Filtros de segurança configuráveis
Pontuação de gravidade e confiança do atributo de segurança
O conteúdo processado pela API PaLM da Vertex AI é avaliado com base em uma lista de atributos de segurança, que incluem "categorias prejudiciais" e tópicos que podem ser considerados sensíveis.
Cada atributo de segurança tem uma pontuação de confiança associada entre 0,0 e 1,0, arredondada em uma casa decimal, refletindo a probabilidade de uma entrada ou resposta pertencer a uma determinada categoria.
Quatro desses atributos de segurança (assédio, discurso de ódio, conteúdo perigoso e sexualmente explícito) recebem uma classificação de segurança (nível de gravidade) e uma pontuação de gravidade que varia de 0,0 a 1,0, arredondada para uma casa decimal. Essas classificações e pontuações refletem a gravidade prevista do conteúdo que pertence a uma determinada categoria.
Exemplo de resposta
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
Observação: as categorias com pontuação que arredonda para 0,0 são omitidas na resposta. O exemplo de resposta é apenas ilustrativo.
Exemplo de resposta quando bloqueado
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
Descrições dos atributos de segurança
| Atributo de segurança | Descrição |
|---|---|
| Depreciativo | Comentários negativos ou nocivos voltados à identidade e/ou atributos protegidos. |
| Tóxico | Conteúdo grosseiro, desrespeitoso ou linguagem obscena. |
| Conteúdo sexual | Contém referências a atos sexuais ou outro conteúdo sexual. |
| Conteúdo violento | Descreve cenários que retratam violência contra um indivíduo ou grupo ou descrições gerais de sangue em excesso. |
| Ofensivo | Comentários ofensivos, inflamatórios ou negativos sobre uma pessoa ou um grupo. |
| Linguagem obscena | Linguagem obscena ou vulgar, como xingamentos. |
| Morte, dano e tragédia | Mortes humanas, tragédias, acidentes, desastres e automutilação. |
| Armas de fogo e outras armas | Conteúdo que mencione facas, revólveres, armas pessoais e acessórios, como munições, coldres etc. |
| Segurança pública | Serviços e organizações que prestam assistência e garantem a segurança pública. |
| Saúde | Saúde humana, incluindo: condições de saúde, doenças e distúrbios, terapias médicas, medicamentos, vacinação, práticas médicas e recursos para cicatrização, incluindo grupos de suporte. |
| Religião e crenças | Sistemas de crenças que lidam com a possibilidade de leis e seres sobrenaturais; religião, fé, crença, prática espiritual, igrejas e locais de culto. Inclui astrologia e ocultismo. |
| Drogas ilícitas | Drogas recreativas e ilícitas; acessórios para o consumo e o cultivo, headshops etc. Inclui o uso medicinal de drogas normalmente usadas recreativamente (por exemplo, maconha). |
| Guerra e conflito | Guerra, conflitos militares e grandes conflitos físicos envolvendo um grande número de pessoas. Inclui a discussão sobre serviços militares, mesmo que não esteja diretamente relacionada a uma guerra ou conflito. |
| Finanças | Serviços financeiros para o consumidor e empresarial, como bancos, empréstimos, crédito, investimentos, seguros etc. |
| Política | Notícias e mídia política; discussões sobre políticas sociais, governamentais e públicas. |
| Jurídico | Conteúdo relacionado à lei, incluindo escritórios de advocacia, informações legais, materiais jurídicos em geral, serviços jurídicos, publicações e tecnologias, testemunhas especializadas, consultores jurídicos e outros provedores de serviços jurídicos. |
Atributos de segurança com classificações de segurança
| Atributo de segurança | Definição | Níveis |
|---|---|---|
| Discurso de ódio | Comentários negativos ou nocivos voltados à identidade e/ou atributos protegidos. | Alta, média, baixa, insignificante |
| Assédio | Comentários maliciosos, intimidadores, abusivos ou violentos direcionados a outra pessoa. | Alta, média, baixa, insignificante |
| Sexualmente explícito | Contém referências a atos sexuais ou outro conteúdo sexual. | Alta, média, baixa, insignificante |
| Conteúdo perigoso | Promove ou permite o acesso a produtos, serviços e atividades prejudiciais. | Alta, média, baixa, insignificante |
Limites de segurança
Existem limites de segurança para os seguintes atributos:
- Discurso de ódio
- Assédio
- Sexualmente explícito
- Conteúdo perigoso
O Google bloqueia as respostas do modelo que excedem as pontuações de gravidade designadas para esses atributos de segurança. Para solicitar a capacidade de modificar um limite de segurança, entre em contato com a Google Cloud equipe de conta.
