AlloyDB Omni は、ダウンロード可能なデータベース ソフトウェア パッケージであり、AlloyDB for PostgreSQL の簡素化されたバージョンを、お客様ご自身のコンピューティング環境にデプロイできます。AlloyDB Omni とフルマネージド AlloyDB for PostgreSQL サービスは、 Google Cloud 上で同じコア コンポーネントを共有しています。AlloyDB for PostgreSQL は、WAL のパフォーマンスを最適化するクラウドネイティブ ストレージ レイヤを使用しますが、AlloyDB Omni は PostgreSQL で使用されているのと同じ標準ファイル システム インターフェースを使用します。
AlloyDB Omni はポータビリティに優れ、次のような多くの環境で実行できます。
- データセンター
- ノートパソコン
- クラウドベースの VM インスタンス
AlloyDB Omni のユースケース
AlloyDB Omni は、次のようなシナリオに適しています。
- スケーラブルでパフォーマンスの高い PostgreSQL が必要だが、規制要件またはデータ主権に関する要件により、クラウドでデータベースを実行できない場合。
- インターネットから切断されても実行し続けるデータベースが必要な場合。
- レイテンシを最小限に抑えるために、データベースをユーザーの地理的位置にできるだけ近づける必要がある場合。
- クラウドへの完全な移行にコミットせずに、以前のデータベースから移行する手段が必要な場合。
AlloyDB Omni には、 Google Cloudのオペレーションに依存する AlloyDB for PostgreSQL の機能は含まれていません。プロジェクトを AlloyDB for PostgreSQL によるフルマネージドのスケーリング、セキュリティ、可用性機能にアップグレードしたい場合には、他の初期データをインポートする場合と同様に、AlloyDB Omni データを AlloyDB for PostgreSQL クラスタに移行できます。
主な機能
- PostgreSQL 互換のデータベース サーバー。
- AlloyDB AI のサポート。運用データを使用して、エンタープライズ グレードの生成 AI アプリケーションを構築できます。
- Vertex AI Model Garden やオープンソースの生成 AI ツールなど、 Google Cloud AI エコシステムとの統合。
Google Cloud で AlloyDB for PostgreSQL の Autopilot 機能をサポート。これにより、AlloyDB Omni の自己管理および自己調整が可能になります。
たとえば、AlloyDB Omni は自動メモリ管理や、古いデータの適応型自動バキュームをサポートしています。
頻繁に実行されるクエリを分析し、クエリのパフォーマンスを向上させる新しいインデックスを推奨するインデックス アドバイザー。
AlloyDB Omni のカラム型エンジン。頻繁にクエリされるデータをインメモリ カラム型形式で保持し、ビジネス インテリジェンス、レポート、トランザクションと分析のハイブリッド処理(HTAP)のワークロードでパフォーマンスを向上させます。
Google のパフォーマンス テストでは、AlloyDB Omni のトランザクション ワークロードは標準の PostgreSQL よりも 2 倍以上高速で、分析クエリは最大 100 倍高速です。
