Memastikan keandalan dan kualitas penyiapan Patroni dengan ketersediaan tinggi sangat penting untuk mempertahankan operasi database yang berkelanjutan dan meminimalkan waktu henti. Halaman ini memberikan panduan komprehensif untuk menguji cluster Patroni Anda, yang mencakup berbagai skenario kegagalan, konsistensi replikasi, dan mekanisme failover.
Menguji penyiapan Patroni
Hubungkan ke salah satu instance patroni Anda (
alloydb-patroni1,alloydb-patroni2, ataualloydb-patroni3) dan buka folder patroni AlloyDB Omni.cd /alloydb/
Periksa log Patroni.
docker compose logs alloydbomni-patroni
Entri terakhir harus mencerminkan informasi tentang node Patroni. Anda akan melihat sesuatu yang mirip dengan berikut ini.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockHubungkan ke instance yang menjalankan Linux yang memiliki konektivitas jaringan ke instance Patroni utama Anda,
alloydb-patroni1, dan dapatkan informasi tentang instance tersebut. Anda mungkin perlu menginstal alatjqdengan menjalankansudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
Anda akan melihat sesuatu yang mirip dengan yang ditampilkan berikut.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Memanggil endpoint Patroni HTTP API di node Patroni akan menampilkan berbagai detail tentang status dan konfigurasi instance PostgreSQL tertentu yang dikelola oleh Patroni, termasuk informasi status cluster, linimasa, informasi WAL, dan pemeriksaan kondisi yang menunjukkan apakah node dan cluster sudah aktif dan berjalan dengan benar.
Menguji konfigurasi HAProxy
Di komputer yang memiliki browser dan konektivitas jaringan ke node HAProxy Anda, buka alamat berikut:
