AI Platform Pipelines permet d'orchestrer les workflows de machine learning (ML) en tant que pipelines réutilisables et reproductibles. AI Platform Pipelines vous évite d'avoir à configurer Kubeflow Pipelines avec TensorFlow Extended sur Google Kubernetes Engine.
Ce guide décrit plusieurs options de déploiement d'AI Platform Pipelines sur GKE. Vous pouvez déployer Kubeflow Pipelines sur un cluster GKE existant ou créer un cluster GKE. Si vous souhaitez réutiliser un cluster GKE existant, assurez-vous que votre cluster remplit les conditions suivantes :
- Votre cluster doit comporter au moins trois nœuds. Chaque nœud doit disposer d'au moins deux processeurs et de 4 Go de mémoire disponible.
- Le niveau d'accès du cluster doit accorder un accès complet à toutes les API Cloud, ou votre cluster doit utiliser un compte de service personnalisé.
- Kubeflow Pipelines ne doit pas déjà être installé sur le cluster.
Sélectionnez l'option de déploiement qui convient le mieux à votre situation :
- Utilisez AI Platform Pipelines pour créer un cluster GKE avec un accès complet à Google Cloud et déployer Kubeflow Pipelines sur le cluster. Cette option facilite le déploiement et l'utilisation d'AI Platform Pipelines.
- Créez un cluster GKE avec un accès précis àGoogle Cloud et déployez Kubeflow Pipelines sur ce cluster. Cette option vous permet de spécifier les ressources et les API Google Cloudauxquelles les charges de travail de votre cluster ont accès.
- Déployez AI Platform Pipelines sur un cluster GKE existant. Cette option explique comment déployer AI Platform Pipelines sur un cluster GKE existant.
Avant de commencer
Avant de suivre ce guide, vérifiez que votre Google Cloud projet est correctement configuré et que vous disposez des autorisations nécessaires pour déployer AI Platform Pipelines.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Suivez les instructions ci-dessous pour vérifier si vous disposez des rôles requis pour déployer AI Platform Pipelines.
-
Ouvrez une session Cloud Shell.
Cloud Shell s'ouvre dans un cadre au bas de Google Cloud Console.
-
Vous devez disposer des rôles Lecteur (
roles/viewer) et Administrateur de Kubernetes Engine (roles/container.admin) sur le projet, ou d'autres rôles qui disposent des mêmes autorisations comme le rôle Propriétaire (roles/owner) sur le projet, afin de déployer AI Platform Pipelines. Exécutez la commande suivante dans Cloud Shell pour répertorier les comptes principaux qui disposent des rôles Lecteur et Administrateur de Kubernetes Engine.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer"
Remplacez PROJECT_ID par l'ID de votre projet Google Cloud.
Utilisez le résultat de cette commande pour vérifier que votre compte possède les rôles Lecteur et Administrateur de Kubernetes Engine.
-
Si vous souhaitez accorder à votre cluster un accès précis, vous devez également disposer du rôle Administrateur de compte de service" (
roles/iam.serviceAccountAdmin) sur le projet, ou d'autres rôles qui disposent des mêmes autorisations comme le rôle Éditeur (roles/editor) ou Propriétaire (roles/owner) sur le projet. Exécutez la commande suivante dans Cloud Shell pour répertorier les comptes principaux qui ont le rôle Administrateur de compte de service.gcloud projects get-iam-policy PROJECT_ID \ --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" \ --filter="bindings.role:roles/iam.serviceAccountAdmin"
Remplacez PROJECT_ID par l'ID de votre projet Google Cloud.
Utilisez le résultat de cette commande pour vérifier que votre compte possède le rôle Administrateur de compte de service.
-
Si vous ne disposez pas des rôles requis, contactez votre administrateur de projet Google Cloud pour obtenir de l'aide.
Découvrez comment attribuer des rôles Identity and Access Management (IAM).
