Cette page vous offre un aperçu des réglages des modèles de texte et de chat, ainsi que de la distillation des modèles de texte. Vous découvrirez les types de réglages disponibles et le fonctionnement de la distillation. Vous découvrirez également les avantages du réglage et de la distillation, ainsi que des scénarios dans lesquels vous pouvez régler ou distiller un modèle de texte.
Régler des modèles
Vous pouvez choisir l'une des méthodes suivantes pour régler un modèle de texte :
Réglages supervisé : les modèles de génération de texte et de chat textuel sont compatibles avec le réglage supervisé. Le réglage supervisé d'un modèle de texte est une bonne option lorsque la sortie de votre modèle est complexe et relativement facile à définir. Il est recommandé d'utiliser un réglage supervisé pour la classification, l'analyse des sentiments, l'extraction d'entités, la synthèse de contenu non complexe et l'écriture de requêtes spécifiques à un domaine. Pour les modèles de code, le réglage supervisé est la seule option. Pour en savoir plus sur le réglage d'un modèle de texte avec le réglage supervisé, consultez la page Régler des modèles de texte à l'aide du réglage supervisé.
Réglage avec apprentissage automatique par renforcement qui utilise le feedback humain (RLHF) : le modèle de fondation de génération de texte et certains modèles (Flan-T5) de transformateurs de transfert de texte vers texte de type Flan sont compatibles avec le réglage RLHF. Le réglage RLHF est une bonne option lorsque la sortie de votre modèle est complexe. La fonction RLHF fonctionne bien sur les modèles ayant des objectifs d'objectifs au niveau de la séquence qui ne peuvent pas être facilement différenciés avec le réglage supervisé. Le réglage RLHF est recommandé pour les systèmes de questions-réponses, la synthèse de contenu complexe et la création de contenu, telle qu'une réécriture. Pour apprendre à régler un modèle de texte avec ce réglage RLHF, consultez la page Régler les modèles de texte avec réglage RLHF.
Avantages du réglage des modèles textuels
Les modèles de texte réglés sont entraînés sur un plus grand nombre d'exemples qu'une requête peut recevoir. De ce fait, une fois qu'un modèle pré-entraîné a été réglé, vous pouvez fournir moins d'exemples dans la requête qu'avec le modèle pré-entraîné d'origine. Exiger moins d'exemples présente les avantages suivants :
- Latence réduite dans les requêtes.
- Moins de jetons sont utilisés.
- Une latence plus faible et un nombre réduit de jetons réduisent le coût de l'inférence.
Distillation du modèle
En plus du réglage supervisé et RLHF, Vertex AI est compatible avec la distillation de modèles. La distillation consiste à entraîner un modèle élève plus petit sur un modèle enseignant plus grand pour imiter le comportement du modèle plus grand tout en réduisant sa taille.
Il existe plusieurs types de distillation de modèles, y compris:
- Basé sur les réponses: entraînez le modèle étudiant sur les probabilités de réponse du modèle enseignant.
- Basé sur les caractéristiques: entraînez le modèle élève pour qu'il imite les couches internes du modèle enseignant.
- Basé sur les relations: entraînez le modèle étudiant sur les relations dans les données d'entrée ou de sortie du modèle enseignant.
- Autodistillation: les modèles enseignant et élève ont la même architecture, et le modèle apprend lui-même.
Avantages de la distillation par étapes
Voici les avantages de la distillation par étapes:
- Précision accrue: la distillation étape par étape se révèle plus performante que les requêtes few-shot standards sur les LLM.
- Un LLM condensé peut obtenir des résultats sur les tâches finales spécifiques des utilisateurs qui sont similaires à ceux obtenus par des LLM beaucoup plus volumineux.
- Surmontez les contraintes liées aux données. Vous pouvez utiliser DSS avec un ensemble de données de requêtes sans libellé ne comportant que quelques milliers d'exemples.
- Encombrement d'hébergement réduit
- Latence d'inférence réduite.
