Casos de uso
Essa arquitetura de referência é compatível com os seguintes cenários:
- Você tem bancos de dados que podem tolerar algum tempo de inatividade e perda de dados desde o último backup.
- Você quer proteger seu banco de dados do AlloyDB Omni contra erros do usuário, corrupção ou falhas físicas no nível do banco de dados (em oposição a snapshots de servidor ou imagem de VM).
- Você quer recuperar seu banco de dados no local ou remotamente, possivelmente até um ponto específico no tempo.
Como funciona a arquitetura de referência
A arquitetura de referência de disponibilidade padrão abrange o backup e a recuperação dos bancos de dados do AlloyDB Omni, seja em execução como uma instância independente em um servidor host, como uma máquina virtual (Instalar o AlloyDB Omni) ou em um cluster do Kubernetes (Instalar o AlloyDB Omni no Kubernetes).
Embora a disponibilidade padrão seja uma implementação básica e minimize o hardware ou os serviços adicionais necessários, o objetivo de tempo de recuperação (RTO) aumenta à medida que o banco de dados cresce. Quanto mais dados houver para fazer backup, mais tempo levará para restaurar e recuperar o banco de dados. A perda de dados depende do tipo de backup. Se apenas os arquivos de dados forem armazenados periodicamente, ao restaurar, você vai perder dados desde o último backup.
Reduzir o RPO
Com o recurso de arquivamento contínuo do PostgreSQL, é possível alcançar um objetivo de ponto de recuperação (RPO) baixo e ativar a recuperação pontual por backups. Esse processo envolve arquivar arquivos de registro de gravação antecipada (WAL, na sigla em inglês) e transmitir dados de WAL, possivelmente para um local de armazenamento remoto.
Se os arquivos WAL forem arquivados apenas quando estiverem cheios ou em intervalos específicos, uma perda completa do banco de dados (incluindo os arquivos WAL atuais) restringe a recuperação ao último arquivo WAL arquivado. Isso significa que o objetivo do ponto de recuperação (RPO) precisa considerar a possível perda de dados. Por outro lado, a transferência contínua de dados WAL maximiza a perda de dados zero.
Ao fazer backups contínuos, é possível realizar uma recuperação para um momento específico. Com a recuperação pontual, é possível restaurar um estado anterior a um erro, como exclusão acidental de tabelas ou atualizações em lote incorretas. No entanto, esse método de recuperação afeta o objetivo de ponto de recuperação (RPO) a menos que um banco de dados auxiliar temporário seja usado.
Estratégias de backup
É possível configurar backups do AlloyDB Omni no nível do Postgres para serem armazenados em um armazenamento local ou remoto. Embora o armazenamento local possa ser mais rápido para fazer backup e recuperação, o armazenamento remoto geralmente é mais robusto para lidar com falhas quando um host ou uma VM inteira falha.
Backups em ambientes que não são do Kubernetes
Para implantações que não são do Kubernetes, é possível programar backups usando as seguintes ferramentas do PostgreSQL:
- pgBackRest. Para mais informações, consulte Configurar o pgBackRest para o AlloyDB Omni.
- Barman. Para mais informações, consulte Configurar o Barman para o AlloyDB Omni.
Como alternativa, para bancos de dados pequenos, você pode fazer um backup lógico do banco de dados (usando pg_dump para um único banco de dados ou pg_dumpall para todo o cluster). É possível restaurar usando pg_restore.
Backups no Kubernetes usando o operador do AlloyDB Omni
Para o AlloyDB Omni implantado em um cluster do Kubernetes, é possível configurar backups contínuos usando um plano de backup para cada cluster de banco de dados. Para mais informações, consulte Fazer backup e restaurar no Kubernetes.
É possível armazenar backups do AlloyDB Omni localmente ou remotamente no Cloud Storage, incluindo opções fornecidas por qualquer fornecedor de nuvem. Para mais informações, consulte a Figura 1, que mostra possíveis destinos de backup.