http://haproxy:7000. Atau, Anda dapat menggunakan alamat IP eksternal instance HAProxy, bukan nama host-nya.Anda akan melihat sesuatu yang mirip dengan screenshot berikut.
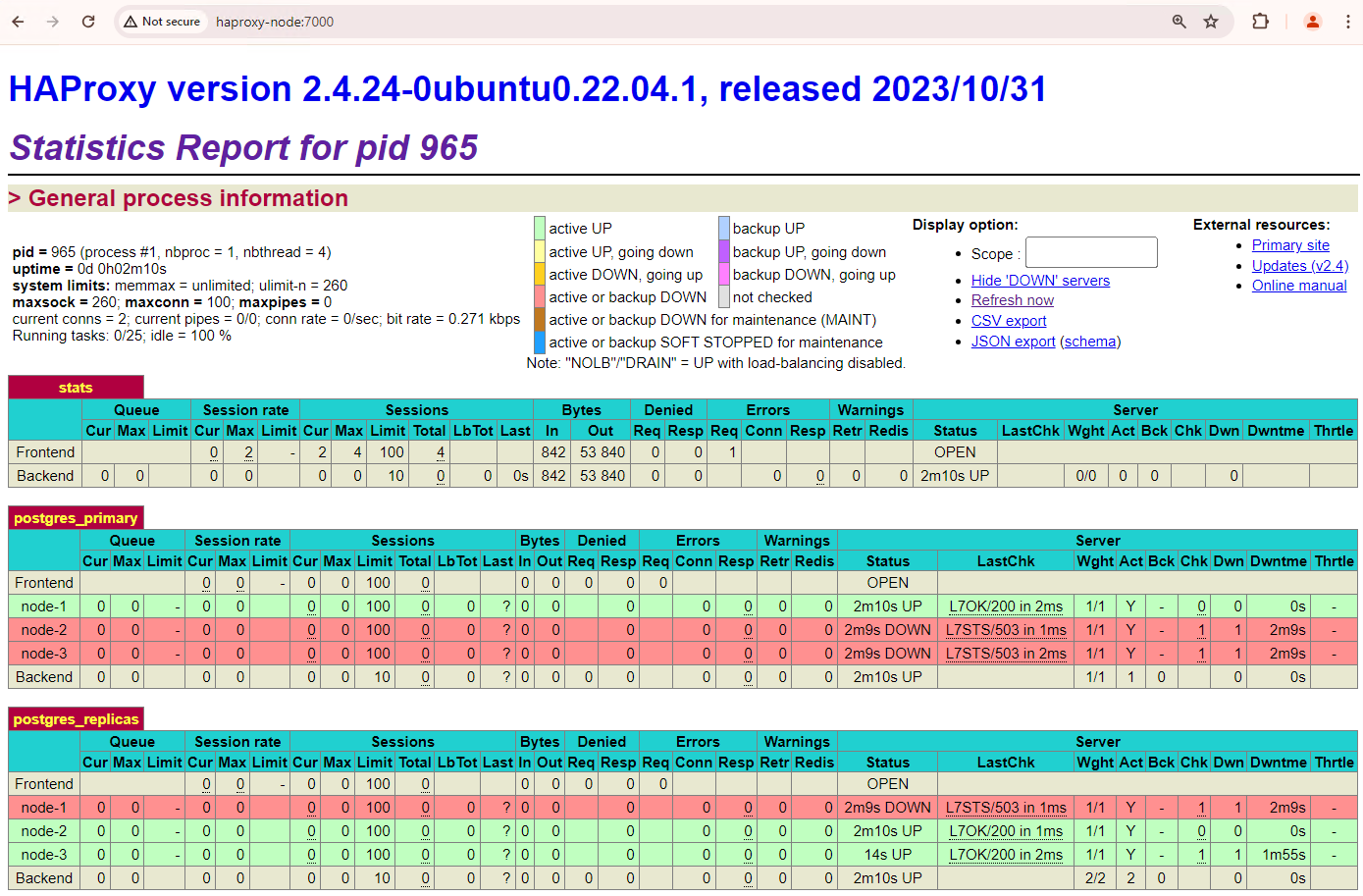
Gambar 1. Halaman status HAProxy yang menampilkan status respons dan latensi node Patroni.
Di dasbor HAProxy, Anda dapat melihat status kondisi dan latensi node Patroni utama,
patroni1, dan dua replika,patroni2danpatroni3.Anda dapat menjalankan kueri untuk memeriksa statistik replikasi di cluster Anda. Dari klien seperti pgAdmin, hubungkan ke server database utama Anda melalui HAProxy dan jalankan kueri berikut.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Anda akan melihat sesuatu yang mirip dengan diagram berikut, yang menunjukkan bahwa
patroni2danpatroni3melakukan streaming daripatroni1.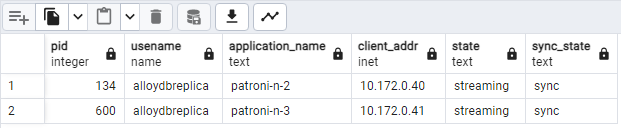
Gambar 2. Output pg_stat_replication yang menampilkan status replikasi node Patroni.
Menguji failover otomatis
Di bagian ini, di cluster tiga node, kita akan menyimulasikan gangguan pada node utama dengan menghentikan penampung Patroni yang terpasang dan berjalan. Anda dapat menghentikan layanan Patroni di server utama untuk menyimulasikan gangguan atau menerapkan beberapa aturan firewall untuk menghentikan komunikasi ke node tersebut.
Di instance Patroni utama, buka folder Patroni AlloyDB Omni.
cd /alloydb/
Hentikan penampung.
docker compose down
Anda akan melihat sesuatu yang mirip dengan output berikut. Tindakan ini akan memastikan bahwa penampung dan jaringan telah dihentikan.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedMuat ulang dasbor HAProxy dan lihat cara failover terjadi.
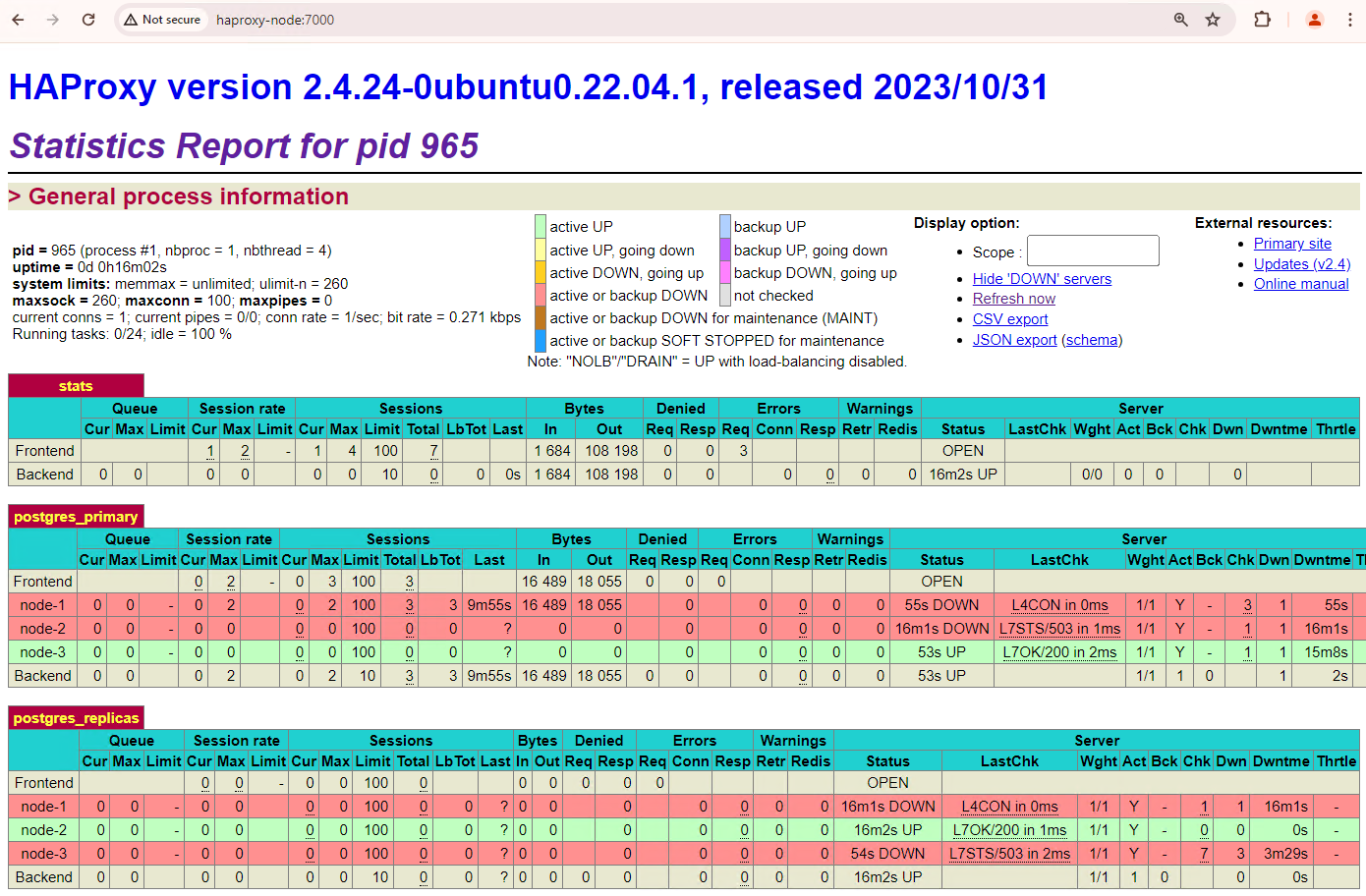
