La transmisión implica recibir respuestas a las instrucciones a medida que se generan. Es decir, en cuanto el modelo genere tokens de salida, se enviarán los tokens de salida.
Puedes realizar solicitudes de transmisión al modelo grande de lenguaje (LLM) de Vertex AI con los siguientes recursos:
- La API de REST con eventos enviados por el servidor (SSE) de Vertex AI
- La API de REST de Vertex AI
- El SDK de Vertex AI para Python
- Una biblioteca cliente
Las APIs de transmisión y las que no transmiten usan los mismos parámetros, y no hay diferencias en los precios y las cuotas.
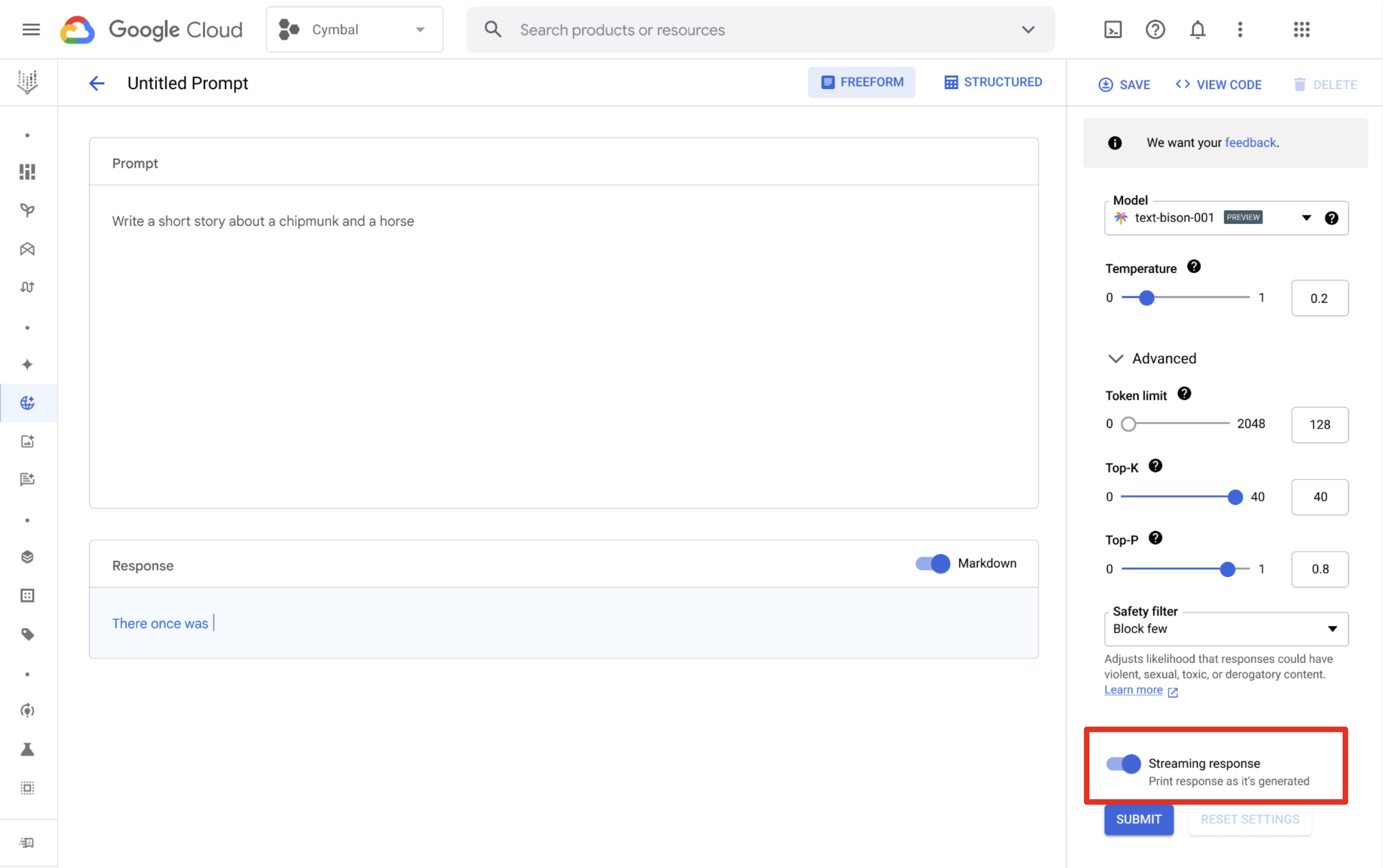
Vertex AI Studio
Puedes usar Vertex AI Studio para diseñar y ejecutar instrucciones y recibir respuestas transmitidas. En la página de diseño de instrucciones, haz clic en el botón Respuesta de transmisión para habilitar la transmisión.
