LangChain sur Vertex AI (preview) vous permet d'utiliser la bibliothèque Open Source LangChain pour créer des applications d'IA générative personnalisées et d'utiliser Vertex AI pour les modèles, les outils et le déploiement. Avec LangChain sur Vertex AI, vous pouvez effectuer les opérations suivantes :
- Sélectionner le grand modèle de langage (LLM) avec lequel vous souhaitez travailler
- Définir des outils pour accéder aux API externes
- Structurez l'interface entre l'utilisateur et les composants du système dans un framework d'orchestration.
- Déployez le framework dans un environnement d'exécution géré
Avantages
- Personnalisable : en utilisant les interfaces standardisées de LangChain, LangChain sur Vertex AI peut être adopté pour créer différentes sortes d'applications. Vous pouvez personnaliser la logique de votre application et intégrer n'importe quel framework, ce qui offre un haut degré de flexibilité.
- Simplification du déploiement : LangChain sur Vertex AI utilise les mêmes API que LangChain pour interagir avec les LLM et créer des applications. LangChain sur Vertex AI simplifie et accélère le déploiement avec les LLM Vertex AI, car l'environnement d'exécution Reasoning Engine permet le déploiement en un seul clic afin de générer une API conforme basée sur votre bibliothèque.
- Intégration aux écosystèmes Vertex AI : Reasoning Engine pour LangChain sur Vertex AI utilise l'infrastructure de Vertex AI et des conteneurs prédéfinis pour vous aider à déployer votre application LLM. Vous pouvez utiliser l'API Vertex AI pour intégrer des modèles Gemini, des appels de fonction et des extensions.
- Sécurité, confidentialité et évolutivité : vous pouvez utiliser un seul appel de SDK au lieu de gérer vous-même le processus de développement. L'environnement d'exécution géré Reasoning Engine vous libère de certaines tâches telles que le développement du serveur d'application, la création de conteneurs et la configuration de l'authentification, d'IAM et du scaling. Vertex AI gère l'autoscaling, l'expansion régionale et les failles des conteneurs.
Cas d'utilisation
Pour découvrir LangChain sur Vertex AI avec des exemples de bout en bout, consultez les ressources suivantes:
| Cas d'utilisation | Description | Lien(s) |
|---|---|---|
| Créer des applications d'IA générative en vous connectant à des API publiques | Convertir des devises Créez une fonction qui se connecte à une application de change de devises pour permettre au modèle de fournir des réponses précises à des requêtes telles que "Quel est le taux de change de l'euro par rapport au dollar aujourd'hui ?" |
Notebook SDK Vertex AI pour Python : présentation de la création et du déploiement d'un agent avec Reasoning Engine |
| Concevoir un projet d'énergie solaire communautaire. Identifiez les emplacements potentiels, recherchez les autorités administratives et les fournisseurs concernés, et examinez les images satellites et le potentiel solaire des régions et des bâtiments pour trouver l'emplacement optimal pour installer vos panneaux solaires. |
Notebook du SDK Vertex AI pour Python : création et déploiement d'un agent de l'API Google Maps avec Vertex AI Reasoning Engine | |
| Créer des applications d'IA générative en se connectant à des bases de données | Intégration à AlloyDB et CloudSQL PostgreSQL. | Article de blog : Annonce de LangChain sur Vertex AI pour AlloyDB et Cloud SQL pour PostgreSQL Notebook du SDK Vertex AI pour Python : déployer une application RAG avec Cloud SQL pour PostgreSQL sur LangChain dans Vertex AI Notebook du SDK Vertex AI pour Python : déployer une application RAG avec AlloyDB sur LangChain dans Vertex AI |
