Encontrar a causa dos erros que surgem durante o treinamento do seu modelo ou receber predições na nuvem pode ser difícil. Nesta página, você verá como encontrar e depurar problemas do AI Platform Training. Caso você detecte problemas com o framework de machine learning que está usando, leia a documentação pertinente.
Ferramenta de linha de comando
ERROR: (gcloud) Invalid choice: 'ai-platform'.Esse erro significa que é preciso atualizar a gcloud. Para isso, execute o seguinte comando:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.Esse erro significa que é preciso atualizar a gcloud. Para isso, execute o seguinte comando:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.Esse erro significa que é preciso atualizar a gcloud. Para isso, execute o seguinte comando:
gcloud components updateERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\\x03'. (Error code: 0)Esse erro significa que uma biblioteca incorreta foi usada para exportar o modelo. Para corrigir isso, exporte novamente o modelo usando a biblioteca correta. Por exemplo, exporte modelos no formato
model.pklcom a bibliotecapicklee modelos no formatomodel.joblibcom a bibliotecajoblib.ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.Esse erro significa que você especificou
jsoncomo valor da sinalização--data-formatao enviar um job de previsão em lote. Para usar o formato de dadosJSON, você precisa fornecertextcomo o valor da sinalização--data-format.
Versões do Python
ERROR: Bad model detected with error: "Failed to load model: Could not load the
model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
sure the model was exported using python 2. Otherwise, please specify the
correct 'python_version' parameter when deploying the model. Currently,
'python_version' accepts 2.7 and 3.5. (Error code: 0)"
Esse erro significa que um arquivo de modelo exportado com o Python 3 foi implantado em um recurso de versão do modelo do AI Platform Training com uma configuração do Python 2.7.
Para solucioná-lo:
- crie um novo recurso de versão de modelo e defina 'python_version' como 3.5;
- Implante o mesmo arquivo no novo recurso de versão do modelo.
Comando virtualenv não encontrado
Se você recebeu esse erro ao tentar ativar virtualenv, uma solução possível é adicionar o diretório contendo virtualenv à sua variável de ambiente $PATH. Quando essas variáveis são modificadas, você consegue usar os comandos do virtualenv sem digitar o caminho completo do arquivo.
Primeiro, instale virtualenv executando o seguinte comando:
pip install --user --upgrade virtualenv
O instalador solicita que você modifique a variável de ambiente $PATH e fornece o caminho para o script virtualenv. No macOS, isso é semelhante a /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Abra o arquivo em que o shell carrega variáveis de ambiente. Normalmente, é ~/.bashrc ou ~/.bash_profile no macOS.
Adicione a seguinte linha, substituindo [VALUES-IN-BRACKETS] pelos valores apropriados:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Por fim, execute o seguinte comando para carregar .bashrc (ou .bash_profile):
source ~/.bashrc
Como usar registros de jobs
Um bom local para iniciar a solução de problemas é nos registros de jobs capturados pelo Cloud Logging.
Como gerar registros para os diferentes tipos de operação
A experiência de geração de registros varia de acordo com o tipo de operação, conforme mostrado nas seções a seguir.
Registros de treinamento
Todos os jobs de treinamento são registrados. Os registros incluem eventos do serviço e do aplicativo de treinamento. Coloque eventos de geração de registros no seu aplicativo com as bibliotecas Python padrão (por exemplo, logging). O AI Platform Training captura todas as mensagens de registro do aplicativo. Todas as mensagens enviadas para o stderr são automaticamente capturadas na entrada do job no Cloud Logging.
Registros de previsão em lote
Todos os jobs de predição em lote são registrados.
Registros de predição on-line
As solicitações de previsão on-line não geram registros por padrão. É possível ativar o Cloud Logging ao criar o recurso do modelo:
gcloud
Inclua a sinalização --enable-logging ao executar
gcloud ai-platform models create.
