고가용성 Patroni 설정의 안정성과 품질을 보장하는 것은 지속적인 데이터베이스 운영을 유지하고 다운타임을 최소화하는 데 중요합니다. 이 페이지에서는 다양한 장애 시나리오, 복제 일관성, 장애 조치 메커니즘을 다루는 Patroni 클러스터 테스트에 관한 포괄적인 가이드를 제공합니다.
Patroni 설정 테스트
patroni 인스턴스 (
alloydb-patroni1,alloydb-patroni2또는alloydb-patroni3)에 연결하고 AlloyDB Omni patroni 폴더로 이동합니다.cd /alloydb/
Patroni 로그를 검사합니다.
docker compose logs alloydbomni-patroni
마지막 항목에는 Patroni 노드에 관한 정보가 반영되어야 합니다. 다음과 유사한 내용이 표시됩니다.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock기본 Patroni 인스턴스
alloydb-patroni1에 대한 네트워크 연결이 있는 Linux를 실행하는 인스턴스에 연결하고 인스턴스에 관한 정보를 가져옵니다.sudo apt-get install jq -y를 실행하여jq도구를 설치해야 할 수도 있습니다.curl -s http://alloydb-patroni1:8008/patroni | jq .
다음과 비슷한 내용이 표시됩니다.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Patroni 노드에서 Patroni HTTP API 엔드포인트를 호출하면 클러스터 상태 정보, 타임라인, WAL 정보, 노드 및 클러스터가 올바르게 작동하는지 나타내는 상태 확인 등 Patroni에서 관리하는 특정 PostgreSQL 인스턴스의 상태 및 구성에 관한 다양한 세부정보가 노출됩니다.
HAProxy 설정 테스트
브라우저가 있고 HAProxy 노드에 네트워크 연결이 설정된 머신에서