-
Déployer AI Platform Pipelines avec un accès complet à Google Cloud
AI Platform Pipelines facilite la configuration et l'utilisation de Kubeflow Pipelines en créant pour vous un cluster GKE et en déployant Kubeflow Pipelines sur le cluster. Lorsque AI Platform Pipelines crée pour vous un cluster GKE, ce cluster utilise le compte de service Compute Engine par défaut. Pour fournir à votre cluster un accès complet aux ressources et aux API Google Cloud que vous avez activées dans votre projet, vous pouvez lui accorder le niveau d'accès https://www.googleapis.com/auth/cloud-platform. Accorder l'accès de cette manière permet aux pipelines de ML exécutés sur votre cluster d'accéder aux API Google Cloud, telles que AI Platform Training et AI Platform Prediction. Bien que ce processus facilite la configuration d'AI Platform Pipelines, il se peut que vos développeurs disposent d'un accès excessif aux ressources et aux API Google Cloud .
Suivez les instructions ci-dessous pour déployer AI Platform Pipelines avec un accès complet aux ressources et aux API Google Cloud .
Ouvrez AI Platform Pipelines dans Google Cloud Console.
Dans la barre d'outils AI Platform Pipelines, cliquez sur Nouvelle instance. Kubeflow Pipelines s'ouvre dans Google Cloud Marketplace.
Cliquez sur Configurer. Le formulaire Deploy Kubeflow Pipelines (Déployer Kubeflow Pipelines) s'ouvre.
Si le lien Create a new cluster (Créer un cluster) s'affiche, cliquez dessus. Sinon, passez directement à l'étape suivante.

Dans le champ Cluster zone (Zone du cluster), sélectionnez la zone dans laquelle se trouve votre cluster. Pour déterminer la zone à utiliser, consultez les bonnes pratiques pour la sélection des régions.
Cochez la case Allow access to the following Cloud APIs (Autoriser l'accès aux API Cloud suivantes) pour autoriser les applications exécutées sur votre cluster GKE à accéder aux ressources Google Cloud . En cochant cette case, vous accorder au cluster le niveau d'accès
https://www.googleapis.com/auth/cloud-platform. Ce champ d'application offre un accès complet aux ressources Google Cloud que vous avez activées dans votre projet. Accorder à votre cluster l'accès aux ressources Google Cloud de cette manière vous évite de créer et gérer un compte de service ou de créer un secret Kubernetes.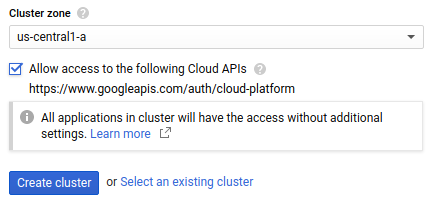
Cliquez sur Create cluster (Créer un cluster). Cette opération peut prendre plusieurs minutes.
Les espaces de noms permettent de gérer les ressources des clusters GKE volumineux. Si vous ne prévoyez pas d'utiliser les espaces de noms de votre cluster, sélectionnez Par défaut dans la liste déroulante Espace de noms.
Si vous envisagez d'utiliser des espaces de noms dans votre cluster GKE, créez-en un à l'aide de la liste déroulante Espace de noms. Pour créer un espace de noms, procédez comme suit :
- Cliquez sur Créer un espace de noms dans la liste déroulante Espace de noms. Le champ Nom du nouvel espace de noms s'affiche.
- Saisissez le nom de l'espace de noms dans le champ Nom du nouvel espace de noms.
Pour en savoir plus sur les espaces de noms, consultez un article de blog (en anglais) sur l'organisation de Kubernetes avec des espaces de noms.
Dans la zone Nom de l'instance d'application, saisissez le nom de votre instance Kubeflow Pipelines.
Le stockage géré vous permet de stocker les métadonnées et les artefacts de votre pipeline de ML à l'aide de Cloud SQL et de Cloud Storage, au lieu de les stocker sur des disques persistants Compute Engine. L'utilisation de services gérés pour stocker les artefacts et les métadonnées de votre pipeline facilite la sauvegarde et la restauration des données de votre cluster. Pour déployer Kubeflow Pipelines avec le stockage géré, sélectionnez Utiliser le stockage géré et fournissez les informations suivantes :
Bucket de stockage Cloud Storage : avec le stockage géré, Kubeflow Pipelines stocke les artefacts de pipeline dans un bucket Cloud Storage. Indiquez le nom du bucket dans lequel vous souhaitez que Kubeflow Pipelines stocke les artefacts. Si le bucket spécifié n'existe pas, le déployeur Kubeflow Pipelines crée automatiquement un bucket pour vous dans la région
us-central1.Nom de connexion de l'instance Cloud SQL : avec le stockage géré, Kubeflow Pipelines stocke les métadonnées de pipeline dans une base de données MySQL sur Cloud SQL. Indiquez le nom de la connexion de votre instance MySQL Cloud SQL.