Python
Defina onlinePredictionLogging como True
no recurso Modelque
você usa em sua
chamada para projects.models.create.
Como encontrar registros
Os registros dos jobs contêm todos os eventos para a operação, incluindo eventos de todos os processos no cluster durante o uso do treinamento distribuído. Caso esteja executando um job de treinamento distribuído, os registros de nível de jobs serão relatados para o processo do worker mestre. Normalmente, a primeira etapa para corrigir erros é examinar os registros desse processo, filtrando eventos registrados para outros processos em seu cluster. Os exemplos desta seção mostram essa filtragem.
É possível filtrar os registros na linha de comando ou na seção Cloud Logging do console do Google Cloud. Nos dois casos, use estes valores de metadados no seu filtro conforme necessário:
| Item de metadados | Filtro para mostrar quando o item for... |
|---|---|
| resource.type | igual a "cloud_ml_job"; |
| resource.labels.job_id | igual ao nome do job; |
| resource.labels.task_name | igual a "master-replica-0" para ler apenas as entradas de registros para o worker mestre; |
| severity | maior que ou igual a ERROR para ler apenas as entradas de registros correspondentes a condições de erro. |
Linha de comando
Use gcloud beta logging read para gerar uma consulta que atenda as suas necessidades. Veja alguns exemplos:
Cada exemplo depende destas variáveis de ambiente:
PROJECT="my-project-name"
JOB="my_job_name"
Se preferir, insira no lugar o literal de string.
Para imprimir os registros do job na tela:
gcloud ai-platform jobs stream-logs $JOB
Veja todas as opções para gcloud ai-platform jobs stream-logs.
Imprimir o registro do worker mestre na tela
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
Para imprimir apenas erros registrados do worker mestre na tela:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
Os exemplos anteriores representam os casos mais comuns de filtragem para os registros do job de treinamento do AI Platform Training. O Cloud Logging fornece muitas opções eficientes de filtragem que podem ser usadas para refinar sua pesquisa. Essas opções são descritas detalhadamente na documentação de filtragem avançada.
Console
Abra a página Jobs do AI Platform Training no Console do Google Cloud.
Selecione o job com falha na lista da página Jobs para ver detalhes.

- Clique em Ver registros para abrir o Cloud Logging.
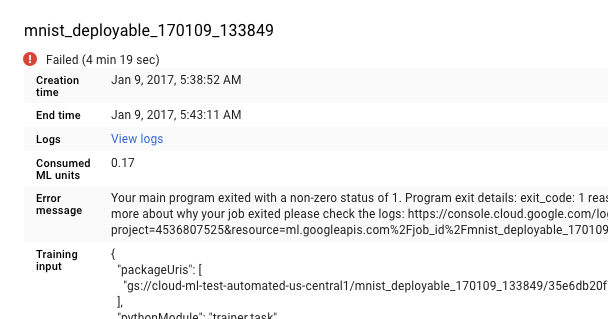
É possível ir diretamente ao Cloud Logging, mas é necessário adicionar uma etapa para encontrar seu job:
- Expanda o seletor de recursos.
- Expanda o job do Cloud ML Engine na lista de recursos.
- Encontre o nome do job na lista job_id. Insira as primeiras letras do nome dele na caixa de pesquisa para restringir os jobs exibidos.
- Expanda a entrada do job e selecione
master-replica-0na lista de tarefas.

Como conseguir informações dos registros
Depois de encontrar o registro correto para o job e filtrá-lo para master-replica-0, é possível examinar os eventos registrados para encontrar a origem do problema. Use o procedimento de depuração padrão do Python e lembre-se:
- Os eventos têm diversos níveis de gravidade. Faça a filtragem para ver apenas eventos de um determinado nível, por exemplo, erros ou erros e avisos.