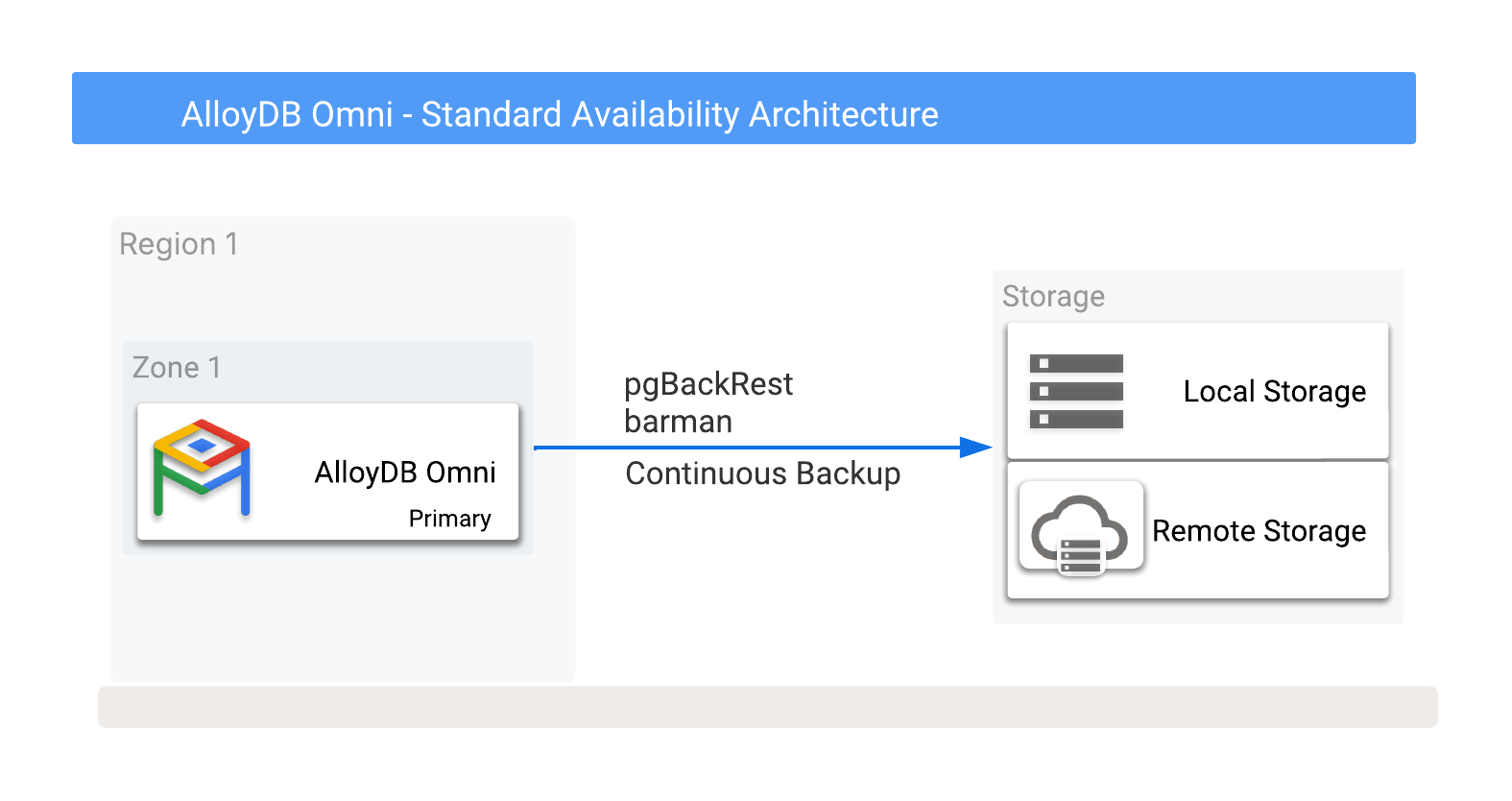
Figura 1. AlloyDB Omni com opções de backup.
Os backups podem ser feitos em opções de armazenamento local ou remoto. Os backups locais tendem a ser mais rápidos porque dependem apenas da capacidade de E/S, enquanto os backups remotos geralmente têm uma latência maior e uma largura de banda de rede menor. No entanto, os backups remotos oferecem proteção ideal, incluindo falhas zonais.
Também é possível dividir backups locais em armazenamento local ou compartilhado. Embora as opções de armazenamento local sejam afetadas pela falta de opções de recuperação de desastres quando um host de banco de dados falha, o armazenamento compartilhado permite que ele seja realocado para outro servidor e usado para recuperação. Isso significa que o armazenamento compartilhado pode oferecer um RTO mais rápido.
Para implantações de armazenamento local e compartilhado, os seguintes tipos de backup podem ser agendados ou feitos manualmente sob demanda:
- Backups completos: backups completos de todos os arquivos do banco de dados necessários para recuperação de dados.
- Backups diferenciais: backups apenas das mudanças nos arquivos desde o último backup completo.
- Backups incrementais: backups apenas das mudanças nos arquivos desde o último backup de qualquer tipo.
Recuperação pontual
Os backups contínuos dos arquivos de registro prévio de gravação (WAL) do PostgreSQL oferecem suporte à recuperação pontual. Se, após um evento de falha, os arquivos WAL estiverem intactos e utilizáveis, você poderá usá-los para fazer a recuperação sem perda de dados.
Para controlar a gravação dos arquivos WAL, configure os seguintes parâmetros:
| Parâmetro | Descrição |
|---|---|
|
Especifica com que frequência o gravador WAL libera o WAL no disco, a menos que a gravação seja ativada antes por uma transação que faz commit de forma assíncrona. O valor padrão é 200 ms. Aumentar esse valor reduz a frequência de gravações, mas pode aumentar a quantidade de dados perdidos se o servidor falhar. |
|
Especifica a quantidade de dados de WAL que podem se acumular antes que o gravador de WAL force uma liberação para o disco. O valor padrão é 1 MB. Se definido como zero, os dados de WAL serão sempre liberados no disco imediatamente. |
|
Especifica se a confirmação retorna uma resposta ao usuário antes que os dados de WAL sejam liberados para o disco. A configuração padrão é
on, que garante a durabilidade da transação. Em
outras palavras, o commit foi gravado no disco antes de retornar um
código de sucesso ao usuário. Se for definido como off, haverá
até três vezes wal_writer_delay antes que a
transação seja gravada em disco. |
Monitoramento do uso de WAL
Use os seguintes métodos para observar o uso do WAL:
| Método de observação | Descrição |
|---|---|
|
Essa visualização padrão tem as colunas wal_write e wal_sync, que armazenam as contagens do número de gravações e sincronizações de WAL. Quando o parâmetro de configuração track_wal_io_timing está ativado, os wal_write_time e wal_sync_time também são armazenados. Snapshots regulares dessa visualização podem ajudar a mostrar a atividade de gravação e sincronização do WAL ao longo do tempo. |
pg_current_wal_lsn() |
Essa função retorna a posição atual do número de sequência de registro (LSN), que, quando associada a um carimbo de data/hora e coletada como snapshots ao longo do tempo, pode fornecer os bytes/segundo de WAL gerados usando a função pg_wal_lsn_diff(lsn1, lsn2).
Essa função é uma métrica útil para entender a taxa de transação e o desempenho dos arquivos WAL. |
Streaming de dados WAL para um local remoto
Ao usar o Barman, os dados de WAL também podem ser configurados para streaming em tempo real em um local remoto e garantir que haja pouca ou nenhuma perda de dados na recuperação. Apesar do streaming em tempo real, há uma pequena chance de perda de transações confirmadas, já que as gravações de streaming no servidor Barman remoto são assíncronas por padrão. No entanto, é possível configurar o streaming de WAL usando o modo síncrono que armazena o WAL e envia uma resposta de status de volta ao banco de dados de origem. Essa abordagem pode diminuir a velocidade das transações se elas precisarem esperar a conclusão dessa gravação antes de continuar.
