트워크 대역폭이 더 낮습니다. 하지만 원격 백업은 영역 장애를 포함한 최적의 보호 기능을 제공합니다.
로컬 백업을 로컬 또는 공유 스토리지로 분할할 수도 있습니다. 데이터베이스 호스트가 실패할 때 로컬 스토리지 옵션은 재해 복구 옵션 부족으로 인한 영향을 받지만 공유 스토리지를 사용하면 해당 스토리지를 다른 서버로 이전한 후 복구에 사용할 수 있습니다. 즉, 공유 스토리지는 더 빠른 RTO를 제공할 수 있습니다.
로컬 및 공유 스토리지 배포의 경우 다음 유형의 백업을 예약하거나 주문형으로 수동으로 수행할 수 있습니다.
- 전체 백업: 데이터 복구에 필요한 모든 데이터베이스 파일을 전체 백업합니다.
- 차등 백업: 마지막 전체 백업 이후의 파일 변경사항만 백업합니다.
- 증분 백업: 종류에 관계없이 마지막 백업 이후의 파일 변경사항만 백업합니다.
point-in-time recovery
PostgreSQL 미리 쓰기 로깅(WAL) 파일의 연속 백업은 PITR(point-in-time recovery)을 지원합니다. 실패 이벤트 후 미리 쓰기 로깅 파일이 손상되지 않고 사용 가능하면 이러한 파일을 사용하여 데이터 손실 없이 복구할 수 있습니다.
미리 쓰기 로깅 파일 쓰기를 제어하려면 다음 파라미터를 구성하면 됩니다.
| 매개변수 | 설명 |
|---|---|
|
비동기적으로 커밋되는 트랜잭션에 의해 쓰기가 더 빨리 작동하지 않는 한 미리 쓰기 로깅 작성자가 미리 쓰기 로깅을 디스크에 플러시하는 빈도를 지정합니다. 기본값은 200ms입니다. 이 값을 늘리면 쓰기 빈도가 줄어들지만 서버가 비정상 종료될 경우 손실되는 데이터 양이 늘어날 수 있습니다. |
|
미리 쓰기 로깅 작성자가 강제로 디스크에 플러시하기 전에 누적될 수 있는 미리 쓰기 로깅 데이터 양을 지정합니다. 기본값은 1MB입니다. 0으로 설정하면 미리 쓰기 로깅 데이터는 항상 디스크에 즉시 플러시됩니다. |
|
미리 쓰기 로깅 데이터가 디스크에 플러시되기 전에 커밋이 사용자에게 응답을 반환하는지 여부를 지정합니다. 기본 설정은 on이며 이는 트랜잭션이 지속되도록 합니다. 즉, 커밋이 사용자에게 성공 코드를 반환하기 전에 디스크에 작성되었습니다. off로 설정하면 트랜잭션이 디스크에 기록되기 전에 wal_writer_delay가 최대 3배까지 증가합니다. |
미리 쓰기 로깅 사용량 모니터링
다음 방법을 사용하여 미리 쓰기 로깅 사용량을 모니터링할 수 있습니다.
| 모니터링 방법 | 설명 |
|---|---|
|
이 표준 뷰에는 미리 쓰기 로깅 쓰기 수와 미리 쓰기 로깅 동기화 수를 저장하는 wal_write 및 wal_sync 열이 있습니다. 구성 파라미터 track_wal_io_timing이 사용 설정되면 wal_write_time 및 wal_sync_time도 저장됩니다. 이 뷰의 정기적인 스냅샷은 시간 경과에 따른 미리 쓰기 로깅 쓰기 및 동기화 활동을 표시하는 데 도움이 될 수 있습니다. |
pg_current_wal_lsn() |
이 함수는 현재 로그 시퀀스 넘버(lsn) 위치를 반환하며, 이는 타임스탬프와 연결되고 시간이 지남에 따라 스냅샷으로 수집될 때 pg_wal_lsn_diff(lsn1, lsn2) 함수를 사용하여 생성된 미리 쓰기 로깅의 바이트/초를 제공할 수 있습니다.
이 함수는 트랜잭션 비율과 미리 쓰기 로깅 파일 수행 방식을 이해하는 데 유용한 측정항목입니다. |
원격 위치로 미리 쓰기 로깅 데이터 스트리밍
Barman을 사용하면 복구 시 데이터 손실이 거의 없도록 미리 쓰기 로깅 데이터가 원격 위치로 실시간 스트리밍되도록 설정할 수도 있습니다. 실시간 스트리밍에도 불구하고 스트리밍이 원격 Barman 서버에 쓰는 작업은 기본적으로 비동기식이므로 커밋된 트랜잭션이 손실될 가능성이 약간 있습니다. 하지만 미리 쓰기 로깅을 저장하고 상태 응답을 소스 데이터베이스로 다시 보내는 동기 모드를 사용하여 미리 쓰기 로깅 스트리밍을 설정할 수 있습니다. 이 방법은 트랜잭션이 계속되기 전에 이 쓰기가 완료될 때까지 기다려야 하는 경우 트랜잭션 속도를 늦출 수 있습니다.
