Nesta página, apresentamos uma visão geral do ajuste de modelos de texto e chat e da destilação de modelos de texto. Você conhecerá os tipos de ajuste disponíveis e como funciona a destilação. Você também conhecerá os benefícios do ajuste e da destilação, além de cenários de quando é recomendável ajustar ou destilar um modelo de texto.
Ajustar modelos.
É possível escolher um dos seguintes métodos para ajustar um modelo de texto:
Ajuste supervisionado: os modelos de geração de texto e chat de texto oferecem suporte ao ajuste supervisionado. O ajuste supervisionado de um modelo de texto é uma boa opção quando a saída do modelo não é complexa e é relativamente fácil de definir. O ajuste supervisionado é recomendado para classificação, análise de sentimento, extração de entidade, resumo de conteúdo que não é complexo e gravação de consultas específicas do domínio. Para modelos de código, o ajuste supervisionado é a única opção. Para saber como ajustar um modelo de texto com o ajuste supervisionado, consulte Ajustar modelos de texto com ajuste supervisionado.
Ajuste do aprendizado por reforço a partir do feedback humano (RLHF, na sigla em inglês): o modelo de base de geração de texto e alguns modelos de transformador de transferência de texto para texto em Flan (Flan-T5) oferecem suporte ao ajuste de RLHF. O ajuste de RLHF é uma boa opção quando a saída do modelo é complexa. O RLHF funciona bem em modelos com objetivos de nível sequencial que não são facilmente diferenciados com o ajuste supervisionado. O ajuste de RLHF é recomendado para responder a perguntas, resumir conteúdo complexo e criar conteúdo, como uma reescrita. Para saber como ajustar um modelo de texto com o ajuste de RLHF, consulte Ajustar modelos de texto com o ajuste de RLHF.
Benefícios do ajuste de modelos de texto
Os modelos de texto ajustados são treinados com mais exemplos do que cabem em um prompt. Por isso, depois do ajuste de um modelo pré-treinado, é possível fornecer menos exemplos no prompt do que faria com o modelo pré-treinado original. A exigência de menos exemplos resulta nos seguintes benefícios:
- Latência menor nas solicitações.
- Menos tokens são usados.
- Latência menor e menos tokens resultam na redução do custo da inferência.
Destilação de modelo
Além do ajuste supervisionado e do aprendizado por reforço com feedback humano (RLHF), a Vertex AI é compatível com a destilação de modelos. Destilação é o processo de treinamento de um modelo estudante menor em um modelo professor maior para imitar o comportamento do modelo maior e reduzir o tamanho.
Há vários tipos de destilação de modelos, incluindo:
- Com base em respostas: treine o modelo estudante com base nas probabilidades de resposta do modelo professor.
- Com base em atributos: treine o modelo estudante para imitar as camadas internas do modelo professor.
- Com base em relações: treine o modelo estudante com base em relações nos dados de entrada ou saída do modelo professor.
- Autodestilação: os modelos professor e estudante têm a mesma arquitetura e o modelo aprende sozinho.
Benefícios da destilação passo a passo
Os benefícios da destilação passo a passo incluem:
- Maior acurácia: a destilação passo a passo demonstrou desempenho melhor que os comandos de poucos disparos (few-shot) padrão em LLMs.
- Um LLM destilado pode alcançar resultados em tarefas finais específicas dos usuários que são semelhantes aos resultados de LLMs muito maiores.
- Superar as restrições de dados. É possível usar a DSS com um conjunto de dados de comandos não rotulado com apenas alguns milhares de exemplos.
- Consumos de hospedagem menores.
- Latência de inferência reduzida.
Destilação passo a passo usando a Vertex AI
A Vertex AI permite uma forma de destilação com base em resposta chamada destilação passo a passo (DSS). A DSS é um método para treinar modelos menores e específicos para tarefas via comandos de cadeia de pensamento (COT).
Para usar a DSS, você precisa de um pequeno conjunto de dados de treinamento composto por entradas e rótulos. Se não houver rótulos disponíveis, eles serão gerados pelo modelo professor. As lógicas são extraídas pelo processo de DSS e, em seguida, usadas para treinar o modelo pequeno com uma tarefa de geração de lógica e uma tarefa de previsão típica. Isso permite que o modelo pequeno crie um raciocínio intermediário antes de chegar à previsão final.
No diagrama a seguir, mostramos como a destilação passo a passo usa comandos COT para extrair lógicas de um modelo de linguagem grande (LLM). As lógicas são usadas para treinar modelos menores específicos para tarefas.