Apprenez-en plus sur la configuration d'une instance Cloud SQL.
Nom d'utilisateur de la base de données : indiquez le nom d'utilisateur de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Actuellement, votre utilisateur de base de données doit disposer des privilèges MySQL
ALLpour déployer Kubeflow Pipelines avec le stockage géré. Si vous laissez ce champ vide, cette valeur est définie par défaut sur root.Mot de passe de la base de données : indiquez le mot de passe de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Si vous laissez ce champ vide, Kubeflow Pipelines se connecte à votre base de données sans fournir de mot de passe, ce qui échoue si un mot de passe est requis pour le nom d'utilisateur spécifié.
Préfixe du nom de base de données : indiquez le préfixe du nom de base de données. La valeur du préfixe doit commencer par une lettre et ne contenir que des lettres minuscules, des chiffres et des traits de soulignement.
Au cours du processus de déploiement, Kubeflow Pipelines crée deux bases de données, "DATABASE_NAME_PREFIX_pipeline" et "DATABASE_NAME_PREFIX_metadata". Si des bases de données portant ces noms existent dans votre instance MySQL, Kubeflow Pipelines réutilise les bases de données existantes. Si cette valeur n'est pas spécifiée, le nom de l'instance d'application est utilisé comme préfixe du nom de base de données.
Cliquez sur Déployer. Cette opération peut prendre plusieurs minutes.
Pour accéder au tableau de bord des pipelines, ouvrez AI Platform Pipelines dans la console Google Cloud.
Accéder à AI Platform Pipelines
Cliquez ensuite sur Ouvrir le tableau de bord des pipelines pour votre instance AI Platform Pipelines.
Déployer AI Platform Pipelines avec un accès précis à Google Cloud
Les pipelines de ML accèdent aux Google Cloud ressources à l'aide du compte de service et du champ d'application d'accès du pool de nœuds du cluster GKE. Actuellement, pour limiter l'accès de votre cluster à des ressources Google Cloud spécifiques, vous devez déployer AI Platform Pipelines sur un cluster GKE utilisant un compte de service géré par l'utilisateur.
Suivez les instructions des sections suivantes pour créer et configurer un compte de service, créer un cluster GKE à l'aide de votre compte de service et déployer Kubeflow Pipelines sur votre cluster GKE.
Créer un compte de service pour votre cluster GKE
Suivez les instructions ci-dessous pour configurer un compte de service pour votre cluster GKE.
Ouvrez une session Cloud Shell.
Cloud Shell s'ouvre dans un cadre au bas de Google Cloud Console.
Exécutez les commandes suivantes dans Cloud Shell pour créer votre compte de service et lui accorder un accès suffisant pour exécuter AI Platform Pipelines. Découvrez les rôles requis pour exécuter AI Platform Pipelines avec un compte de service géré par l'utilisateur.
export PROJECT=PROJECT_IDexport SERVICE_ACCOUNT=SERVICE_ACCOUNT_NAMEgcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name=$SERVICE_ACCOUNT \ --project=$PROJECTgcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/logging.logWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.metricWritergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/monitoring.viewergcloud projects add-iam-policy-binding $PROJECT \ --member="serviceAccount:$SERVICE_ACCOUNT@$PROJECT.iam.gserviceaccount.com" \ --role=roles/storage.objectViewerRemplacez les éléments suivants :
- SERVICE_ACCOUNT_NAME : nom du compte de service à créer.
- PROJECT_ID : projet Google Cloud dans lequel le compte de service est créé.
Accordez à votre compte de service l'accès à toutes les Google Cloud ressources ou API requises par vos pipelines de ML. Apprenez-en plus sur les rôles Identity and Access Management (IAM) et découvrez comment gérer les comptes de service.