Gambar 3. Dasbor HAProxy yang menampilkan failover dari node primer ke node standby.
Instance
patroni3menjadi primer baru, danpatroni2adalah satu-satunya replika yang tersisa.patroni1, yang merupakan primer sebelumnya, tidak aktif dan health check-nya gagal.Patroni melakukan dan mengelola failover melalui kombinasi pemantauan, konsensus, dan orkestrasi otomatis. Segera setelah node primer gagal memperbarui masa berlakunya dalam waktu tunggu yang ditentukan, atau jika node tersebut melaporkan kegagalan, node lain dalam cluster akan mengenali kondisi ini melalui sistem konsensus. Node yang tersisa berkoordinasi untuk memilih replika yang paling sesuai untuk dipromosikan sebagai replika utama baru. Setelah replika kandidat dipilih, Patroni mempromosikan node ini menjadi replika utama dengan menerapkan perubahan yang diperlukan, seperti memperbarui konfigurasi PostgreSQL dan memutar ulang semua catatan WAL yang belum diproses. Kemudian, node utama baru memperbarui sistem konsensus dengan statusnya dan replika lainnya mengonfigurasi ulang dirinya untuk mengikuti node utama baru, termasuk mengganti sumber replikasinya dan berpotensi mengejar transaksi baru. HAProxy mendeteksi primary baru dan mengarahkan ulang koneksi klien dengan tepat, sehingga memastikan gangguan minimal.
Dari klien seperti pgAdmin, hubungkan ke server database Anda melalui HAProxy dan periksa statistik replikasi di cluster Anda setelah failover.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Anda akan melihat sesuatu yang mirip dengan diagram berikut, yang menunjukkan bahwa hanya
patroni2yang sedang melakukan streaming.
Output pg_stat_replication Gambar 4. yang menunjukkan status replikasi node Patroni setelah failover.