Como testar seus limites de confiança e gravidade
É possível testar os filtros de segurança do Google e definir limites de confiança ideais para sua empresa. Ao usar esses limites, você pode tomar medidas abrangentes para detectar conteúdo que viole as políticas de uso ou os termos de serviço do Google e tomar as medidas apropriadas.
As pontuações de confiança são apenas previsões, e você não deve depender da confiabilidade ou precisão delas. O Google não é responsável por interpretar ou usar essas pontuações para decisões de negócios.
Importante: probabilidade e gravidade
Com exceção dos quatro atributos de segurança com classificações de segurança, as pontuações de confiança dos filtros de segurança da API PaLM são baseadas na probabilidade de o conteúdo não ser seguro, e não na gravidade. É importante considerar isso, porque alguns conteúdos podem ter baixa probabilidade de não serem seguros, mesmo que a gravidade dos danos ainda seja alta. Por exemplo, comparando as frases:
- O robô me socou.
- O robô me cortou.
A frase 1 pode causar uma probabilidade maior de não ser segura, mas você pode considerar a frase 2 uma gravidade maior em termos de violência.
Por isso, é importante que os clientes façam teste criteriosos e considerem o nível apropriado de bloqueio necessário para oferecer suporte aos principais casos de uso e minimizar os danos aos usuários finais.
Configurações de segurança no Vertex AI Studio
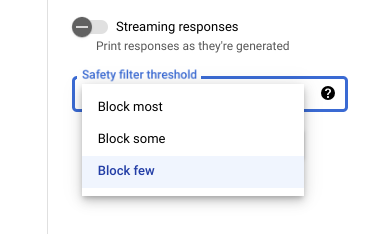
Com o limite de filtro de segurança ajustável, você pode ajustar a probabilidade de ver respostas que podem ser prejudiciais. As respostas do modelo são bloqueadas com base na probabilidade de conterem assédio, discurso de ódio, conteúdo perigoso ou conteúdo sexualmente explícito. A configuração do filtro de segurança está localizada à direita do campo de comando no Vertex AI Studio. É possível escolher entre três opções: block most, block some e block few.
Filtro de citações
O objetivo dos nossos recursos de código generativo é produzir conteúdo original, não replicar conteúdo que já existe na íntegra. Projetamos nossos sistemas para limitar as chances de isso acontecer e melhorar continuamente o funcionamento deles. Se esses recursos citarem na íntegra o conteúdo de uma página da Web, isso será especificado na citação.
Às vezes, o mesmo conteúdo pode ser encontrado em várias páginas da Web. Nesse caso, tentaremos direcionar para uma fonte bem conhecida. No caso de citações de repositórios de código, a citação também pode referenciar uma licença de código aberto aplicável. É sua responsabilidade obedecer aos requisitos de licença.
Para saber mais sobre os metadados do filtro de citações, consulte a referência da API Citation.
Erros de segurança
Os códigos de erro de segurança são códigos de três dígitos que representam o motivo pelo qual uma
solicitação ou resposta foi bloqueada. O primeiro dígito é um prefixo que indica se o código se aplica ao comando ou à resposta, e os dígitos restantes identificam o motivo do bloqueio.
Por exemplo, o código do erro 251 indica que a resposta foi bloqueada devido a um problema com conteúdo de discurso de ódio na resposta do modelo.
Vários códigos de erro podem ser retornados em uma única resposta.
Se você encontrar erros que bloqueiam o conteúdo na sua resposta do modelo
(prefixo = 2, por exemplo, 250),
ajuste a configuração temperature na sua solicitação. