可配置的安全过滤器
安全属性置信度和严重程度评分
通过 Vertex AI PaLM API 处理的内容会根据安全属性列表进行评估,列表包括“有害类别”和可能被视为敏感的主题。
每个安全属性的相关置信度得分区间为 0.0 和 1.0,四舍五入到小数点后一位,反映了输入或响应属于给定类别的可能性。
为这四种安全属性(骚扰、仇恨言论、危险内容和露骨色情内容)分配的安全评分(严重级别)和严重级别(范围为 0.0 到 1.0),舍入到一个小数位。这些评分和得分反映了属于给定类别的内容的预测严重程度。
示例响应
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
注意:响应中省略了四舍五入为 0.0 的得分的类别。该示例仅作说明之用。
被屏蔽时的示例响应
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
安全属性说明
| 安全属性 | 说明 |
|---|---|
| 诋毁性内容 | 针对身份和/或受保护属性的负面或有害评论。 |
| 有害内容 | 粗鲁、无礼或亵渎性的内容。 |
| 色情内容 | 包含对性行为或其他淫秽内容的引用。 |
| 暴力内容 | 描述描绘针对个人或团体的暴力行为的场景,或一般性血腥描述。 |
| 侮辱内容 | 对一个人或一群人的侮辱性、煽动性或负面评论。 |
| 脏话 | 下流或粗俗的语言,例如咒骂。 |
| 死亡、伤害和悲剧 | 人类死亡、不幸、事故、灾难和自残。 |
| 枪支与武器 | 提及刀具、枪支、个人武器以及配件(例如弹药、枪套等)的内容。 |
| 公共安全 | 提供救济和确保公共安全的服务和组织。 |
| 健康状况 | 人类健康,包括健康状况、疾病和障碍;医疗治疗、药物、疫苗接种和医疗实践;治疗资源(包括支持群体)。 |
| 宗教与信仰 | 处理超自然法则和存在的可能性的信仰体系;宗教、信仰、精神实践、教堂和礼拜场所。包括占星术和神秘学。 |
| 非法药物 | 娱乐性和非法药物;吸毒用具和种植、药店等。包括通常用于消遣的药物的药用(例如大麻)。 |
| 战争与冲突 | 涉及大量人员的战争、军事冲突和重大肢体冲突。包括对军事服务的讨论,即使与战争或冲突没有直接关系。 |
| 金融 | 消费者和企业金融服务,例如银行业务、贷款、信贷、投资、保险等。 |
| 政治 | 政治新闻和媒体;关于社会、政府和公共政策的讨论。 |
| 法律 | 与法律相关的内容,包括:律师事务所、法律信息、主要法律材料、律师法律服务、法律出版物和技术、专家证人、诉讼顾问和其他法律服务提供商。 |
具有安全评分的安全属性
| 安全属性 | 定义 | 级别 |
|---|---|---|
| 仇恨言论 | 针对身份和/或受保护属性的负面或有害评论。 | 高、中、低、可忽略 |
| 骚扰 | 针对其他人的恶意、恐吓、欺凌或辱骂性评论。 | 高、中、低、可忽略 |
| 露骨色情内容 | 包含对性行为或其他淫秽内容的引用。 | 高、中、低、可忽略 |
| 危险内容 | 宣传或允许访问有害商品、服务和活动。 | 高、中、低、可忽略 |
安全阈值
以下安全属性设有安全阈值:
- 仇恨言论
- 骚扰
- 露骨色情内容
- 危险内容
Google 会阻止超出这些安全属性的指定严重程度得分的模型响应。如需请求修改安全阈值,请与您的 Google Cloud 客户支持团队联系。
测试置信度和严重程度阈值
您可以测试 Google 的安全过滤器,并定义适合您的企业的置信度阈值。通过使用这些阈值,您可以采取全面的措施来检测违反 Google 使用政策或服务条款的内容,并采取适当的措施。
置信度得分只是预测值,您不应依赖得分来获取可靠性或准确性。Google 不负责解读或使用这些得分来做出业务决策。
重要提示:可能性与严重性
