流式传输涉及在生成对提示的响应时接收这些响应。也就是说,只要模型生成输出词元,就会发送这些输出词元。
您可以使用以下工具向 Vertex AI 大语言模型 (LLM) 发送流式传输请求:
- Vertex AI 具有服务器发送的事件 (SSE) 的 REST API
- Vertex AI REST API
- Python 版 Vertex AI SDK
- 客户端库
流式传输 API 和非流式传输 API 使用相同的参数,并且在价格和配额上没有区别。
Vertex AI Studio
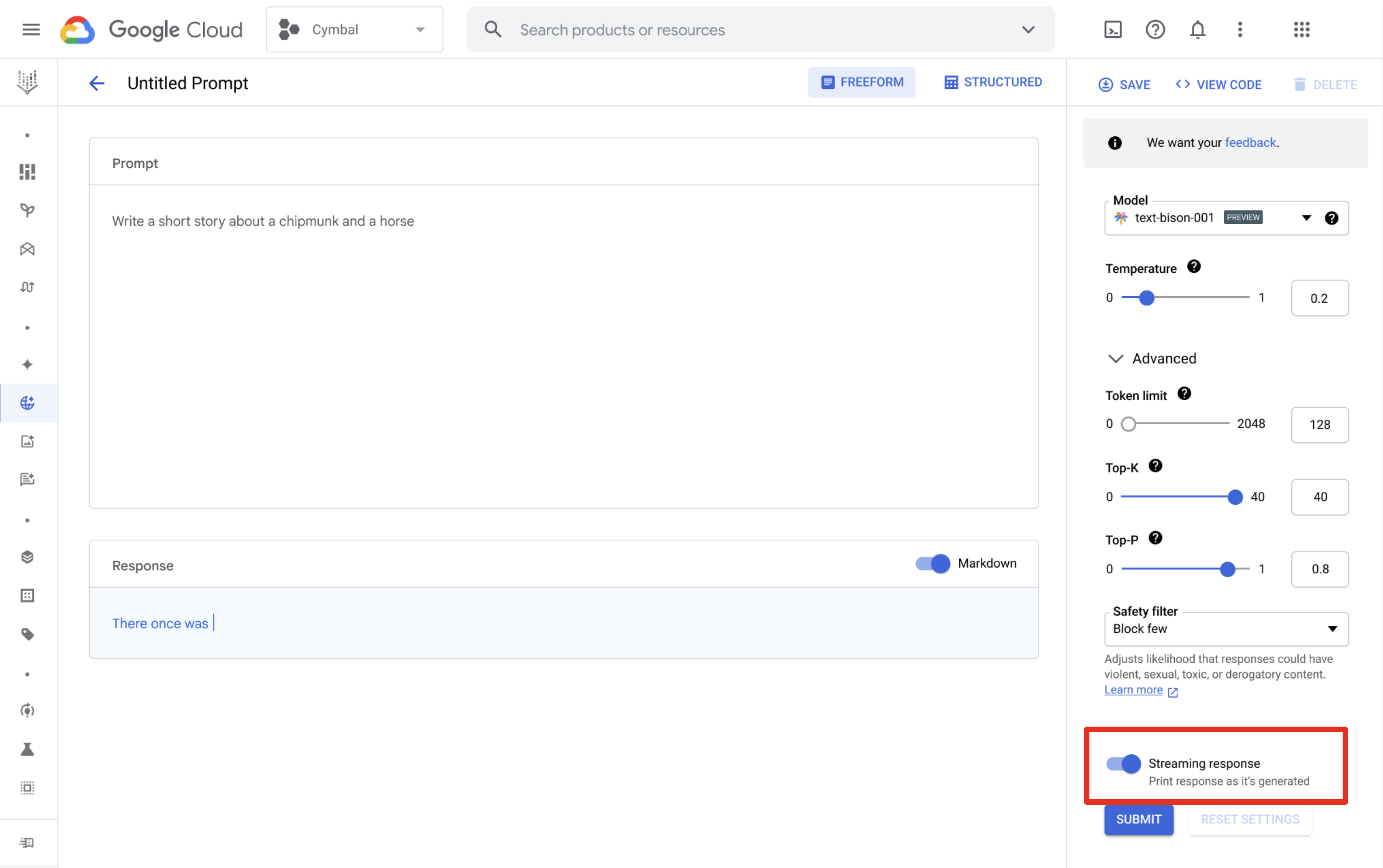
您可以使用 Vertex AI Studio 来设计和运行提示并接收流式传输的响应。从提示设计页面中,点击流式传输响应按钮以启用流式传输。
支持的语言
| 语言代码 | 语言 |
|---|---|
en |
英语 |
es |
西班牙语 |
pt |
葡萄牙语 |
fr |
法语 |
it |
意大利语 |
de |
德语 |
ja |
日语 |
ko |
韩语 |
hi |
印地语 |
zh |
中文 |
id |
印度尼西亚语 |
示例
您可以使用以下方式之一调用流式传输 API:
具有服务器发送的事件 (SSE) 的 REST API
以下示例中使用的模型类型中的参数有所不同:
文本
当前支持的模型是 text-bison 和 text-unicorn。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
响应是服务器发送的事件消息。
data: {"outputs": [{"structVal": {"content": {"stringVal": [RESPONSE]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"structVal": {"citations": {}}}}}]}
聊天
当前支持的模型是 chat-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
响应是服务器发送的事件消息。
data: {"outputs": [{"structVal": {"candidates": {"listVal": [{"structVal": {"author": {"stringVal": [AUTHOR]},"content": {"stringVal": [RESPONSE]}}}]},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}}}}]}
编码
当前支持的模型是 code-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
响应是服务器发送的事件消息。
data: {"outputs": [{"structVal": {"citationMetadata": {"structVal": {"citations": {}}},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"content": {"stringVal": [RESPONSE]}}}]}
代码聊天
当前支持的模型是 codechat-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
响应是服务器发送的事件消息。
data: {"outputs": [{"structVal": {"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"candidates": {"listVal": [{"structVal": {"content": {"stringVal": [RESPONSE]},"author": {"stringVal": [AUTHOR]}}}]}}}]}
REST API
以下示例中使用的模型类型中的参数有所不同:
文本
当前支持的模型是 text-bison 和 text-unicorn。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
{
"outputs": [
{
"structVal": {
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
聊天
当前支持的模型是 chat-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
编码
当前支持的模型是 code-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
{
"outputs": [
{
"structVal": {
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
代码聊天
当前支持的模型是 codechat-bison。请参阅可用的版本。
请求
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
响应
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Vertex AI SDK for Python
如需了解如何安装 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。
文本
import vertexai