http://haproxy:7000주소로 이동합니다. 또는 호스트 이름 대신 HAProxy 인스턴스의 외부 IP 주소를 사용할 수 있습니다.다음 스크린샷과 유사한 화면이 표시됩니다.
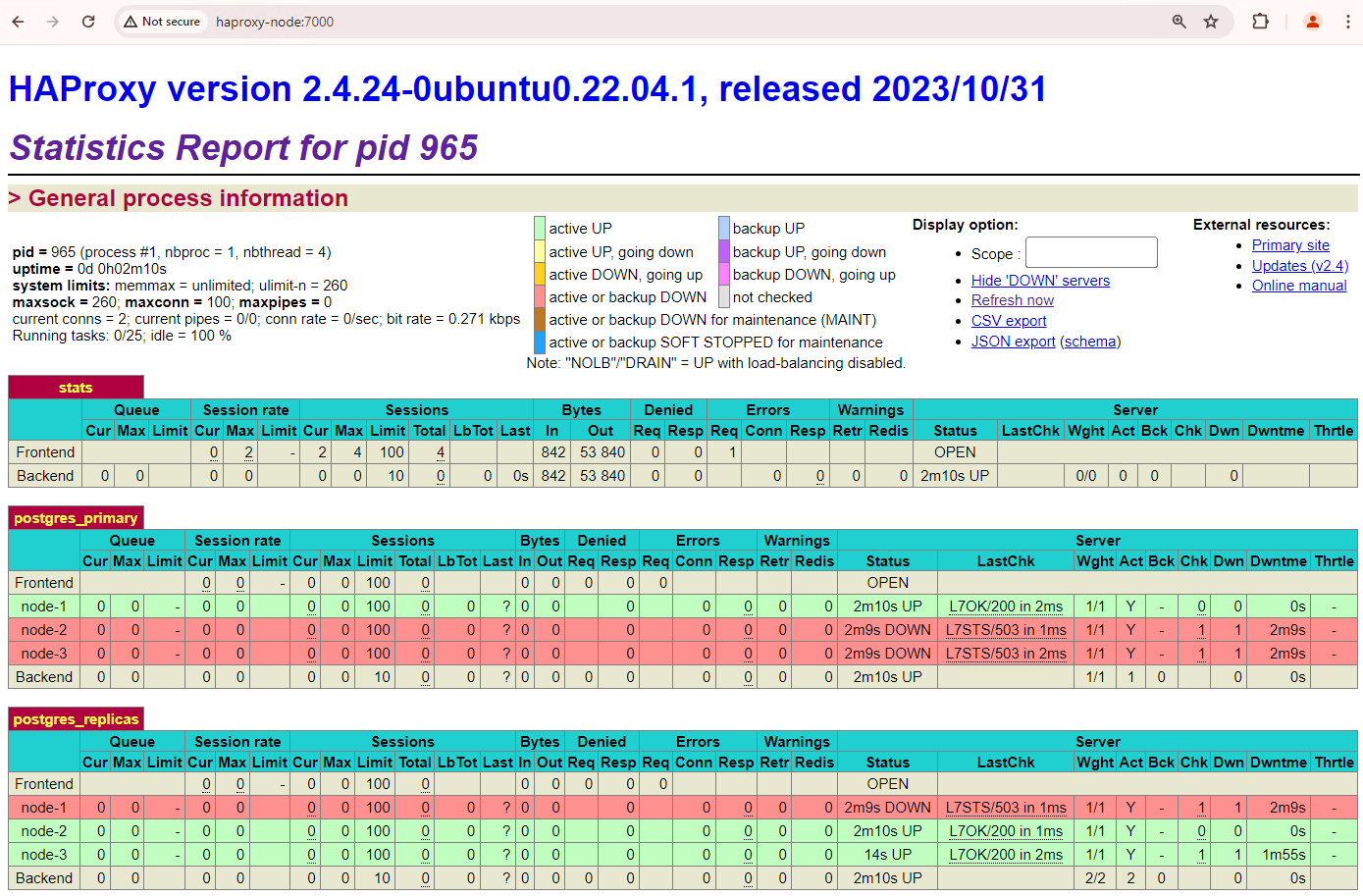
그림 1. Patroni 노드의 상태 및 지연 시간을 보여주는 HAProxy 상태 페이지
HAProxy 대시보드에서 기본 Patroni 노드
patroni1및 두 개의 복제본patroni2및patroni3의 상태 및 지연 시간을 확인할 수 있습니다.쿼리를 실행하여 클러스터의 복제 통계를 확인할 수 있습니다. pgAdmin과 같은 클라이언트에서 HAProxy를 통해 기본 데이터베이스 서버에 연결하고 다음 쿼리를 실행합니다.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;다음 다이어그램과 유사한 내용이 표시되어
patroni2및patroni3가patroni1에서 스트리밍되고 있음을 보여줍니다.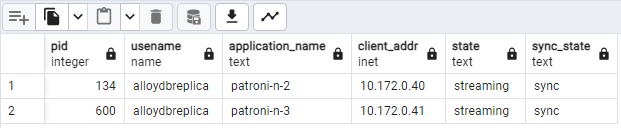
그림 2. Patroni 노드의 복제 상태를 보여주는 pg_stat_replication 출력
자동 장애 조치 테스트
이 섹션에서는 3노드 클러스터에서 연결된 실행 중인 Patroni 컨테이너를 중지하여 기본 노드의 중단을 시뮬레이션합니다. 기본 노드에서 Patroni 서비스를 중지하여 중단을 시뮬레이션하거나 일부 방화벽 규칙을 적용하여 해당 노드와의 통신을 중지할 수 있습니다.
기본 Patroni 인스턴스에서 AlloyDB Omni Patroni 폴더로 이동합니다.
cd /alloydb/
컨테이너를 중지합니다.
docker compose down
다음과 같은 출력이 표시됩니다. 이렇게 하면 컨테이너와 네트워크가 중지되었음을 확인할 수 있습니다.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedHAProxy 대시보드를 새로고침하고 장애 조치가 어떻게 이루어지는지 확인합니다.