AlloyDB Omni の仕組み
AlloyDB Omni は、スタンドアロン サーバーとして、または Kubernetes 環境の一部としてインストールできます。
AlloyDB Omni は、お客様の環境にインストールした Docker コンテナ内で実行されます。AlloyDB Omni の実行には、SSD ストレージ、および CPU あたり 8 GB 以上のメモリを備えた Linux システムを使用することをおすすめします。
AlloyDB Omni Kubernetes オペレーターは、CNCF 準拠のほとんどの Kubernetes 環境で AlloyDB Omni の実行を可能にする、Kubernetes API の拡張機能です。詳細については、Kubernetes に AlloyDB Omni をインストールするをご覧ください。
アプリケーションは、標準の PostgreSQL データベース サーバーに接続して通信するのと同じように、AlloyDB Omni インストール環境に接続して通信します。ユーザー アクセス制御も PostgreSQL 標準に依存しています。
カラム型エンジンに対するロギングからバキュームまで、AlloyDB Omni のデータベース動作を各種のデータベース フラグを使用して構成できます。
AlloyDB Omni をコンテナとして実行するメリット
Google は、Docker や Podman などのコンテナ ランタイムで実行できるコンテナとして AlloyDB Omni を配布しています。運用面では、コンテナには次のような利点があります。
- 透明性の高い依存関係管理: 必要な依存関係がすべてコンテナにバンドルされ、Google によってテストされるので、AlloyDB Omni との完全な互換性が保証されます。
- ポータビリティ: AlloyDB Omni は、環境を問わず一貫して動作します。
- セキュリティの分離: AlloyDB Omni コンテナがホストマシン上の何にアクセスできるかを選択できます。
- リソース管理: AlloyDB Omni コンテナで使用されるコンピューティング リソースの量を定義できます。
- シームレスなパッチ適用とアップグレード: コンテナにパッチを適用するには、既存のイメージを新しいイメージに置き換えるだけです。
データのバックアップと障害復旧
AlloyDB Omni の備える継続的なバックアップおよび復元システムを使用すると、調整可能な保持期間内の任意の時点に基づいて、新しいデータベース クラスタを作成できます。これにより、データ損失の事故から迅速に復元できます。
さらに、AlloyDB Omni では、データベース クラスタのデータの完全なバックアップをオンデマンドで、または定期的に作成して保存できます。バックアップから AlloyDB Omni データベース クラスタにはいつでも復元できます。このクラスタには、バックアップの作成時点で元のデータベース クラスタに入っていたすべてのデータが含まれます。
障害復旧のもう一つの方法として、別のデータセンターにセカンダリ データベース クラスタを作成することで、データセンター間のレプリケーションを実現する方法もあります。AlloyDB Omni は、指定されたプライマリ データベース クラスタから各セカンダリ クラスタに、データを非同期でストリーミングします。必要に応じて、セカンダリ データベース クラスタをプライマリ AlloyDB Omni データベース クラスタにプロモートできます。