Attribuez à votre compte utilisateur le rôle Utilisateur du compte de service (
iam.serviceAccountUser).gcloud iam service-accounts add-iam-policy-binding \ "SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com" \ --member=user:USERNAME \ --role=roles/iam.serviceAccountUser
Remplacez les éléments suivants :
- SERVICE_ACCOUNT_NAME : nom de votre compte de service.
- PROJECT_ID : votre projet Google Cloud.
- USERNAME: votre nom d'utilisateur sur Google Cloud.
Configurer votre cluster GKE
Suivez les instructions ci-dessous pour configurer votre cluster GKE.
Ouvrez Google Kubernetes Engine dans la console Google Cloud.
Cliquez sur le bouton Créer un cluster. Le formulaire Paramètres de base du cluster s'ouvre.
Saisissez le nom de votre cluster.
Pour le type d'emplacement, sélectionnez Zonal, puis choisissez la zone souhaitée pour votre cluster. Pour déterminer la zone à utiliser, consultez les bonnes pratiques pour la sélection des régions.
Dans le volet de navigation, cliquez sur default-pool sous Pools de nœuds. Le formulaire Détails du pool de nœuds s'affiche.
Saisissez le nombre de nœuds à créer dans le cluster. Votre cluster doit comporter au moins trois nœuds pour pouvoir déployer AI Platform Pipelines. Vous devez disposer d'un quota de ressources disponible pour les nœuds et les ressources associées (telles que les routes de pare-feu).
Dans le volet de navigation, cliquez sur Nœuds sous Pools de nœuds. Le formulaire Nœuds s'ouvre.
Sélectionnez la configuration de la machine à utiliser par défaut pour les instances. Vous devez sélectionner un type de machine disposant d'au moins deux processeurs et de 4 Go de mémoire, tel que
n1-standard-2, pour pouvoir déployer AI Platform Pipelines. Chaque type de machine est facturé différemment. Pour plus d'informations sur les tarifs applicables aux différents types de machines, consultez la grille tarifaire par type de machine.Dans le volet de navigation, sous Pools de nœuds, cliquez sur Sécurité. Le formulaire Sécurité des nœuds s'affiche.
Dans la liste déroulante Compte de service, sélectionnez le compte de service que vous avez créé précédemment dans ce guide.
Sinon, configurez votre cluster GKE comme vous le souhaitez. Découvrez comment créer un cluster GKE.
Cliquez sur Créer.
Installer Kubeflow Pipelines sur votre cluster GKE
Suivez les instructions ci-dessous pour configurer Kubeflow Pipelines sur un cluster GKE.
Ouvrez AI Platform Pipelines dans Google Cloud Console.
Dans la barre d'outils AI Platform Pipelines, cliquez sur Nouvelle instance. Kubeflow Pipelines s'ouvre dans Google Cloud Marketplace.
Cliquez sur Configurer. Le formulaire Deploy Kubeflow Pipelines (Déployer Kubeflow Pipelines) s'ouvre.
Dans la liste déroulante Cluster, sélectionnez le cluster que vous avez créé précédemment. Si le cluster que vous souhaitez utiliser n'est pas éligible pour le déploiement, vérifiez que votre cluster remplit les conditions requises pour déployer Kubeflow Pipelines.
Les espaces de noms permettent de gérer les ressources des clusters GKE volumineux. Si vous ne prévoyez pas d'utiliser les espaces de noms de votre cluster, sélectionnez Par défaut dans la liste déroulante Espace de noms.
Si vous envisagez d'utiliser des espaces de noms dans votre cluster GKE, créez-en un à l'aide de la liste déroulante Espace de noms. Pour créer un espace de noms, procédez comme suit :
- Cliquez sur Créer un espace de noms dans la liste déroulante Espace de noms. Le champ Nom du nouvel espace de noms s'affiche.
- Saisissez le nom de l'espace de noms dans le champ Nom du nouvel espace de noms.
Pour en savoir plus sur les espaces de noms, consultez un article de blog (en anglais) sur l'organisation de Kubernetes avec des espaces de noms.
Dans la zone Nom de l'instance d'application, saisissez le nom de votre instance Kubeflow Pipelines.