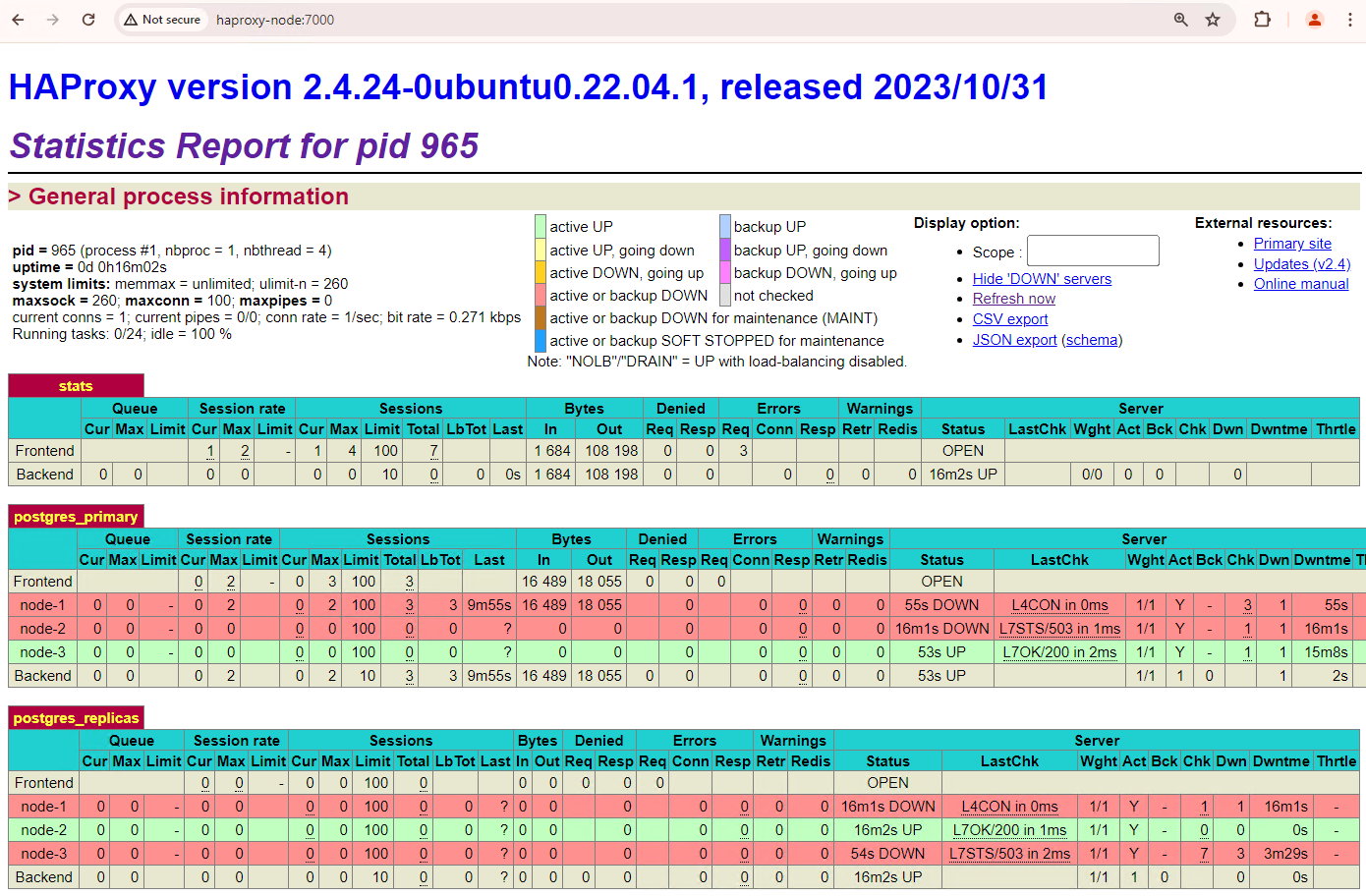
그림 3. 기본 노드에서 대기 노드로의 장애 조치를 보여주는 HAProxy 대시보드
patroni3인스턴스가 새 기본 인스턴스가 되었고patroni2가 유일하게 남은 복제본입니다. 이전 기본 노드인patroni1가 다운되어 상태 확인에 실패합니다.Patroni는 모니터링, 합의, 자동화된 조정을 조합하여 장애 조치를 실행하고 관리합니다. 기본 노드가 지정된 제한 시간 내에 임대를 갱신하지 못하거나 실패를 보고하면 클러스터의 다른 노드는 합의 시스템을 통해 이 상태를 인식합니다. 나머지 노드는 새 기본 노드로 승격할 가장 적합한 복제본을 선택하기 위해 협력합니다. 후보 복제본이 선택되면 Patroni는 PostgreSQL 구성 업데이트, 대기 중인 WAL 레코드 재생 등 필요한 변경사항을 적용하여 이 노드를 기본 노드로 승격합니다. 그런 다음 새 기본 노드가 상태로 합의 시스템을 업데이트하고 다른 복제본은 복제 소스를 전환하고 새 트랜잭션을 따라잡는 등 새 기본을 따르도록 다시 구성합니다. HAProxy는 새 기본 노드를 감지하고 그에 따라 클라이언트 연결을 리디렉션하여 서비스 중단을 최소화합니다.
pgAdmin과 같은 클라이언트에서 HAProxy를 통해 데이터베이스 서버에 연결하고 장애 조치 후 클러스터의 복제 통계를 확인합니다.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;현재
patroni2만 스트리밍되고 있음을 보여주는 다음 다이어그램과 유사한 내용이 표시됩니다.