백업 일정
대부분의 환경에서 백업은 일반적으로 주 단위로 예약됩니다. 다음은 일반적인 주간 백업 일정입니다.
- 일요일: 전체 백업
- 월요일, 화요일: 백업
- 수요일: 차등 백업
- 목요일, 금요일: 증분 백업
- 토요일: 차등 백업
이 일반적인 일정을 사용하면 1주일의 롤링 복구 기간에 전체 백업 최대 3개와 필요한 증분 또는 차등 백업을 저장할 수 있는 공간이 필요합니다. 이 방식은 일요일에 전체 백업 중에 발생하는 장애 복구를 지원하며 백업이 시작되기 전에 데이터베이스 복구가 이전 일요일까지 확장되어야 합니다.
RPO가 높아질 수 있는 RTO를 최소화하기 위해 추가 데이터베이스가 연속 복구 모드로 작동할 수 있습니다. 여기에는 백업을 재생하고 새 미리 쓰기 로깅 파일을 보관처리하고 재생하여 보조 환경을 지속적으로 업데이트하는 작업이 포함됩니다. 잠재적인 데이터 손실을 반영하는 실제 RPO는 트랜잭션 빈도, 미리 쓰기 로깅 파일 크기, 미리 쓰기 로깅 스트리밍 사용에 따라 달라집니다.
Kubernetes 이외의 환경에서 복원
Kubernetes 이외의 배포의 경우 AlloyDB Omni 데이터베이스 복원에는 Docker 컨테이너를 중지한 후 데이터를 복원하거나 데이터를 다른 위치에 복원하고 복원된 데이터를 사용하여 새 Docker 인스턴스를 실행하는 작업이 포함됩니다. 컨테이너가 다시 시작되면 복원된 데이터로 데이터베이스에 액세스할 수 있습니다.
복구 옵션에 대한 자세한 내용은 pgBackRest를 사용하여 AlloyDB Omni 클러스터 복원 및 Barman을 사용하여 AlloyDB Omni 클러스터 복원을 참조하세요.
연산자를 사용하여 Kubernetes에서 복원
Kubernetes에서 데이터베이스를 복원하기 위해 연산자는 명명된 백업 또는 특정 시점(PIT)의 클론에서 같은 Kubernetes 클러스터와 네임스페이스로 복구를 제공합니다. 다른 Kubernetes 클러스터에 데이터베이스를 클론하려면 pgBackRest를 사용합니다. 자세한 내용은 Kubernetes에서 백업 및 복원 및 Kubernetes 백업에서 데이터베이스 클러스터 클론 개요를 참조하세요.
구현
가용성 참조 아키텍처를 선택할 때는 다음 이점, 제한사항, 대안을 고려하세요.
이점
- 사용과 관리가 간단하며 RTO/RPO가 관대한 중요하지 않은 데이터베이스에 적합합니다.
- 최소한의 추가 하드웨어가 필요합니다.
- 전체 재해 복구 계획에는 항상 백업이 필요합니다.
- 복구 기간 내 특정 시점으로 복구할 수 있습니다.
제한사항
- 보관 요구사항에 따라 스토리지 요구사항이 데이터베이스 자체보다 클 수 있습니다.
- 복구 속도가 느릴 수 있으며 RTO가 높아질 수 있습니다.
- 데이터베이스 장애 후 현재 미리 쓰기 로깅 데이터 가용성에 따라 일부 데이터가 손실될 수 있으며 이는 RPO에 부정적인 영향을 미칠 수 있습니다.
대안
다음 단계
- AlloyDB Omni 가용성 참조 아키텍처 개요
- AlloyDB Omni 향상된 가용성
- AlloyDB Omni 프리미엄 가용성
- Kubernetes에 AlloyDB Omni 설치
- AlloyDB Omni용 pgBackRest 설정
- AlloyDB Omni용 Barman 설정
- Kubernetes에서 백업 및 복원
- pgBackRest를 사용하여 AlloyDB Omni 클러스터 복원
- Barman을 사용하여 AlloyDB Omni 클러스터 복원
- Kubernetes에서 백업 및 복원
- Kubernetes 백업에서 데이터베이스 클러스터 클론 개요