Le stockage géré vous permet de stocker les métadonnées et les artefacts de votre pipeline de ML à l'aide de Cloud SQL et de Cloud Storage, au lieu de les stocker sur des disques persistants Compute Engine. L'utilisation de services gérés pour stocker les artefacts et les métadonnées de votre pipeline facilite la sauvegarde et la restauration des données de votre cluster. Pour déployer Kubeflow Pipelines avec le stockage géré, sélectionnez Utiliser le stockage géré et fournissez les informations suivantes :
Bucket de stockage Cloud Storage : avec le stockage géré, Kubeflow Pipelines stocke les artefacts de pipeline dans un bucket Cloud Storage. Indiquez le nom du bucket dans lequel vous souhaitez que Kubeflow Pipelines stocke les artefacts. Si le bucket spécifié n'existe pas, le déployeur Kubeflow Pipelines crée automatiquement un bucket pour vous dans la région
us-central1.Nom de connexion de l'instance Cloud SQL : avec le stockage géré, Kubeflow Pipelines stocke les métadonnées de pipeline dans une base de données MySQL sur Cloud SQL. Indiquez le nom de la connexion de votre instance MySQL Cloud SQL.
Apprenez-en plus sur la configuration d'une instance Cloud SQL.
Nom d'utilisateur de la base de données : indiquez le nom d'utilisateur de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Actuellement, votre utilisateur de base de données doit disposer des privilèges MySQL
ALLpour déployer Kubeflow Pipelines avec le stockage géré. Si vous laissez ce champ vide, cette valeur est définie par défaut sur root.Mot de passe de la base de données : indiquez le mot de passe de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Si vous laissez ce champ vide, Kubeflow Pipelines se connecte à votre base de données sans fournir de mot de passe, ce qui échoue si un mot de passe est requis pour le nom d'utilisateur spécifié.
Préfixe du nom de base de données : indiquez le préfixe du nom de base de données. La valeur du préfixe doit commencer par une lettre et ne contenir que des lettres minuscules, des chiffres et des traits de soulignement.
Au cours du processus de déploiement, Kubeflow Pipelines crée deux bases de données, "DATABASE_NAME_PREFIX_pipeline" et "DATABASE_NAME_PREFIX_metadata". Si des bases de données portant ces noms existent dans votre instance MySQL, Kubeflow Pipelines réutilise les bases de données existantes. Si cette valeur n'est pas spécifiée, le nom de l'instance d'application est utilisé comme préfixe du nom de base de données.
Cliquez sur Déployer. Cette opération peut prendre plusieurs minutes.
Pour accéder au tableau de bord des pipelines, ouvrez AI Platform Pipelines dans la console Google Cloud.
Accéder à AI Platform Pipelines
Cliquez ensuite sur Ouvrir le tableau de bord des pipelines pour votre instance AI Platform Pipelines.
Déployer AI Platform Pipelines sur un cluster GKE existant
Pour déployer Kubeflow Pipelines sur un cluster GKE à l'aide de Google Cloud Marketplace, les conditions suivantes doivent être remplies :
- Votre cluster doit comporter au moins trois nœuds. Chaque nœud doit disposer d'au moins deux processeurs et de 4 Go de mémoire disponible.
- Le niveau d'accès du cluster doit accorder un accès complet à toutes les API Cloud, ou votre cluster doit utiliser un compte de service personnalisé.
- Kubeflow Pipelines ne doit pas déjà être installé sur le cluster.
Découvrez comment configurer votre cluster GKE pour AI Platform Pipelines.
Suivez les instructions ci-dessous pour configurer Kubeflow Pipelines sur un cluster GKE.
Ouvrez AI Platform Pipelines dans Google Cloud Console.
Dans la barre d'outils AI Platform Pipelines, cliquez sur Nouvelle instance. Kubeflow Pipelines s'ouvre dans Google Cloud Marketplace.
Cliquez sur Configurer. Le formulaire Deploy Kubeflow Pipelines (Déployer Kubeflow Pipelines) s'ouvre.
Dans la liste déroulante Cluster, sélectionnez votre cluster. Si le cluster que vous souhaitez utiliser n'est pas éligible pour le déploiement, vérifiez que votre cluster remplit les conditions requises pour déployer Kubeflow Pipelines.