- Um problema que faz com que seu treinador saia com uma condição de erro irrecuperável (código de retorno > 0) é registrado como uma exceção precedida pelo stack trace:
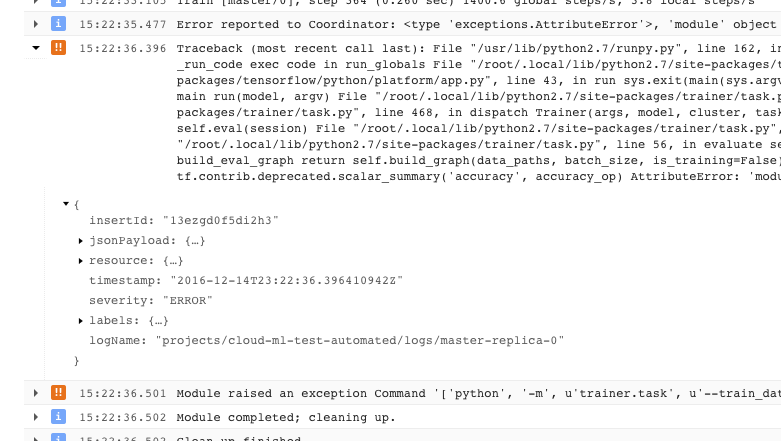
- Veja mais informações expandindo os objetos na mensagem JSON registrada (denotada por uma seta para a direita e com conteúdo listado como {...}). Por exemplo, é possível expandir jsonPayload para ver o stack trace em um formato mais legível do que é fornecido na descrição do erro principal:
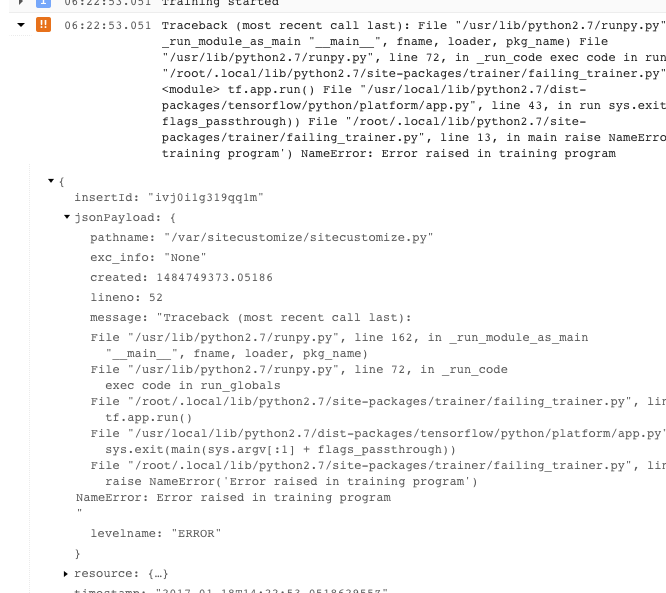
- Alguns erros mostram instâncias de erros passíveis de repetição. Em geral, eles não incluem rastreamento de pilha e são mais difíceis de diagnosticar.
Como aproveitar ao máximo a geração de registros
O serviço do AI Platform Training registra automaticamente estes eventos:
- Informações de status internas para o serviço.
- Mensagens que o aplicativo do treinador envia para
stderr. - Texto de saída que o aplicativo do treinador envia para o
stdout.
Simplifique a solução de erros no aplicativo do treinador seguindo as práticas recomendadas de programação:
- Envie mensagens significativas para stderr (com logging, por exemplo).
- Crie a exceção mais lógica e descritiva quando algo der errado.
- Adicione strings descritivas aos objetos de exceção.
A documentação do Python fornece mais informações sobre exceções.
Como solucionar problemas no treinamento
Nesta seção, você aprende os conceitos e condições de erro aplicáveis aos jobs de treinamento.
Noções básicas sobre os códigos de retorno do aplicativo de treinamento
O job de treinamento na nuvem é controlado pelo programa principal em execução no processo do worker mestre do cluster de treinamento:
- O treinamento em um único processo (não distribuído) tem apenas um único worker, que é o mestre.
