스트리밍은 생성되는 프롬프트에 대한 응답을 수신합니다.즉, 모델이 출력 토큰을 생성하는 즉시 출력 토큰이 전송됩니다.
다음을 사용하여 Vertex AI 대규모 언어 모델(LLM)에 스트리밍 요청을 보낼 수 있습니다.
스트리밍 및 비 스트리밍 API는 같은 매개변수를 사용하며 가격 책정과 할당량에 차이가 없습니다.
Vertex AI Studio
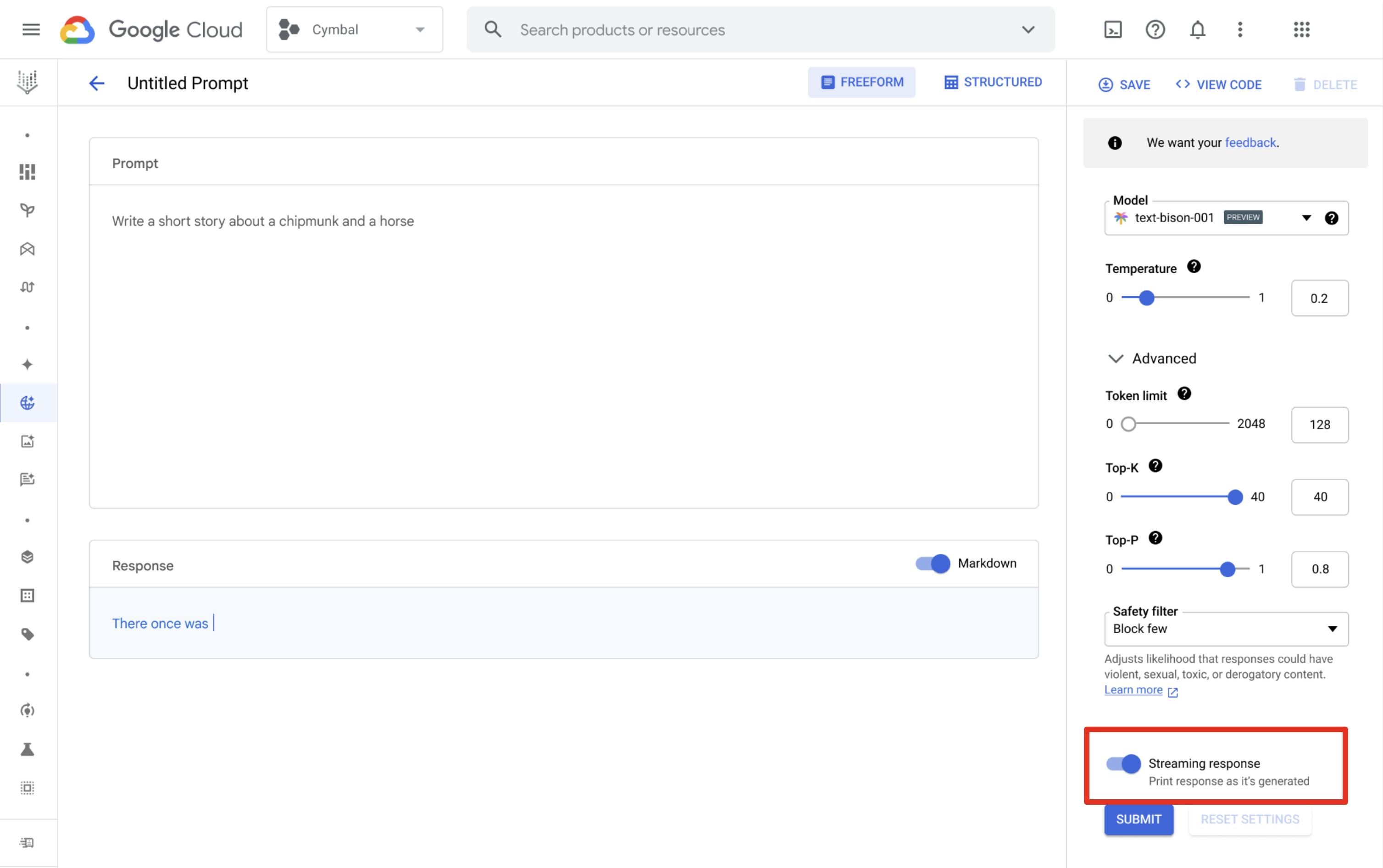
Vertex AI Studio를 사용하여 프롬프트를 설계 및 실행하고 스트리밍 응답을 받을 수 있습니다. 프롬프트 설계 페이지에서 스트리밍 응답 버튼을 클릭하여 스트리밍을 사용 설정합니다.
지원 언어
| 언어 코드 | 언어 |
|---|---|
en |
영어 |
es |
스페인어 |
pt |
포르투갈어 |
fr |
프랑스어 |
it |
이탈리아어 |
de |
독일어 |
ja |
일본어 |
ko |
한국어 |
hi |
힌디어 |
zh |
중국어 |
id |
인도네시아어 |
예시
다음 중 하나를 사용하여 Streaming API를 호출할 수 있습니다.