| Interroger et comprendre des datastores structurés en langage naturel | Notebook SDK Vertex AI pour Python : créer un agent de recherche conversationnel avec Vertex AI Reasoning Engine et le RAG dans Vertex AI Search | |
| Interroger et comprendre des bases de données orientées graphe en langage naturel | Article de blog : GraphRAG GenAI et agents d'IA utilisant Vertex AI Reasoning Engine avec LangChain et Neo4j | |
| Interroger et comprendre des magasins de vecteurs en langage naturel | Article de blog : Simplifier le RAG GenAI avec MongoDB Atlas et Vertex AI Reasoning Engine | |
| Créer des applications d'IA générative avec des frameworks OSS | Créez et déployez des agents à l'aide du framework Open Source Onetwo. | Article de blog : OneTwo et Vertex AI Reasoning Engine : explorer le développement d'agents d'IA avancée sur Google Cloud |
| Créer et déployer des agents à l'aide du framework Open Source LangGraph. | Notebook SDK Vertex AI pour Python : créer et déployer une application LangGraph avec Vertex AI Reasoning Engine | |
| Déboguer et optimiser des applications d'IA générative | Créer et tracer des agents à l'aide d'OpenTelemetry et de Cloud Trace | Notebook SDK Vertex AI pour Python : débogage et optimisation des agents : guide de traçage dans Vertex AI Reasoning Engine |
Composants du système
La création et le déploiement d'une application d'IA générative personnalisée à l'aide d'OSS LangChain et de l'IA générative Vertex se composent de quatre composants :
| Composant | Description |
|---|---|
| LLM |
Lorsque vous envoyez une requête à votre application personnalisée, le LLM la traite et fournit une réponse. Vous pouvez choisir de définir un ensemble d'outils qui communiquent avec des API externes et les fournir au modèle. Lors du traitement d'une requête, le modèle délègue certaines tâches aux outils. Cela implique un ou plusieurs appels de modèle à des modèles de base ou affinés. Pour en savoir plus, consultez la page Versions et cycle de vie des modèles. |
| Outil |
Vous pouvez choisir de définir un ensemble d'outils qui communiquent avec des API externes (par exemple, une base de données) et les fournir au modèle. Lors du traitement d'une requête, le modèle peut déléguer certaines tâches aux outils. Le déploiement via l'environnement d'exécution géré de l'IA Vertex est optimisé pour utiliser des outils basés sur l'appel de fonction Gemini, mais est compatible avec l'outil/l'appel de fonction LangChain. Pour en savoir plus sur les appels de fonctions Gemini, consultez la page Appel de fonction. |
| Framework d'orchestration |
LangChain sur Vertex AI vous permet d'utiliser le framework d'orchestration LangChain dans Vertex AI. Utilisez LangChain pour déterminer le niveau de déterminisme de votre application. Si vous utilisez déjà LangChain, vous pouvez utiliser votre code LangChain existant pour déployer votre application sur l'IA Vertex. Sinon, vous pouvez créer votre propre code d'application et le structurer dans un framework d'orchestration qui exploite les modèles LangChain de l'IA Vertex. Pour en savoir plus, consultez la page Développer une application. |