- O programa principal é a função
__main__do seu aplicativo de treinamento do TensorFlow. - O serviço de treinamento do AI Platform Training executa o aplicativo treinador até ele ser concluído ou encontrar um erro irrecuperável. Isso significa que ele reiniciará os processos caso ocorram erros passíveis de repetição.
O serviço de treinamento gerencia seus processos. Ele trata de uma saída de programa de acordo com o código de retorno do processo de worker mestre:
| Código de retorno | Significado | Resposta do AI Platform Training |
|---|---|---|
| 0 | Conclusão bem-sucedida | Encerra e libera recursos do job. |
| 1 - 128 | Erro irrecuperável | Termina o job e registra o erro. |
Você não precisa fazer nada em relação ao código de retorno da função __main__. O Python retorna automaticamente zero quando a conclusão
é bem-sucedida e retorna um código positivo quando encontra uma exceção não processada. Se você
estiver acostumado a definir códigos de retorno específicos para os objetos
de exceção (uma prática válida, mas incomum), isso não interferirá
no job do AI Platform Training, desde que você siga o padrão na tabela
acima. Mesmo assim, o código do cliente em geral não indica erros passíveis de
repetição diretamente: eles vêm do ambiente operacional.
Como tratar condições de erro específicas
Nesta seção, você receberá orientações sobre as condições de erros conhecidas que afetam alguns usuários.
Recurso esgotado
A demanda de GPUs e recursos de computação na região us-central1 é alta.
Talvez você receba a mensagem de erro a seguir nos registros do job: Resources are
insufficient in region: <region>. Please try a different region..
Para resolver isso, use uma região diferente ou tente novamente mais tarde.
Treinador executado continuamente sem nenhum progresso
Algumas situações fazem com que o aplicativo do treinador seja executado continuamente sem nenhum progresso na tarefa de treinamento. Isso é causado por uma chamada de bloqueio que aguarda um recurso que nunca fica disponível. Para reduzir esse problema, configure um intervalo de tempo limite no treinador.
Configurar um intervalo de tempo limite para o treinador
Configure um tempo limite, em milissegundos, ao criar uma sessão ou executar uma etapa do seu gráfico:
Defina o intervalo de tempo limite pretendido com o parâmetro config ao criar o objeto Session:
sess = tf.Session(config=tf.ConfigProto(operation_timeout_in_ms=500))Defina o intervalo de tempo limite desejado para uma única chamada a Session.run, usando o parâmetro options:
v = session.run(fetches, options=tf.RunOptions(timeout_in_ms=500))
Consulte a documentação do TensorFlow sobre Session (em inglês) para mais informações.
Saída do programa com um código de -9
Se você receber consistentemente o código de saída -9, significa que o aplicativo do treinador pode estar usando mais memória do que a alocada para o processo. Para corrigir esse erro, reduza o uso de memória, use tipos de máquina com mais memória ou faça as duas coisas.
- No gráfico e no aplicativo do treinador, verifique se há operações que usem mais memória do que o previsto. O uso da memória é afetado pela complexidade dos dados e das operações no gráfico de computação.
- O aumento da memória alocada para o job exige cuidados:
- Quando usar um nível de escalonamento definido, não aumente a alocação de memória por máquina sem adicionar mais máquinas ao conjunto. Será necessário passar para o nível PERSONALIZADO e definir os tipos de máquinas no próprio cluster.
- A configuração precisa de cada tipo de máquina definido está sujeita a alterações, mas é possível fazer algumas comparações aproximadas. Você encontrará uma tabela comparativa de tipos de máquinas na página de conceitos do treinamento.
- Para testar os tipos de máquinas para a alocação de memória apropriada, prefira usar uma única máquina ou um cluster de tamanho menor para reduzir as cobranças resultantes.