그림 4. 장애 조치 후 Patroni 노드의 복제 상태를 보여주는 pg_stat_replication 출력
노드 3개 클러스터는 한 번 더 중단될 수 있습니다. 현재 기본 노드인
patroni3를 중지하면 다른 장애 조치가 발생합니다.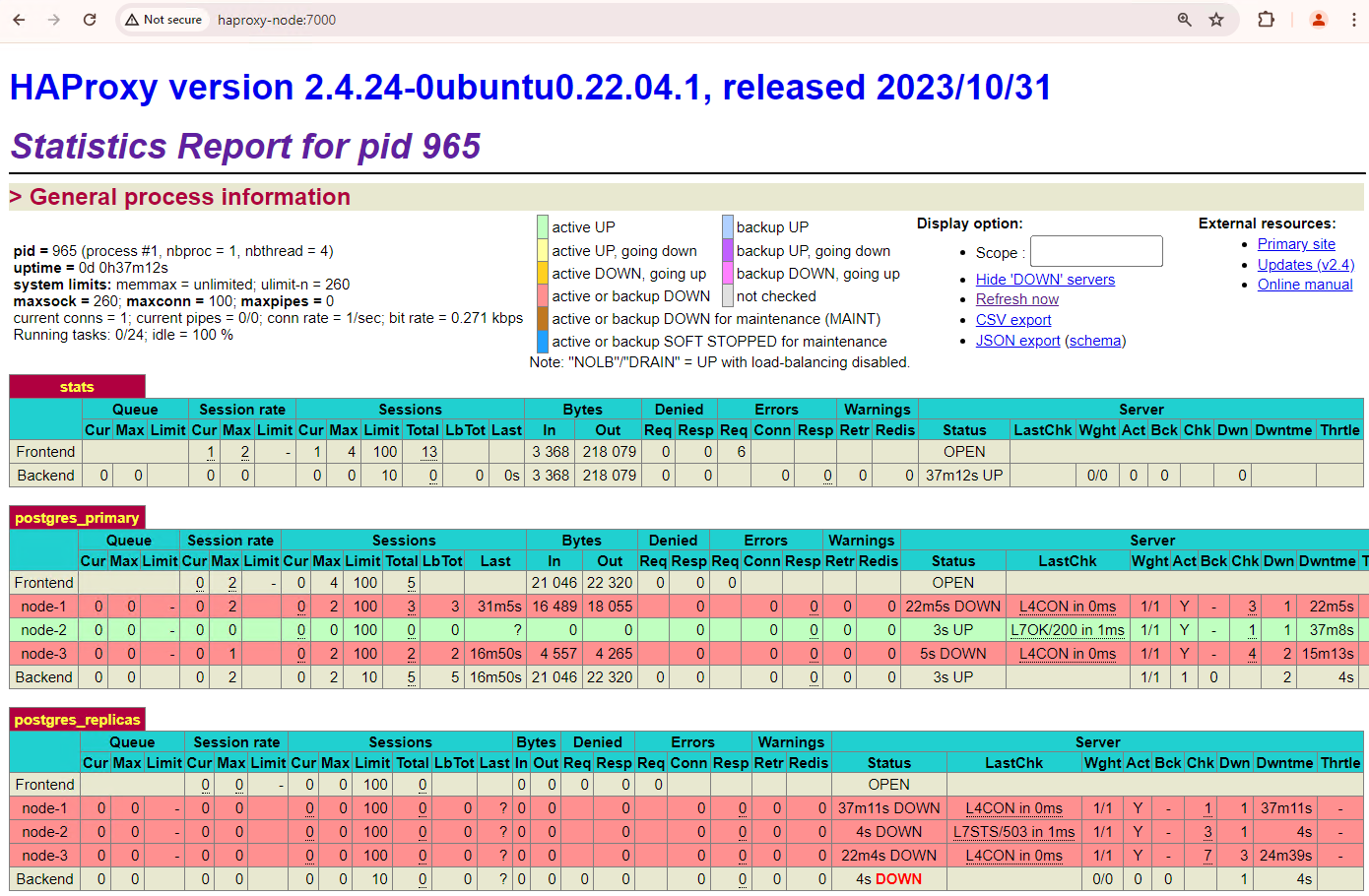
그림 5. 기본 노드
patroni3에서 대기 노드patroni2로의 장애 조치를 보여주는 HAProxy 대시보드
대체 고려사항
대체는 장애 조치가 발생한 후 이전 소스 노드를 복구하는 프로세스입니다. 자동 대체는 일반적으로 고가용성 데이터베이스 클러스터에서 권장되지 않습니다. 불완전한 복구, 스플릿 브레인 시나리오의 위험, 복제 지연과 같은 몇 가지 중요한 문제가 있기 때문입니다.
Patroni 클러스터에서 서비스 중단을 시뮬레이션한 두 노드를 가져오면 이러한 노드가 클러스터에 스탠바이 복제본으로 다시 참여합니다.