Programações de backup
Na maioria dos ambientes, os backups são programados semanalmente. Confira a seguir uma programação semanal típica de backups:
- Domingo: backup completo
- Segunda e terça-feira: backup
- Quarta-feira: backup diferencial
- Quinta e sexta-feira: backup incremental
- Sábado: backup diferencial
Usando esse cronograma típico, uma janela de recuperação rotativa de uma semana exige espaço de armazenamento para até três backups completos mais os backups incrementais ou diferenciais necessários. Essa abordagem oferece suporte à recuperação de uma falha que ocorre durante o backup completo no domingo, e a recuperação do banco de dados precisa ser estendida até o domingo anterior ao início do backup.
Para minimizar o RTO com um potencial de RPO mais alto, outros bancos de dados podem operar no modo de recuperação contínua. Isso envolve reproduzir backups e atualizar continuamente o ambiente secundário arquivando e reproduzindo novos arquivos WAL. O RPO real, que reflete a possível perda de dados, depende da frequência de transações, do tamanho do arquivo WAL e do uso do streaming de WAL.
Como fazer a restauração em ambientes que não são do Kubernetes
Para implantações não Kubernetes, a restauração de um banco de dados do AlloyDB Omni envolve interromper o contêiner do Docker e restaurar os dados ou restaurar os dados em um local diferente e iniciar uma nova instância do Docker usando esses dados restaurados. Quando o contêiner for reiniciado, o banco de dados vai estar acessível com os dados restaurados.
Para mais informações sobre opções de recuperação, consulte Restaurar um cluster do AlloyDB Omni usando o pgBackRest e Restaurar um cluster do AlloyDB Omni usando o Barman.
Como fazer a restauração no Kubernetes usando o operador
Para restaurar um banco de dados no Kubernetes, o operador oferece recuperação no mesmo cluster e namespace do Kubernetes, de um backup nomeado ou um clone de um ponto no tempo (PIT, na sigla em inglês). Para clonar um banco de dados em um cluster diferente do Kubernetes, use o pgBackRest. Para mais informações, consulte Fazer backup e restaurar no Kubernetes e Visão geral de como clonar um cluster de banco de dados de um backup do Kubernetes.
Implementação
Ao escolher uma arquitetura de referência de disponibilidade, considere os benefícios, as limitações e as alternativas a seguir.
Vantagens
- Fácil de usar e gerenciar, adequado para bancos de dados não críticos com RTO/RPO flexíveis.
- Requer hardware adicional mínimo
- Os backups são sempre necessários para um plano completo de recuperação de desastres
- É possível fazer a recuperação para qualquer ponto no tempo dentro da janela de recuperação
Limitações
- Requisitos de armazenamento possivelmente maiores do que o próprio banco de dados, dependendo dos requisitos de retenção.
- Pode ser lento para se recuperar e resultar em um RTO mais alto.
- Pode resultar em perda de dados, dependendo da disponibilidade dos dados WAL atuais após uma falha no banco de dados, o que pode afetar negativamente o RPO.
Alternativas
- Considere a arquitetura de disponibilidade avançada ou Premium para melhorar a disponibilidade e as opções de recuperação de desastres.
A seguir
- Visão geral da arquitetura de referência de disponibilidade do AlloyDB Omni.
- Disponibilidade avançada do AlloyDB Omni.
- Disponibilidade do AlloyDB Omni Premium.
- Instale o AlloyDB Omni no Kubernetes.
- Configure o pgBackRest para o AlloyDB Omni.
- Configure o Barman para o AlloyDB Omni.
- Fazer backup e restauração no Kubernetes.
- Restaure um cluster do AlloyDB Omni usando o pgBackRest.
- Restaure um cluster do AlloyDB Omni usando o Barman.
- Fazer backup e restauração no Kubernetes.
- Clonar um cluster de banco de dados na visão geral de backup do Kubernetes.