AlloyDB Omni VM のコンポーネント
VM 上の AlloyDB Omni は 2 つのアーキテクチャ コンポーネント、つまり AlloyDB for PostgreSQL の拡張機能を含む PostgreSQL コンポーネントと、AlloyDB for PostgreSQL コンポーネントとで構成されています。次の図は、この 2 つのコンポーネント セットを示します。この図では、各コンポーネントが VM またはサーバーのどのインフラストラクチャ レイヤに存在するのかと、各コンポーネントに期待できる関連機能の概要を示します。
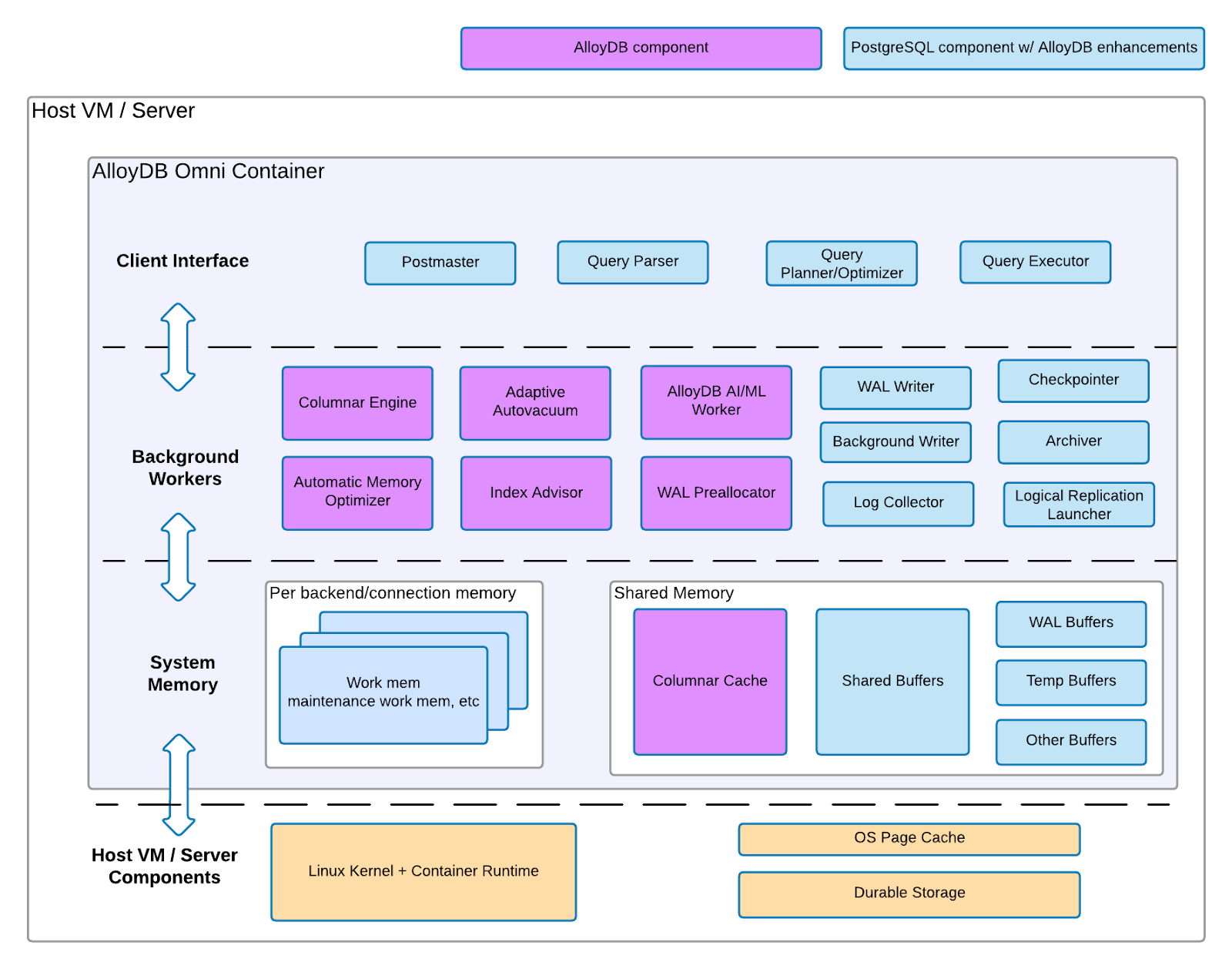
図 1.AlloyDB Omni アーキテクチャ
データベース エンジン
ここでは、コンテナ内の AlloyDB Omni のデータベース アーキテクチャについて説明します。このドキュメントは、PostgreSQL について知識があることを前提としています。
データベース エンジンは次のタスクを実行します。
- クライアントからのクエリを実行可能なプランに変換します。
- クエリを満たすために必要なデータを検索します。
- 必要なフィルタリング、並べ替え、集計を実行します。
- 結果をクライアントに返します。
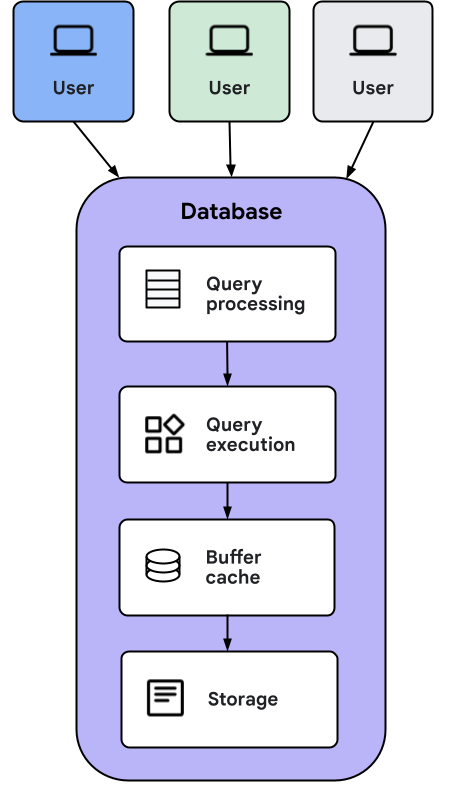
クライアント アプリケーションが AlloyDB Omni にクエリを送信すると、次の処理が行われます。
- クエリがクエリ処理レイヤによって実行プランに変換され、実行レイヤに渡されます。
- クエリ実行レイヤは、クエリへのレスポンスを計算するために必要なオペレーションを実行します。
- 実行中、データはバッファ キャッシュから読み込まれるか、ストレージから直接読み込まれます。データがストレージから読み込まれると、ストレージのデータは将来の使用のためにキャッシュに保存されます。
クライアントからのクエリの処理には、CPU、メモリ、I/O、ネットワーク、同期プリミティブ(データベース ロックなど)といったリソースが使用されます。パフォーマンス チューニングは、クエリ実行の各ステップでリソース使用率を最適化することを目的とした作業です。
高パフォーマンスのデータベース エンジンを設計するには、必要最小限のリソースでクエリに応答することが目標となります。この目標を達成するには、まず、データモデルとクエリの設計が優れていることが重要です。
- 最小限のデータを参照してクエリに回答するにはどうすればよいか
- 検索空間と I/O を削減するにはどのようなインデックスが必要か
- データの並べ替えには CPU が必要とされ、データセットが大規模であればディスク アクセスも必要となるが、データの並べ替えを回避するにはどうすればよいか
データ ストレージ
AlloyDB Omni は、基盤となるファイル システムに保存される、固定サイズのページにデータを保存します。クエリがデータにアクセスする必要がある場合、AlloyDB Omni はまずバッファプールをチェックします。必要なデータを保持するページがバッファプールにない場合は、必要なページをファイル システムから読み取ります。バッファプールからのデータへのアクセスは、ファイル システムから読み取るよりもはるかに高速です。そのため、アプリケーションがアクセスするデータ量に合わせて、バッファプールのサイズを最大化することが重要な要素となります。
リソース管理