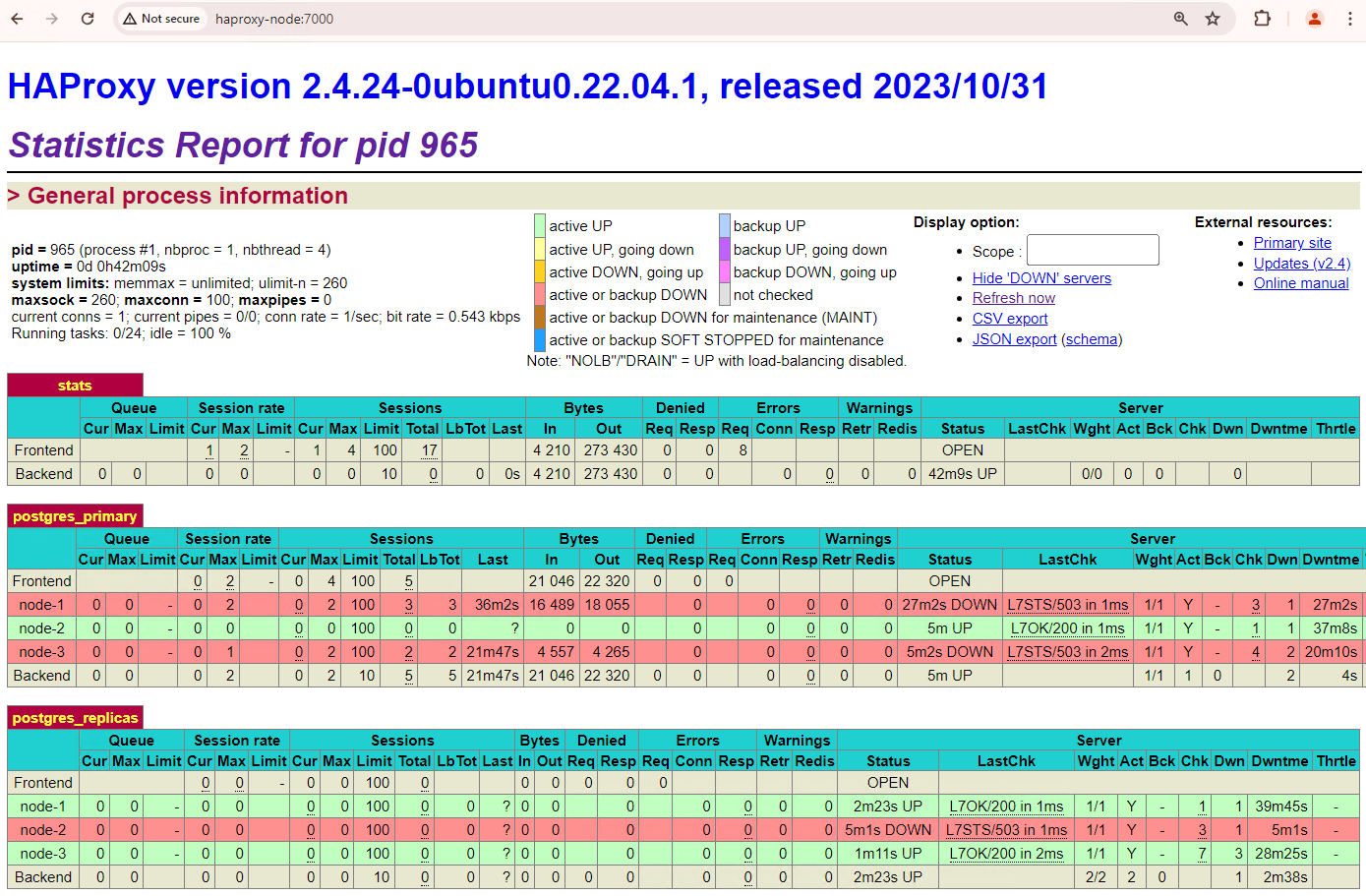
그림 6. patroni1 및 patroni3를 대기 노드로 복원한 것을 보여주는 HAProxy 대시보드
이제 patroni1 및 patroni3가 현재 기본 patroni2에서 복제됩니다.

그림 7. 대체 후 Patroni 노드의 복제 상태를 보여주는 pg_stat_replication 출력
초기 기본 노드로 수동으로 대체하려면 patronictl 명령줄 인터페이스를 사용하면 됩니다. 수동 대체를 선택하면 데이터베이스 시스템의 무결성과 가용성을 유지하면서 더 안정적이고 일관되며 철저하게 검증된 복구 프로세스를 보장할 수 있습니다.