Cluster tiga node Anda dapat bertahan dari satu pemadaman lagi. Jika Anda menghentikan node utama saat ini,
patroni3, failover lain akan terjadi.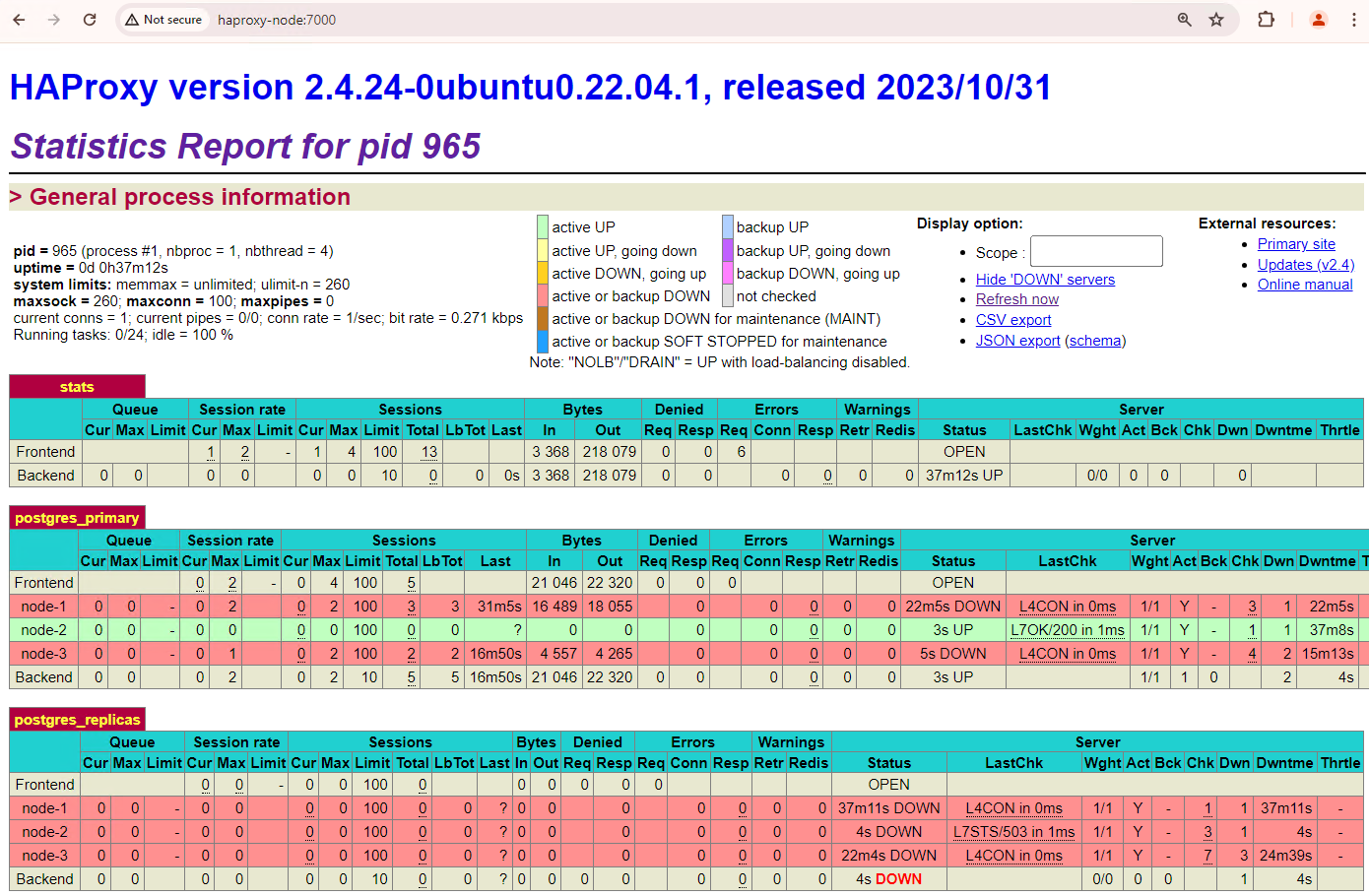
Gambar 5. Dasbor HAProxy yang menampilkan failover dari node utama,
patroni3, ke node standby,patroni2.
Pertimbangan penggantian
Fallback adalah proses untuk mengaktifkan kembali node sumber sebelumnya setelah terjadi failover. Pengalihan otomatis umumnya tidak direkomendasikan dalam cluster database dengan ketersediaan tinggi karena beberapa masalah penting, seperti pemulihan yang tidak lengkap, risiko skenario split-brain, dan jeda replikasi.
Di cluster Patroni, jika Anda mengaktifkan dua node yang Anda simulasikan pemadaman listriknya, node tersebut akan bergabung kembali ke cluster sebagai replika standby.
