이 페이지에서는 텍스트 및 채팅 모델을 조정하고 텍스트 모델을 정제하는 방법을 간략히 설명합니다. 사용 가능한 조정 유형과 정제의 작동 방식에 대해 알아봅니다. 또한 조정 및 정제의 이점과 텍스트 모델을 조정하거나 정제해야 하는 시나리오에 대해 알아봅니다.
모델 조정
다음 방법 중 하나를 선택하여 텍스트 모델을 조정할 수 있습니다.
지도 조정 - 텍스트 생성 및 텍스트 채팅 모델은 지도 조정을 지원합니다. 텍스트 모델의 지도 조정은 모델 출력이 복잡하지 않고 비교적 정의하기 쉬운 경우 적합한 옵션입니다. 지도 조정은 분류, 감정 분석, 항목 추출, 복잡하지 않은 콘텐츠 요약, 도메인별 쿼리 작성에 권장됩니다. 코드 모델에서는 지도 조정만 사용할 수 있습니다. 지도 조정으로 텍스트 모델을 조정하는 방법은 지도 조정으로 텍스트 모델 조정을 참조하세요.
인간 피드백 기반 강화 학습(RLHF) 조정 - 텍스트 생성 기반 모델과 일부 Flan 텍스트-텍스트 전송 변환기(Flan-T5) 모델이 RLHF 조정을 지원합니다. RLHF 조정은 모델 출력이 복잡한 경우 적합한 옵션입니다. RLHF는 감독 조정과 쉽게 구별되지 않는 시퀀스 수준 목표를 가진 모델에서 잘 작동합니다. RLHF 조정은 질의 응답, 복잡한 콘텐츠 요약, 재작성과 같은 콘텐츠 생성에 권장됩니다. RLHF 조정으로 텍스트 모델을 조정하는 방법은 RLHF 조정으로 텍스트 모델 조정을 참조하세요.
텍스트 모델 조정의 이점
조정된 텍스트 모델은 프롬프트에 들어갈 수 있는 것보다 더 많은 예시를 학습합니다. 따라서 사전 학습된 모델을 조정한 후 프롬프트에 원래 선행 학습된 모델보다 더 적은 예시를 제공할 수 있습니다. 예시가 더 적으면 다음과 같은 이점이 있습니다.
- 요청의 지연 시간이 줄어듭니다.
- 사용되는 토큰이 더 적습니다.
- 지연 시간이 짧고 토큰 수가 적으면 추론 비용이 줄어듭니다.
모델 정제
Vertex AI는 지도 조정 및 RLHF 조정 외에 모델 정제도 지원합니다. 정제는 크기를 축소하면서 큰 모델의 동작을 모방하기 위해 큰 티처 모델에 작은 스튜던트 모델을 학습시키는 프로세스입니다.
모델 정제에는 다음과 같은 여러 가지 유형이 있습니다.
- 응답 기반: 티처 모델의 응답 확률을 스튜던트 모델에 학습시킵니다.
- 특성 기반: 티처 모델의 내부 레이어를 모방하도록 스튜던트 모델을 학습시킵니다.
- 관계 기반: 티처 모델에서 입력 또는 출력 데이터의 관계를 스튜던트 모델에 학습시킵니다.
- 자체 정제: 티처 및 스튜던트 모델이 동일한 아키텍처를 사용하고 자체적으로 학습됩니다.
단계별 정제의 이점
단계별 정제의 이점은 다음과 같습니다.
- 정확성 향상: 단계별 정제는 LLM에서 표준 퓨샷 프롬프팅을 능가하는 것으로 입증되었습니다.
- 정제된 LLM은 훨씬 더 큰 LLM의 결과와 유사한 사용자의 특정 최종 태스크에 대한 결과를 달성할 수 있습니다.
- 데이터 제약조건 해결. 예시가 수천 개밖에 없는 라벨 없는 프롬프트 데이터 세트에 DSS를 사용할 수 있습니다.