| Environnement d'exécution géré | LangChain sur Vertex AI vous permet de déployer votre application dans un environnement d'exécution géré Reasoning Engine. Cet environnement d'exécution est un service Vertex AI qui présente tous les avantages de l'intégration à Vertex AI : sécurité, confidentialité, observabilité et évolutivité. Vous pouvez mettre votre application en production et la faire évoluer à l'aide d'un appel d'API, vous permettant ainsi de transformer rapidement des prototypes testés localement en déploiements adaptés aux entreprises. Pour en savoir plus, consultez Déployer une application. |
Il existe de nombreuses façons de créer des prototypes et des applications d'IA générative personnalisées qui utilisent les capacités agentives en superposant des outils et des fonctions personnalisées sur des modèles tels que Gemini. Au moment de passer votre application en production, vous devez déterminer comment déployer et gérer votre agent et ses composants sous-jacents.
Avec les composants de LangChain sur Vertex AI, l'objectif est de vous aider à vous concentrer et à personnaliser les aspects des fonctionnalités de l'agent qui vous intéressent le plus, tels que les fonctions personnalisées, le comportement de l'agent et les paramètres du modèle, tandis que Google s'occupe du déploiement, du scaling, de l'empaquetage et des versions. Si vous travaillez à un niveau inférieur de la pile, vous devrez peut-être gérer plus que vous ne le souhaitez. Si vous intervenez à un niveau supérieur de la pile, vous n'aurez peut-être pas autant de contrôle des développeurs que ce que vous espériez.
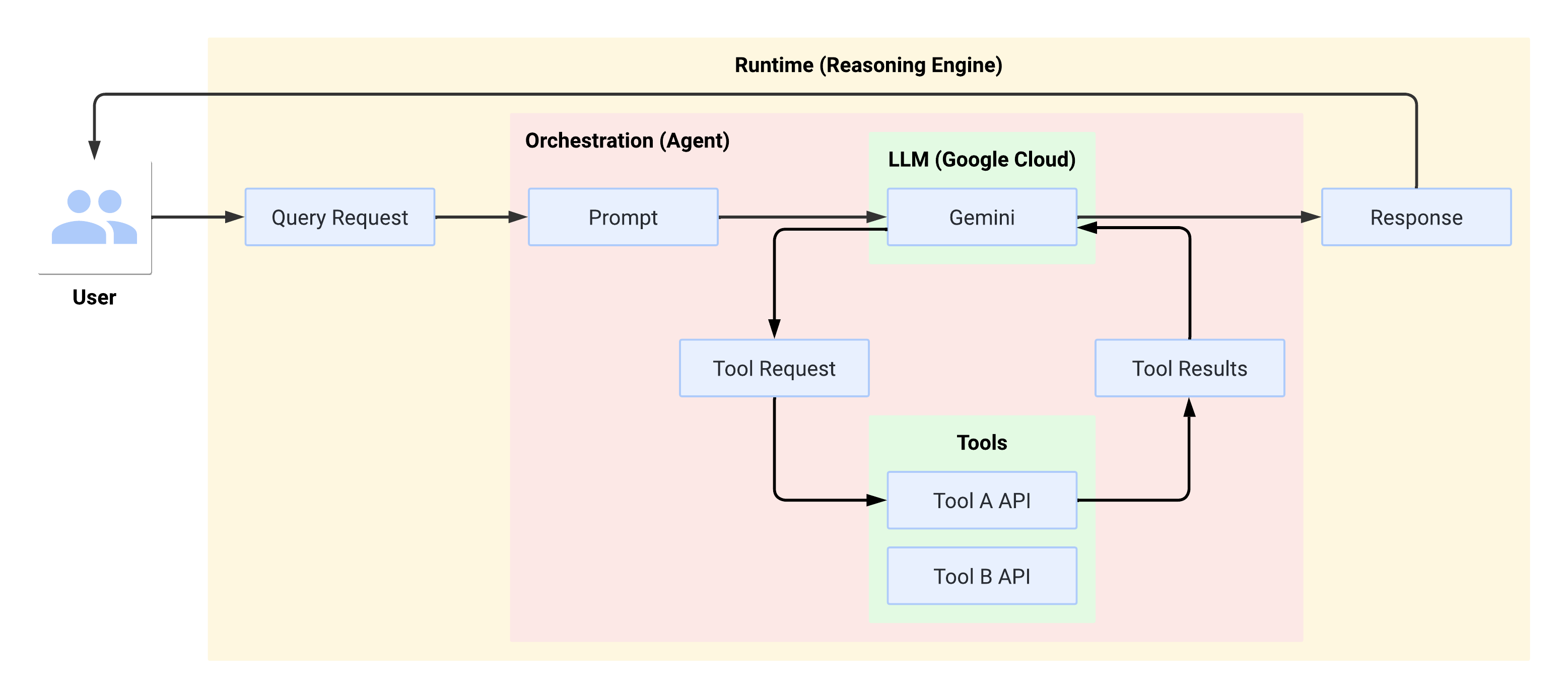
Flux système lors de l'exécution
Lorsque l'utilisateur envoie une requête, l'agent défini la présente sous forme de requête au LLM. Le LLM traite la requête et détermine s'il souhaite utiliser l'un des outils.
Si le LLM choisit d'utiliser un outil, il génère un FunctionCall avec le nom et les paramètres avec lesquels l'outil doit être appelé. L'agent appelle l'outil avec FunctionCall et renvoie les résultats de l'outil au LLM.
Si le LLM choisit de ne pas utiliser d'outil, il génère du contenu qui sera transmis par l'agent à l'utilisateur.
Le schéma suivant illustre le flux système lors de l'exécution :
Créer et déployer une application d'IA générative
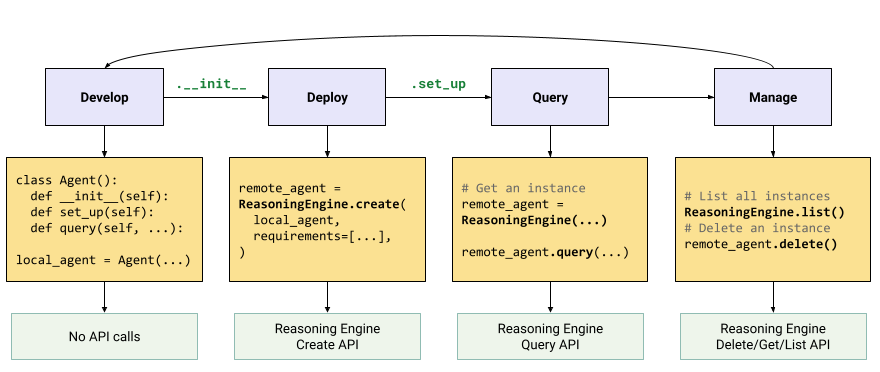
Le workflow pour créer une application d'IA générative est le suivant :
| Étapes | Description |
|---|---|
| 1. Configurer l'environnement | Configurez votre projet Google et installez la dernière version du SDK Vertex AI pour Python. |
| 2. Développer une application | Développez une application LangChain pouvant être déployée sur Reasoning Engine. |
| 3. Déployer l'application | Déployez l'application sur Reasoning Engine. |
| 4. Utiliser l'application | Moteur de raisonnement de requête pour une réponse. |
| 5. Gérer l'application déployée | Gérez et supprimez les applications que vous avez déployées sur Reasoning Engine. |
| 6. (Facultatif) Personnaliser un modèle d'application | Personnalisez un modèle pour les nouvelles applications. |
Les étapes sont illustrées dans le schéma suivant :
Tarifs
La structure tarifaire est basée sur les heures de vCPU et les heures de Go utilisées lors du traitement des requêtes, du démarrage et de l'arrêt des conteneurs. Cela signifie que les ressources de calcul (processeurs virtuels) et de mémoire consommées par vos charges de travail vous seront facturées.
Nous vous recommandons de supprimer les ressources inutilisées pour éviter de générer des coûts indésirables.