Saída do programa com um código de -15
Geralmente, um código de saída de -15 indica manutenção pelo sistema. É um erro passível de repetição e, portanto, o processo é reiniciado automaticamente.
Job em fila por muito tempo
Quando o estado de
um job de treinamento permanece como QUEUED por um período prolongado,
isso significa que você talvez tenha excedido a cota de solicitações de job.
O AI Platform Training inicia jobs de treinamento com base no horário de criação deles, usando uma regra "primeiro a entrar, primeiro a sair". Se seu job estiver na fila, em geral isso significará que toda a cota do projeto foi consumida por outros jobs enviados antes do seu ou que o primeiro job da fila solicitou mais unidades/GPUs do ML do que a cota disponível.
A razão pela qual um job foi colocado em fila consta nos registros de treinamento. Pesquise no registro mensagens semelhantes a esta:
This job is number 2 in the queue and requires
4.000000 ML units and 0 GPUs. The project is using 4.000000 ML units out of 4
allowed and 0 GPUs out of 10 allowed.A mensagem explica a posição atual do job na fila, o uso atual e a cota do projeto.
O motivo será registrado apenas para os primeiros 10 jobs em fila, ordenados por horário de criação.
Para usar regularmente um número de solicitações maior, peça um aumento de cota. Entre em contato com o suporte caso você tenha um pacote de suporte premium. Caso contrário, envie sua solicitação por e-mail para o feedback do AI Platform Training.
Cota excedida
Quando receber um erro com uma mensagem "Falha na cota para o project_number...", significa que você excedeu uma de suas cotas de recursos. Monitore o consumo de recursos e solicite um aumento na página de cotas do AI Platform Training no Gerenciador de APIs do console.
Caminho de salvamento inválido
Se o job sai com uma mensagem de erro que inclui "Restauração chamada com o caminho de salvamento inválido gs://...", isso significa que você está usando um bucket do Google Cloud Storage configurado incorretamente.
Abra a página Navegador do Google Cloud Storage no console do Google Cloud.
Verifique a Classe de armazenamento padrão para o bucket usado:

- Ela precisa ser Regional. Se for, o erro não está na classe de armazenamento. Tente executar o job novamente.
- Caso seja Multirregional, mude para Regional ou transfira os materiais de treinamento para um bucket diferente. Para a primeira opção, encontre as instruções para alterar a classe de armazenamento de um bucket na documentação do Cloud Storage.
O treinador sai com AbortedError
Esse erro poderá ocorrer se você executar um instrutor que usa a classe Supervisor do TensorFlow para gerenciar tarefas distribuídas. O TensorFlow às vezes lança exceções AbortedError em situações em que não é indicado interromper o job inteiro. Pegue essa exceção em seu treinador e responda de forma adequada. O Supervisor do TensorFlow não é compatível com treinadores executados com o AI Platform Training.
Solução de problemas de previsões
Veja nesta seção alguns problemas comuns encontrados ao receber predições.
Como lidar com condições específicas para predição on-line
Nesta seção, você encontra orientações sobre algumas condições de erro de predição on-line conhecidas por afetarem alguns usuários.
Predições com longo período de conclusão (de 30 a 180 segundos)
A causa mais comum de uma predição on-line lenta é o escalonamento de nós de processamento a partir do zero. Caso o modelo tenha solicitações de predição regulares feitas em relação a ele, o sistema mantém um ou mais nós prontos para veicular as predições. Quando o modelo não veicula nenhuma predição durante um longo período de tempo, o serviço "diminui" para zero nós prontos. A próxima solicitação de predição depois dessa redução de escala levará muito mais tempo para retornar do que o habitual, porque o serviço tem que providenciar nós para lidar com isso.