Les espaces de noms permettent de gérer les ressources des clusters GKE volumineux. Si votre cluster n'utilise pas d'espaces de noms, sélectionnez Par défaut dans la liste déroulante Espace de noms.
Si votre cluster utilise des espaces de noms, sélectionnez un espace de noms existant ou créez-en un à l'aide de la liste déroulante Espace de noms. Pour créer un espace de noms, procédez comme suit :
- Cliquez sur Créer un espace de noms dans la liste déroulante Espace de noms. Le champ Nom du nouvel espace de noms s'affiche.
- Saisissez le nom de l'espace de noms dans le champ Nom du nouvel espace de noms.
Pour en savoir plus sur les espaces de noms, consultez un article de blog (en anglais) sur l'organisation de Kubernetes avec des espaces de noms.
Dans la zone Nom de l'instance d'application, saisissez le nom de votre instance Kubeflow Pipelines.
Le stockage géré vous permet de stocker les métadonnées et les artefacts de votre pipeline de ML à l'aide de Cloud SQL et de Cloud Storage, au lieu de les stocker sur des disques persistants Compute Engine. L'utilisation de services gérés pour stocker les artefacts et les métadonnées de votre pipeline facilite la sauvegarde et la restauration des données de votre cluster. Pour déployer Kubeflow Pipelines avec le stockage géré, sélectionnez Utiliser le stockage géré et fournissez les informations suivantes :
Bucket de stockage Cloud Storage : avec le stockage géré, Kubeflow Pipelines stocke les artefacts de pipeline dans un bucket Cloud Storage. Indiquez le nom du bucket dans lequel vous souhaitez que Kubeflow Pipelines stocke les artefacts. Si le bucket spécifié n'existe pas, le déployeur Kubeflow Pipelines crée automatiquement un bucket pour vous dans la région
us-central1.Nom de connexion de l'instance Cloud SQL : avec le stockage géré, Kubeflow Pipelines stocke les métadonnées de pipeline dans une base de données MySQL sur Cloud SQL. Indiquez le nom de la connexion de votre instance MySQL Cloud SQL.
Apprenez-en plus sur la configuration d'une instance Cloud SQL.
Nom d'utilisateur de la base de données : indiquez le nom d'utilisateur de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Actuellement, votre utilisateur de base de données doit disposer des privilèges MySQL
ALLpour déployer Kubeflow Pipelines avec le stockage géré. Si vous laissez ce champ vide, cette valeur est définie par défaut sur root.Mot de passe de la base de données : indiquez le mot de passe de la base de données que Kubeflow Pipelines doit utiliser lors de la connexion à l'instance MySQL. Si vous laissez ce champ vide, Kubeflow Pipelines se connecte à votre base de données sans fournir de mot de passe, ce qui échoue si un mot de passe est requis pour le nom d'utilisateur spécifié.
Préfixe du nom de base de données : indiquez le préfixe du nom de base de données. La valeur du préfixe doit commencer par une lettre et ne contenir que des lettres minuscules, des chiffres et des traits de soulignement.
Au cours du processus de déploiement, Kubeflow Pipelines crée deux bases de données, "DATABASE_NAME_PREFIX_pipeline" et "DATABASE_NAME_PREFIX_metadata". Si des bases de données portant ces noms existent dans votre instance MySQL, Kubeflow Pipelines réutilise les bases de données existantes. Si cette valeur n'est pas spécifiée, le nom de l'instance d'application est utilisé comme préfixe du nom de base de données.
Cliquez sur Déployer. Cette opération peut prendre plusieurs minutes.
Pour accéder au tableau de bord des pipelines, ouvrez AI Platform Pipelines dans la console Google Cloud.
Accéder à AI Platform Pipelines
Cliquez ensuite sur Ouvrir le tableau de bord des pipelines pour votre instance AI Platform Pipelines.
Étape suivante
- Orchestrez votre processus de ML en tant que pipeline.
- Utilisez l'interface utilisateur de Kubeflow Pipelines pour exécuter un pipeline.
- Apprenez-en plus sur AI Platform Pipelines et les pipelines de ML.