- 호스팅 사용 공간 감소
- 추론 지연 시간 감소
Vertex AI를 사용한 단계별 정제
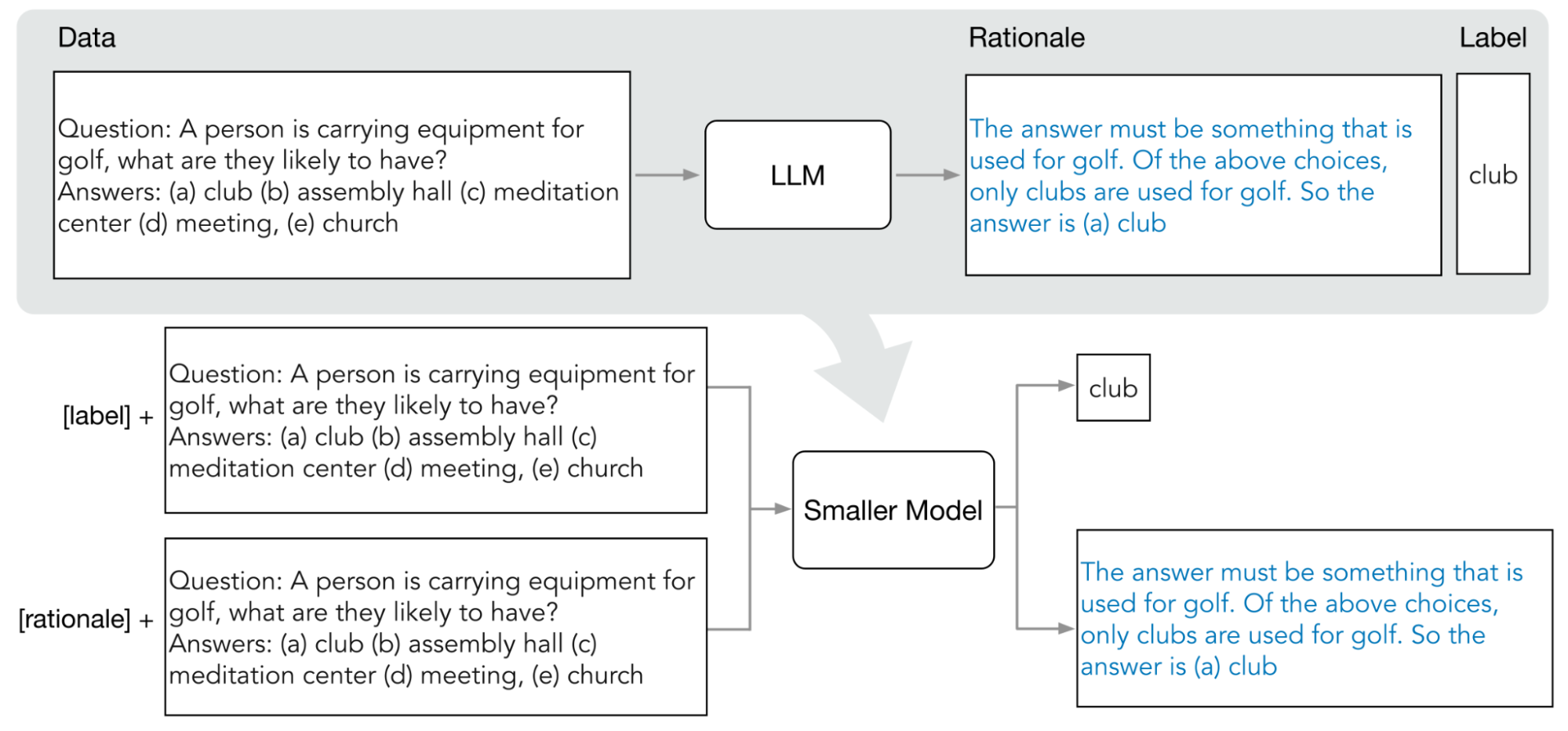
Vertex AI는 단계별 정제(DSS)라는 응답 기반 정제 형태를 지원합니다. DSS는 연쇄 사고(COT) 프롬프팅을 통해 작은 태스크별 모델을 학습시키는 방법입니다.
DSS를 사용하려면 입력과 라벨로 구성된 작은 학습 데이터 세트가 필요합니다. 라벨을 사용할 수 없는 경우에는 티처 모델이 라벨을 생성합니다. DSS 프로세스에 의해 근거가 추출된 후 근거 생성 태스크와 일반적인 예측 태스크로 소규모 모델을 학습시키는 데 사용됩니다. 따라서 작은 모델이 최종 예측에 도달하기 전에 중간 추론을 구축할 수 있습니다.
다음 다이어그램은 단계별 정제가 COT 프롬프팅을 사용하여 대규모 언어 모델(LLM)에서 근거를 추출하는 방법을 보여줍니다. 근거는 작은 태스크별 모델을 학습시키는 데 사용됩니다.
할당량
각 Google Cloud 프로젝트에는 조정 작업 하나를 실행하기에 충분한 할당량이 필요하며 조정 작업 하나는 GPU 8개를 사용합니다. 프로젝트에 조정 작업 하나를 위한 할당량이 부족하거나 프로젝트에서 동시 조정 작업 여러 개를 실행하려는 경우에는 추가 할당량을 요청해야 합니다.
다음 표는 조정을 수행하도록 지정한 리전에 따라 요청할 할당량 유형과 양을 보여줍니다.
| 지역 | 리소스 할당량 | 동시 작업당 양 |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
가격 책정
기반 모델을 조정하거나 정제하면 조정 또는 정제 파이프라인 실행 비용을 지불해야 합니다. 조정 또는 정제된 기반 모델을 Vertex AI 엔드포인트에 배포할 때는 호스팅 비용이 부과되지 않습니다. 예측 서빙을 위해서는 조정되지 않은 기반 모델(조정용) 또는 스튜던트 모델(정제용)을 사용하여 예측을 서빙할 때 지불하는 것과 동일한 비용을 지불합니다. 조정 및 정제할 수 있는 기반 모델에 대해 자세히 알아보려면 기반 모델을 참조하세요. 자세한 내용은 Vertex AI의 생성형 AI 가격 책정을 참조하세요.
다음 단계
- 지도 조정을 사용하여 기반 모델 조정 방법 알아보기
- RLHF 조정을 사용하여 기반 모델 조정 방법 알아보기
- 코드 모델 조정 방법 알아보기
- 텍스트 모델 정제 방법 알아보기