除了具有安全评分的四种安全属性外,PaLM API 安全过滤器的置信度分数均基于内容不安全的概率而非严重程度。考虑这一点很重要,因为某些内容不安全的可能性很小,即使危害的严重程度可能仍然很高。例如,比较句子:
- 机器人打了我一拳。
- 机器人把我砍伤了。
第 1 句可能导致不安全的可能性更高,但您可能认为第 2 句在暴力方面的严重性更高。
考虑到这一点,客户必须仔细测试并考虑需要哪些级别的屏蔽来支持其关键应用场景,同时最大限度地减少对最终用户的影响。
Vertex AI Studio 中的安全设置
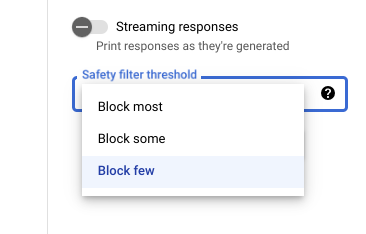
借助可调整的安全过滤器阈值,您可以调整您希望看到可能有害的响应的可能性。模型响应会因包含骚扰、仇恨言论、危险内容或露骨色情内容的可能性而被屏蔽。安全过滤器设置位于 Vertex AI Studio 中提示框的右侧。您可以从三个选项中进行选择:block most、block some 和 block few。
引用过滤器
我们的生成式代码功能旨在生成原创内容,而不是大量复制现有内容。我们对自己的系统进行了精心设计,以尽量避免发生这种情况,并且我们将不断改进这些系统的运作方式。如果这些功能确实直接引用了某个网页上的大量内容,则会注明相应内容来源于该页面。
有时,我们可能会在多个网页上发现相同的内容,在这种情况下,我们会试着将您引至热门来源。如果此类功能引用了代码库,则引用中还可能提及适用的开源许可。您须负责遵守所有许可要求。
如需了解引用过滤器的元数据,请参阅过滤器 API 参考文档。
安全错误
安全错误代码是三位数代码,表示提示或响应被屏蔽的原因。第一个数字是前缀,指示代码是应用于提示还是响应,其余数字用于标识提示或响应被屏蔽的原因。例如,错误代码 251 指示响应因来自模型的响应中有仇恨言论内容的问题而被屏蔽。
一个响应中可能会返回多个错误代码。
如果您遇到来自模型的响应中的内容被屏蔽的错误(前缀 = 2,例如 250),请调整请求中的 temperature 设置。这有助于生成一组不同的响应,并且被屏蔽的可能性降低。
错误代码前缀
错误代码前缀是错误代码的第一位数字。
| 1 | 错误代码适用于发送到模型的提示。 |
| 2 | 错误代码适用于模型的回答。 |
错误代码原因
错误代码原因是错误代码的第二位和第三位数字。
以 3 或 4 开头的错误代码原因指示提示或回答由于已达到违反安全属性的置信度阈值而被屏蔽。
以 5 开头的错误代码指示在其中发现了不安全内容的提示或响应。
| 10 | 响应因质量问题或影响引用元数据的参数设置而被屏蔽。这仅适用于来自模型的响应。即 引用检查工具可识别质量问题或源自参数设置的问题。请尝试增大 如需了解更多信息,请参阅引用过滤器。 |
| 20 | 所提供的语言或返回的语言不受支持。如需查看受支持的语言列表,请参阅语言支持。 |
| 30 | 提示或响应因系统认为可能有害而被屏蔽。 术语屏蔽名单中包含某个术语。改述提示。 |
| 31 | 内容可能包含敏感的个人身份信息 (SPII)。改述提示。 |
| 40 | 提示或响应因系统认为可能有害而被屏蔽。 相应内容违反了 SafeSearch 设置。改述提示。 |
| 50 | 提示或响应已被屏蔽,因为其中可能包含露骨色情内容。 改述提示。 |
| 51 | 提示或响应已被屏蔽,因为它可能包含仇恨言论内容。改述提示。 |
| 52 | 提示或响应因可能包含骚扰内容而被屏蔽。改述提示。 |
| 53 | 提示或响应因可能包含危险内容而被屏蔽。改述提示。 |
| 54 | 提示或响应因可能包含恶意内容而被屏蔽。改述提示。 |
| 00 | 原因未知。改述提示。 |
后续步骤
- 详细了解 Responsible AI。
- 了解数据治理。