Distiller des données étape par étape avec Vertex AI
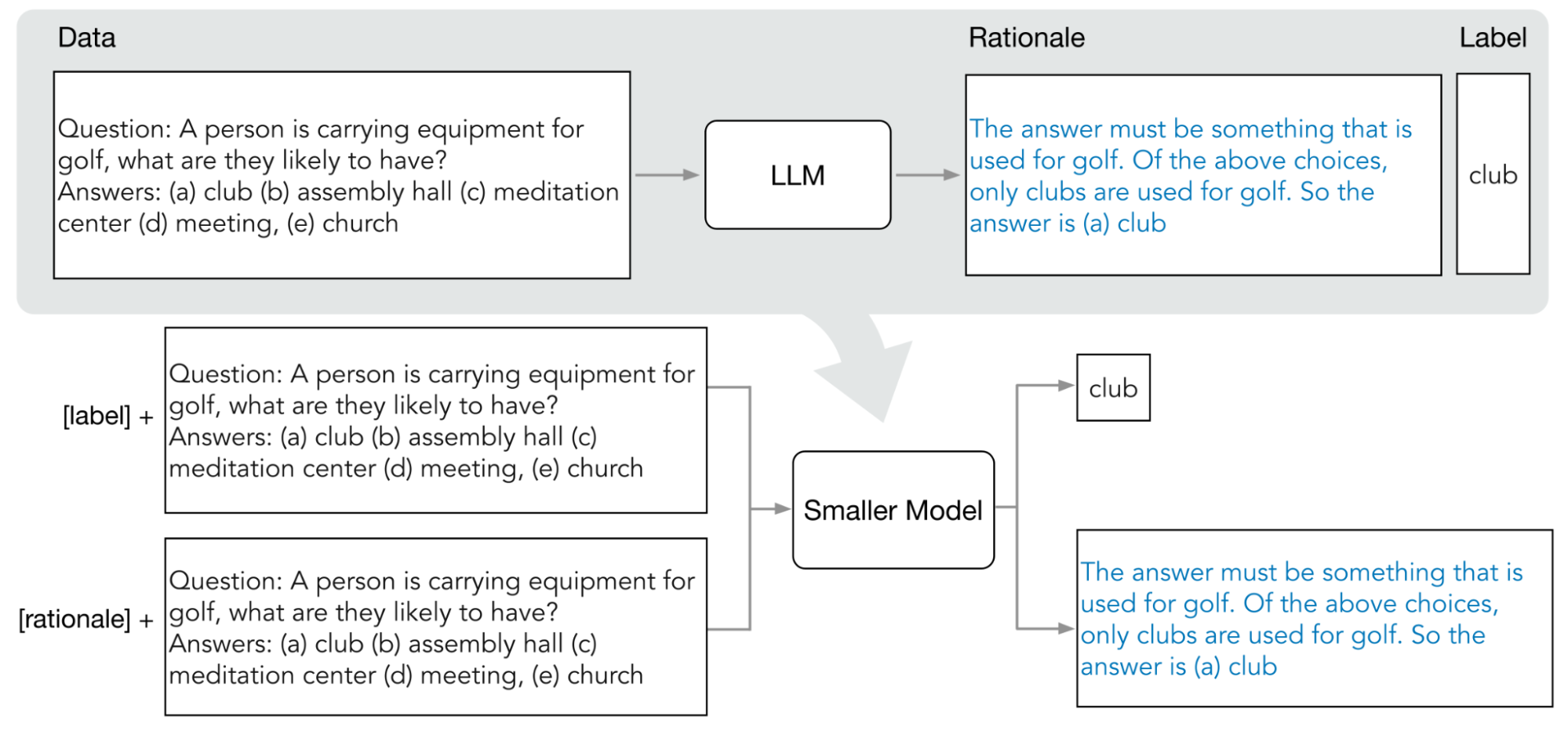
Vertex AI prend en charge une forme de distillation basée sur les réponses appelée distillation par étapes (DSS). DSS est une méthode permettant d'entraîner des modèles plus petits et spécifiques à une tâche via des requêtes en chaîne de pensée (COT, chain of thought).
Pour utiliser la DSS, vous avez besoin d'un petit ensemble de données d'entraînement composé d'entrées et de libellés. Si aucune étiquette n'est disponible, le modèle enseignant en génère. Les justifications sont extraites par le processus DSS, puis utilisées pour entraîner le petit modèle avec une tâche de génération de justifications et une tâche de prédiction typique. Cela permet au petit modèle de créer un raisonnement intermédiaire avant d'atteindre sa prédiction finale.
Le schéma suivant montre comment la distillation étape par étape utilise les requêtes COT pour extraire des logiques d'un grand modèle de langage (LLM). Les justifications sont utilisées pour entraîner des modèles plus petits sur une tâche spécifique.
Quota
Chaque projet Google Cloud nécessite un quota suffisant pour exécuter un job de réglage, et un job de réglage utilise huit GPU. Si votre projet ne dispose pas d'un quota suffisant pour un job de réglage ou si vous souhaitez exécuter plusieurs jobs de réglage simultanés dans votre projet, vous devez demander un quota supplémentaire.
Le tableau suivant indique le type et le montant de quota à demander en fonction de la région où vous avez effectué le réglage :
| Région | Quota de ressources | Montant par tâche simultanée |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
Tarification
Lorsque vous réglez ou distillez un modèle de fondation, vous payez le coût d'exécution du pipeline de réglage ou de distillation. Lorsque vous déployez un modèle de fondation réglé ou distillé sur un point de terminaison Vertex AI, l'hébergement ne vous est pas facturé. Pour servir des prédictions, vous payez le même prix que pour servir des prédictions à l'aide d'un modèle de fondation non affiné (pour l'affinement) ou le modèle élève (pour la distillation). Pour savoir quels modèles de fondation peuvent être réglés et distillés, consultez Modèles de fondation. Pour en savoir plus, consultez la page Tarifs de l'IA générative sur Vertex AI.
Étapes suivantes
- Découvrez comment régler un modèle de fondation à l'aide du réglage supervisé.
- Découvrez comment régler un modèle de fondation à l'aide du réglage RLHF.
- Découvrez comment régler un modèle de code.
- Découvrez comment distiller un modèle de texte.