from vertexai.language_models import TextGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Text Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
text_generation_model = TextGenerationModel.from_pretrained("text-bison")
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.8, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
responses = text_generation_model.predict_streaming(prompt="Give me ten interview questions for the role of program manager.", **parameters)
for response in responses:
`print(response)`
聊天
import vertexai
from vertexai.language_models import ChatModel, InputOutputTextPair
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
chat = chat_model.start_chat(
context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
examples=[
InputOutputTextPair(
input_text="How many moons does Mars have?",
output_text="The planet Mars has two moons, Phobos and Deimos.",
),
],
)
responses = chat.send_message_streaming(
message="How many planets are there in the solar system?", **parameters)
for response in responses:
`print(response)`
编码
import vertexai
from vertexai.language_models import CodeGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
code_model = CodeGenerationModel.from_pretrained("code-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
}
responses = code_model.predict_streaming(
prefix="Write a function that checks if a year is a leap year.", **parameters)
for response in responses:
`print(response)`
代码聊天
import vertexai
from vertexai.language_models import CodeChatModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
codechat_model = CodeChatModel.from_pretrained("codechat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 1024, # Token limit determines the maximum amount of text output.
}
codechat = codechat_model.start_chat()
responses = codechat.send_message_streaming(
message="Please help write a function to calculate the min of two numbers", **parameters)
for response in responses:
`print(response)`
可用的客户端库
您可以使用以下客户端库之一来流式传输响应:
- Python
- Node.js
- Java
- Go
- C#
如需使用 REST API 查看示例代码请求和响应,请参阅使用 REST API 的示例。
如需使用 Vertex AI SDK for Python 查看示例代码请求和响应,请参阅使用 Vertex AI SDK for Python 的示例。
Responsible AI
响应式人工智能 (RAI) 过滤器会在模型生成流式传输输出时进行扫描。如果检测到违规行为,则过滤器会屏蔽违规的输出词元,并在 safetyAttributes 下返回具有被阻止标志的输出,这会终止流式传输。
后续步骤
- 了解如何设计文本提示和文字聊天提示。
- 了解如何在 Vertex AI Studio 中测试提示。
- 了解文本嵌入。
- 尝试调整语言基础模型。
- 了解 Responsible AI 最佳实践和 Vertex AI 的安全过滤条件。