AlloyDB Omni は動的メモリ管理を使用することで、システムのメモリ需要に応じて、構成した境界内でバッファプールを動的に拡大および縮小します。つまり、バッファプール サイズを手動で調整する必要がありません。パフォーマンスの問題を診断する際は、まずバッファプールのヒット率と読み取り率の指標を検証して、アプリケーションがバッファプールのメリットを享受しているかどうかを確認します。そうでない場合は、アプリケーションのデータセットがバッファプールに収まらないことを示します。メモリ容量の大きいマシンに変更することを検討してください。
データの取得、フィルタリング、集計、並べ替え、予測のプロセスには、すべてデータベース サーバー上の CPU リソースが必要となります。このプロセスに必要とされる CPU リソースの量を減らすには、操作する必要があるデータの量を最小限に抑えます。データベース サーバーの CPU 使用率をモニタリングして、安定状態の使用率が 70% 程度となるように管理します。このような状態を維持すると、使用率の急増やアクセス パターンの変化に備え、サーバーに十分な余裕を持たせることができます。使用率が 100% に近づくと、プロセスのスケジューリングとコンテキスト スイッチングによるオーバーヘッドが生じ、システムの他の部分でボトルネックが発生する可能性があります。高い CPU 使用率も、マシンの仕様を決定する際に使用する重要な指標です。
1 秒あたりの入出力オペレーション(IOPS)は、データベース アプリケーションのパフォーマンスにおいて重要な要素です。これは、基盤となるストレージ デバイスがデータベースに提供できる 1 秒あたりの入出力オペレーションの数です。データベース ストレージの IOPS の上限に達しないようにするには、バッファプールに収まるデータの量を最大化して、ストレージへの読み取りと書き込みを最小限に抑えます。
カラム型エンジン
カラム型エンジンは、次のコンポーネントを提供することで、スキャン、結合、集計の SQL クエリ処理を高速化します。
インメモリ カラムストア: 選択した列のテーブルデータとマテリアライズド ビュー データを列指向形式で格納します。デフォルトでは、カラムストアは 1 GB のメモリを使用します。カラムストアで使用可能なメモリ量を変更するには、AlloyDB Omni インスタンスで使用される
postgresql.confでgoogle_columnar_engine.memory_size_in_mbパラメータを設定します。カラム型クエリ プランナーと実行エンジン: クエリでカラムストアを使用できます。
自動的なメモリ管理
自動メモリ マネージャーは、AlloyDB Omni インスタンス全体のメモリ使用量を継続的にモニタリングして最適化します。ワークロードを実行すると、このモジュールはメモリ プレッシャーに基づき、共有バッファ キャッシュのサイズを調整します。デフォルトでは、自動メモリ マネージャーは上限をシステムメモリの 80% に設定し、共有バッファ キャッシュにシステムメモリの 10% を割り当てます。共有バッファ キャッシュのサイズの上限を変更するには、AlloyDB Omni インスタンスで使用される postgresql.conf に shared_buffers パラメータを設定します。
適応型自動バキューム
適応型自動バキュームは、データベースのワークロードに基づいてオペレーションを分析し、バキュームの頻度を自動的に調整します。この自動調整により、ワークロードが変化しても、バキューム プロセスによる干渉を生じさせることなく、データベースがピーク パフォーマンスで実行されます。