Idiomas admitidos
| Código de idioma | Idioma |
|---|---|
en |
Inglés |
es |
Español |
pt |
Portugués |
fr |
Francés |
it |
Italiano |
de |
Alemán |
ja |
Japonés |
ko |
Coreano |
hi |
Hindi |
zh |
Chino |
id |
Indonesio |
Ejemplos
Puedes llamar a la API de transmisión mediante una de las siguientes opciones:
API de REST con eventos enviados por el servidor (SSE)
Los parámetros son diferentes en todos los tipos de modelos que se usan en los siguientes ejemplos:
Texto
Los modelos compatibles actuales son text-bison y text-unicorn. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
Las respuestas son mensajes de evento enviados por el servidor.
data: {"outputs": [{"structVal": {"content": {"stringVal": [RESPONSE]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"structVal": {"citations": {}}}}}]}
Chat
El modelo admitido actual es chat-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
Las respuestas son mensajes de evento enviados por el servidor.
data: {"outputs": [{"structVal": {"candidates": {"listVal": [{"structVal": {"author": {"stringVal": [AUTHOR]},"content": {"stringVal": [RESPONSE]}}}]},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}}}}]}
Código
El modelo admitido actual es code-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
Las respuestas son mensajes de evento enviados por el servidor.
data: {"outputs": [{"structVal": {"citationMetadata": {"structVal": {"citations": {}}},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"content": {"stringVal": [RESPONSE]}}}]}
Chat de código
El modelo admitido actual es codechat-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
Las respuestas son mensajes de evento enviados por el servidor.
data: {"outputs": [{"structVal": {"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"candidates": {"listVal": [{"structVal": {"content": {"stringVal": [RESPONSE]},"author": {"stringVal": [AUTHOR]}}}]}}}]}
API de REST
Los parámetros son diferentes en todos los tipos de modelos que se usan en los siguientes ejemplos:
Texto
Los modelos compatibles actuales son text-bison y text-unicorn. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
{
"outputs": [
{
"structVal": {
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Chat
El modelo admitido actual es chat-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Código
El modelo admitido actual es code-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
{
"outputs": [
{
"structVal": {
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Chat de código
El modelo admitido actual es codechat-bison. Consulta las versiones disponibles.
Solicitud
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respuesta
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
SDK de Vertex AI para Python
Si deseas obtener información para instalar el SDK de Vertex AI para Python, consulta Instala el SDK de Vertex AI para Python.
Texto
import vertexai
from vertexai.language_models import TextGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Text Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
text_generation_model = TextGenerationModel.from_pretrained("text-bison")
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.8, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
responses = text_generation_model.predict_streaming(prompt="Give me ten interview questions for the role of program manager.", **parameters)
for response in responses:
`print(response)`
Chat
import vertexai
from vertexai.language_models import ChatModel, InputOutputTextPair
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
chat = chat_model.start_chat(
context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
examples=[
InputOutputTextPair(
input_text="How many moons does Mars have?",
output_text="The planet Mars has two moons, Phobos and Deimos.",
),
],
)
responses = chat.send_message_streaming(
message="How many planets are there in the solar system?", **parameters)
for response in responses:
`print(response)`
Código
import vertexai
from vertexai.language_models import CodeGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
code_model = CodeGenerationModel.from_pretrained("code-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
}
responses = code_model.predict_streaming(
prefix="Write a function that checks if a year is a leap year.", **parameters)
for response in responses:
`print(response)`
Chat de código
import vertexai
from vertexai.language_models import CodeChatModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
codechat_model = CodeChatModel.from_pretrained("codechat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 1024, # Token limit determines the maximum amount of text output.
}
codechat = codechat_model.start_chat()
responses = codechat.send_message_streaming(
message="Please help write a function to calculate the min of two numbers", **parameters)
for response in responses:
`print(response)`
Bibliotecas cliente disponibles
Puedes usar una de las siguientes bibliotecas cliente para transmitir respuestas:
- Python
- Node.js
- Java
- Go
- C#
Para ver solicitudes y respuestas de código de muestra con la API de REST, consulta Ejemplos que usan la API de REST.
Si deseas ver las solicitudes y respuestas de código de muestra con el SDK de Vertex AI para Python, consulta Ejemplos que usan el SDK de Vertex AI para Python.
IA responsable
Los filtros de inteligencia artificial responsables (RAI) analizan el resultado de la transmisión a medida que el modelo lo genera. Si se detecta una infracción, los filtros bloquean los tokens de salida infractores y muestran un resultado con una marca bloqueada en safetyAttributes, que finaliza la transmisión.
¿Qué sigue?
- Obtén información sobre cómo diseñar instrucciones de texto e instrucciones de chat de texto.
- Aprende a probar los mensajes en Vertex AI Studio.
- Obtén más información sobre las incorporaciones de texto.
- Intenta ajustar un modelo base de lenguaje.
- Obtén información sobre las prácticas recomendadas de IA responsable y los filtros de seguridad de Vertex AI.