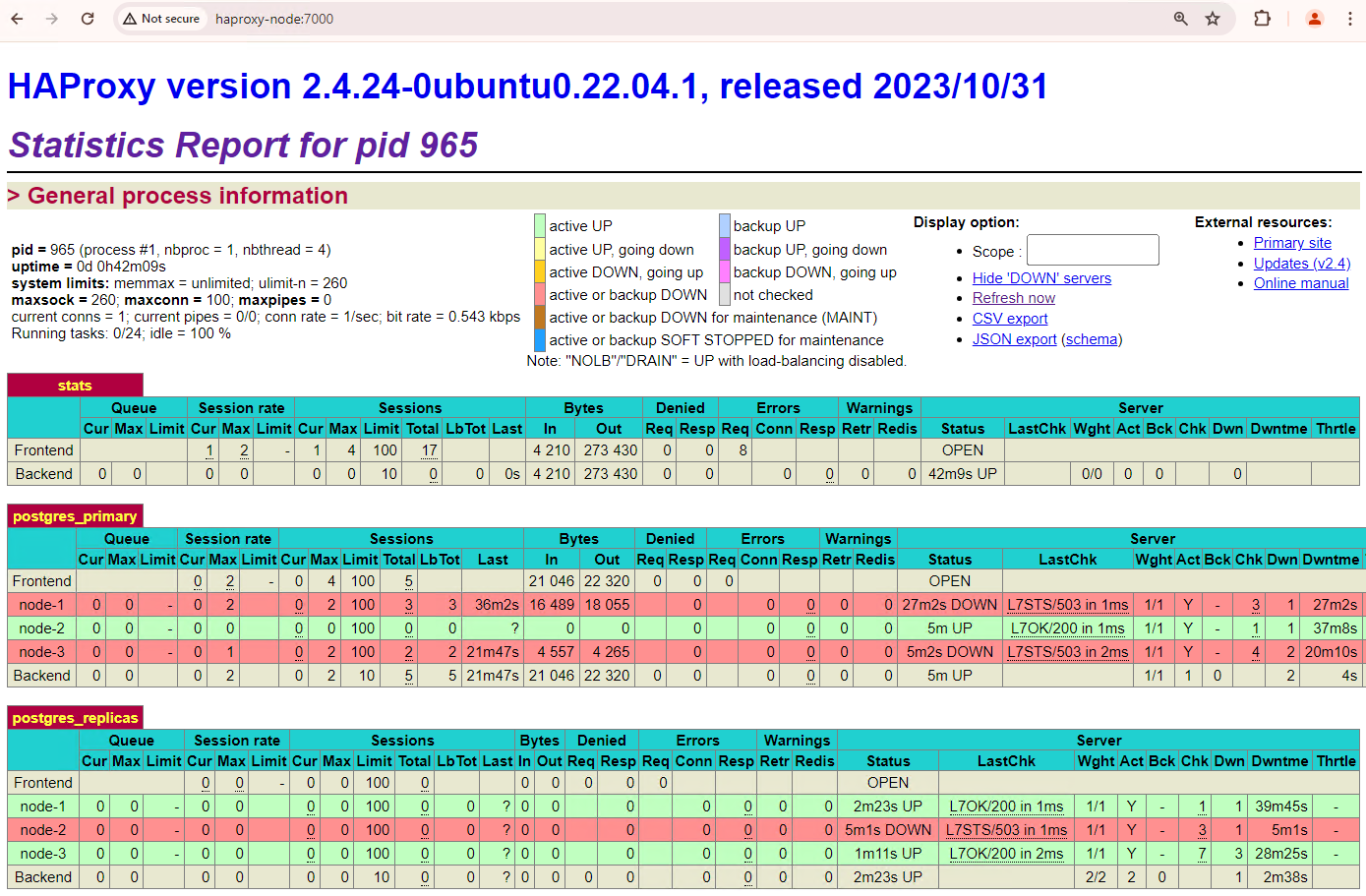
Gambar 6. Dasbor HAProxy yang menampilkan pemulihan patroni1 dan
patroni3 sebagai node standby.
Sekarang patroni1 dan patroni3 direplikasi dari patroni2 primer saat ini.

Gambar 7. Output pg_stat_replication yang menunjukkan status replikasi node Patroni setelah fallback.
Jika ingin melakukan failback secara manual ke primer awal, Anda dapat melakukannya dengan menggunakan antarmuka command line patronictl. Dengan memilih penggantian manual, Anda dapat memastikan proses pemulihan yang lebih andal, konsisten, dan terverifikasi secara menyeluruh, sehingga menjaga integritas dan ketersediaan sistem database Anda.