適応型自動バキュームは、次の要素に基づいてバキューム オペレーションの頻度と強度を決定します。
- データベースのサイズ
- データベース内のデッドタプルの数
- データベース内のデータの経過時間
- 1 秒あたりのトランザクション数と推定バキューム速度
適応型自動バキュームには、次の利点があります。
- 動的バキューム リソース管理: AlloyDB では、固定費用制限の代わりにリアルタイムのリソース統計情報を使用して、バキューム ワーカーを調整します。システムの負荷が高い場合には、バキューム プロセスと関連するリソース使用率がスロットリングされます。十分なメモリが使用可能な場合は、エンドツーエンドのバキューム時間を短縮するために、
maintenance_work_memに追加メモリが割り当てられます。 - 動的 XID スロットリング: バキューム処理の進捗状況とトランザクション ID の消費速度を自動的かつ継続的にモニタリングします。トランザクション ID ラップアラウンドのリスクが検知されると、AlloyDB Omni はトランザクションの処理速度を遅くして ID の使用量をスロットリングします。また、AlloyDB Omni は、トランザクション ID スペースの前進と解放をブロックしているテーブルを処理するために、バキューム ワーカーにさらにリソースを割り当てます。このプロセスでは、トランザクション ID がセーフゾーンに収まるまで、秒あたりのトランザクション総数が減少します(
AdaptiveVacuumNewXidDelayを待機しているセッションとして確認できます)。トランザクション ID の経過時間が長くなると、バキューム ワーカーは動的に増加します。 - 大きなテーブルに対する効率的なバキューム処理: テーブルのバキューム処理のタイミングを決定するために使用されるデフォルトの PostgreSQL ロジックは、
pg_stat_all_tablesに保存されているテーブル固有の統計情報に基づいています。これにはデッドタプルの比率が含まれています。このロジックは小さなテーブルでは有効ですが、大規模で頻繁に更新されるテーブルでは効率的に機能しない可能性があります。AlloyDB Omni は、自動バキュームをより頻繁にトリガーできる、最新のスキャン メカニズムを備えています。このスキャン メカニズムは、大きなテーブルのチャンクをスキャンし、デフォルトの PostgreSQL ロジックよりも効率的にデッドタプルを削除します。 - 警告メッセージをログに記録する: AlloyDB Omni では、長時間実行されているトランザクション、準備済みトランザクション、ターゲットを失うレプリケーション スロットなどのバキュームの阻害要因が検出されると、PostgreSQL ログに警告が登録されます。これにより、問題にタイムリーに対応できます。
AI / ML ワーカー
AlloyDB Omni では、AI / ML バックグラウンド ワーカーが、データベースから Vertex AI モデルを直接呼び出すために必要なすべての機能を提供します。AI / ML ワーカーは、omni ml worker というプロセスとして実行されます。
次のステップ
- AlloyDB Omni のデプロイ環境を選択する。
- AlloyDB Omni for Kubernetes を使ってみる。
- コンテナ用 AlloyDB Omni を使ってみる