서버 전송 이벤트(SSE)를 사용하는 REST API
매개변수는 다음 예시에 사용된 모델 유형마다 다릅니다.
텍스트
현재 지원되는 모델은 text-bison 및 text-unicorn입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
응답은 서버에서 전송된 이벤트 메시지입니다.
data: {"outputs": [{"structVal": {"content": {"stringVal": [RESPONSE]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"structVal": {"citations": {}}}}}]}
채팅
현재 지원되는 모델은 chat-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
응답은 서버에서 전송된 이벤트 메시지입니다.
data: {"outputs": [{"structVal": {"candidates": {"listVal": [{"structVal": {"author": {"stringVal": [AUTHOR]},"content": {"stringVal": [RESPONSE]}}}]},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}}}}]}
코드
현재 지원되는 모델은 code-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
응답은 서버에서 전송된 이벤트 메시지입니다.
data: {"outputs": [{"structVal": {"citationMetadata": {"structVal": {"citations": {}}},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"content": {"stringVal": [RESPONSE]}}}]}
코드 채팅
현재 지원되는 모델은 codechat-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
응답은 서버에서 전송된 이벤트 메시지입니다.
data: {"outputs": [{"structVal": {"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"candidates": {"listVal": [{"structVal": {"content": {"stringVal": [RESPONSE]},"author": {"stringVal": [AUTHOR]}}}]}}}]}
REST API
매개변수는 다음 예시에 사용된 모델 유형마다 다릅니다.
텍스트
현재 지원되는 모델은 text-bison 및 text-unicorn입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
{
"outputs": [
{
"structVal": {
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
채팅
현재 지원되는 모델은 chat-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
코드
현재 지원되는 모델은 code-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
{
"outputs": [
{
"structVal": {
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
코드 채팅
현재 지원되는 모델은 codechat-bison입니다. 사용 가능한 버전을 참조하세요.
요청
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
응답
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Python용 Vertex AI SDK
Python용 Vertex AI SDK 설치에 대한 자세한 내용은 Python용 Vertex AI SDK 설치를 참조하세요.
텍스트
import vertexai
from vertexai.language_models import TextGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Text Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
text_generation_model = TextGenerationModel.from_pretrained("text-bison")
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.8, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
responses = text_generation_model.predict_streaming(prompt="Give me ten interview questions for the role of program manager.", **parameters)
for response in responses:
`print(response)`
채팅
import vertexai
from vertexai.language_models import ChatModel, InputOutputTextPair
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
chat = chat_model.start_chat(
context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
examples=[
InputOutputTextPair(
input_text="How many moons does Mars have?",
output_text="The planet Mars has two moons, Phobos and Deimos.",
),
],
)
responses = chat.send_message_streaming(
message="How many planets are there in the solar system?", **parameters)
for response in responses:
`print(response)`
코드
import vertexai
from vertexai.language_models import CodeGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
code_model = CodeGenerationModel.from_pretrained("code-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
}
responses = code_model.predict_streaming(
prefix="Write a function that checks if a year is a leap year.", **parameters)
for response in responses:
`print(response)`
코드 채팅
import vertexai
from vertexai.language_models import CodeChatModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
codechat_model = CodeChatModel.from_pretrained("codechat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 1024, # Token limit determines the maximum amount of text output.
}
codechat = codechat_model.start_chat()
responses = codechat.send_message_streaming(
message="Please help write a function to calculate the min of two numbers", **parameters)
for response in responses:
`print(response)`
사용 가능한 클라이언트 라이브러리
다음 클라이언트 라이브러리 중 하나를 사용하여 응답을 스트리밍할 수 있습니다.
- Python
- Node.js
- 자바
- Go
- C#
REST API를 사용하여 샘플 코드 요청 및 응답을 보려면 REST API 사용 예시를 참조하세요.
Python용 Vertex AI SDK를 사용하여 샘플 코드 요청 및 응답을 보려면 Python용 Vertex AI SDK 사용 예시를 참조하세요.
책임감 있는 AI
책임감 있는 인공 지능(RAI) 필터는 모델에서 출력을 생성할 때 스트리밍 출력을 스캔합니다. 위반이 감지되면 필터는 잘못된 출력 토큰을 차단하고 safetyAttributes 아래에서 차단된 플래그가 있는 출력을 반환하여 스트림을 종료합니다.
다음 단계
- 텍스트 프롬프트 및 텍스트 채팅 프롬프트 설계 알아보기
- Vertex AI Studio에서 프롬프트 테스트 방법 알아보기
- 텍스트 임베딩 알아보기
- 언어 기반 모델 조정 사용해 보기
- 책임감 있는 AI 권장사항 및 Vertex AI 안전 필터 알아보기