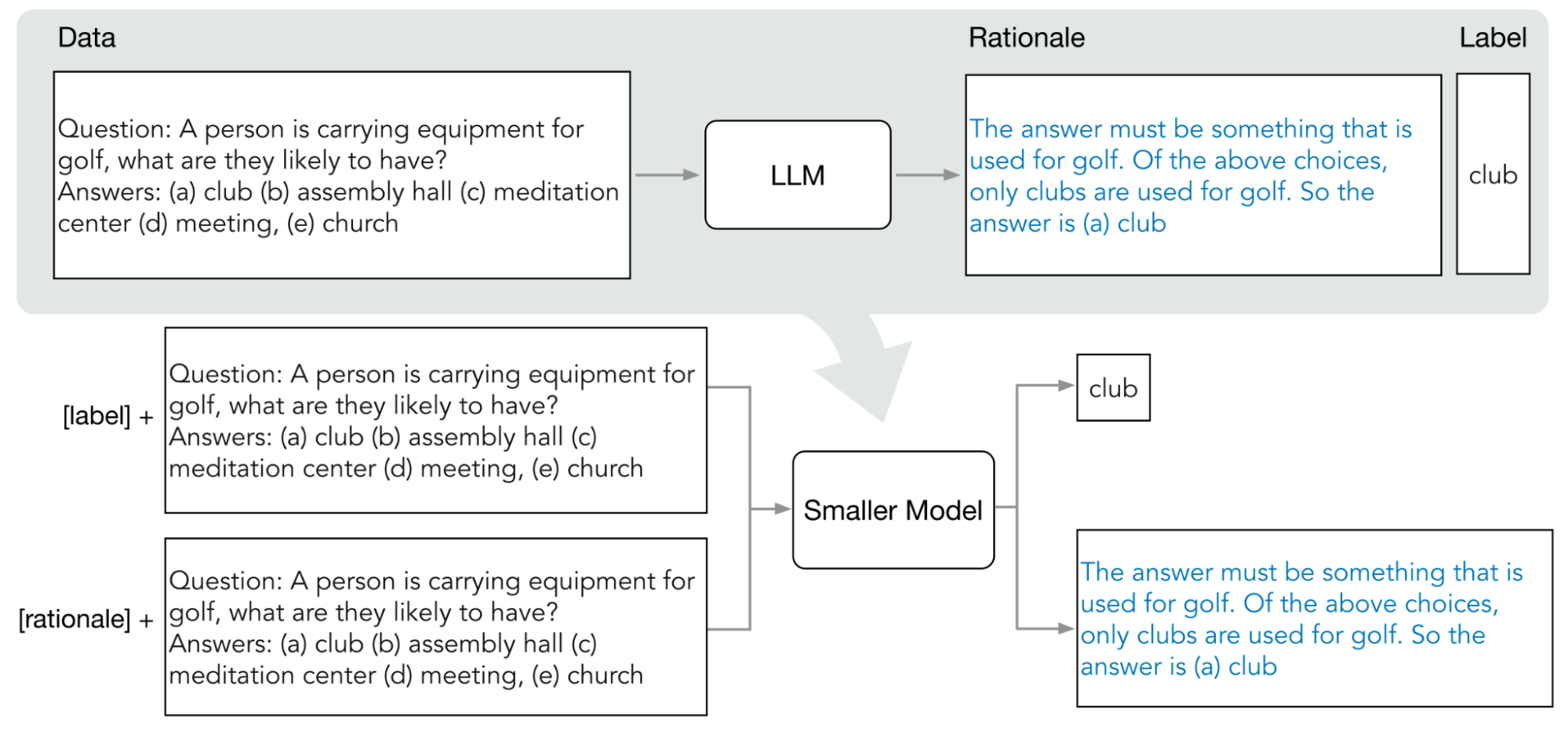
Cota
Cada projeto do Google Cloud requer cota suficiente para executar um job de ajuste, e um job de ajuste usa oito GPUs. Se o projeto não tiver cota suficiente para um job de ajuste ou você quiser executar vários jobs de ajuste simultâneos nele, será necessário solicitar cota extra.
A seguinte tabela mostra o tipo e a quantidade de cota a ser solicitada, de acordo com a região em que você especificou o ajuste:
| Região | Cota de recursos | Valor por job simultâneo |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
Preços
Ao ajustar ou destilar um modelo de fundação, você paga o custo de execução do pipeline de ajuste ou destilação. Quando você implanta um modelo de fundação ajustado em um endpoint da Vertex AI, não há cobranças pela hospedagem. Para exibir previsões, você paga o mesmo preço de quando exibe previsões usando um modelo de fundação não ajustado (para ajuste) ou o modelo estudante (para destilação). Para saber quais modelos de fundação podem ser ajustados e refinados, consulte Modelos de fundação. Para detalhes sobre preços, consulte Preços da IA generativa na Vertex AI.
A seguir
- Saiba como ajustar um modelo básico usando o ajuste supervisionado.
- Saiba como ajustar um modelo básico usando o ajuste RLHF.
- Saiba como ajustar um modelo de código.
- Saiba como destilar um modelo de texto.