Códigos de status HTTP
Quando ocorre um erro com uma solicitação de previsão on-line, geralmente você recebe um código de status HTTP do serviço. Estes são alguns dos códigos comumente encontrados e os respectivos significados no contexto da predição on-line:
- 429 - Memória insuficiente
O nó de processamento ficou sem memória durante a execução do modelo. Não há como aumentar a memória alocada para os nós de predição nesse momento. Tente estas alternativas para a execução do modelo:
- Reduza o tamanho do modelo:
- usando variáveis menos precisas;
- quantificando os dados contínuos;
- reduzindo o tamanho de outros recursos de entrada (usando tamanhos menores de vocabulário, por exemplo);
- enviando a solicitação novamente com um lote menor de instâncias.
- Reduza o tamanho do modelo:
- 429 - Muitas solicitações pendentes
O modelo está recebendo mais solicitações do que consegue processar. Se você estiver usando o escalonamento automático, as solicitações serão recebidas com mais rapidez do que o suportado pelo sistema.
Com o escalonamento automático, tente reenviar solicitações com retirada exponencial. Com isso, o sistema ganha tempo para se ajustar.
- 429 - Cota
Seu projeto do Google Cloud Platform é limitado a 10.000 solicitações a cada 100 segundos, ou seja, cerca de 100 por segundo. Se você receber esse erro em picos temporários, tente novamente com a retirada exponencial para processar todas as solicitações a tempo. Se você receber esse código constantemente, solicite um aumento de cota. Consulte a página de cotas para saber mais.
- 503 - Nossos sistemas detectaram tráfego incomum a partir de sua rede de computadores
A incidência de solicitações recebidas pelo modelo a partir de um único IP é tão alta que o sistema suspeita de um ataque de negação de serviço. Pare de enviar solicitações por um minuto e retome o envio com uma frequência mais baixa.
- 500 - Não foi possível carregar o modelo
O sistema teve problemas para carregar o modelo. Siga estas etapas:
- Veja se o seu treinador está exportando o modelo certo.
- Tente fazer uma previsão de teste com o comando
gcloud ai-platform local predict. - Exporte o modelo e tente novamente.
Erros de formatação para solicitações de predição
Todas estas mensagens têm a ver com sua entrada de predição.
- "Empty or malformed/invalid JSON in request body"
- O serviço não conseguiu analisar a JSON na sua solicitação ou a solicitação está vazia. Verifique se a mensagem contém erros ou omissões que invalidem a JSON.
- "Missing 'instances' field in request body"
- O corpo da solicitação não segue o formato correto. Ele precisa ser um objeto JSON com uma chave única chamada
"instances"que contém uma lista com todas as suas instâncias de entrada. - Erro de codificação JSON ao criar uma solicitação
Sua solicitação inclui dados codificados em base64, mas não no formato JSON apropriado. Cada string codificada em base64 precisa ser representada por um objeto com uma chave única chamada
"b64". Exemplo:{"b64": "an_encoded_string"}Outro erro de base64 ocorre quando você tem dados binários não codificados em base64. Codifique os dados e os formate da seguinte maneira:
{"b64": base64.b64encode(binary_data)}Veja mais informações sobre formatação e codificação de dados binários.
A predição na nuvem demora mais do que no computador
A predição on-line é projetada para ser um serviço escalonável que atende rapidamente uma alta taxa de solicitações. O serviço é otimizado para o desempenho agregado em todas as solicitações de disponibilização. A ênfase na escalonabilidade leva a características de desempenho diferentes em comparação com a geração de um pequeno número de predições na sua máquina local.
A seguir
- Receba suporte.
- Saiba mais sobre o modelo de erro das APIs do Google, principalmente os códigos de erros canônicos definidos em
google.rpc.Codee os detalhes de erros padrão definidos em google/rpc/error_details.proto (links em inglês). - Saiba como monitorar os jobs de treinamento.
- Consulte a página de solução de problemas e perguntas frequentes do Cloud TPU se precisar de ajuda para diagnosticar e resolver problemas na execução do AI Platform Training com o Cloud TPU.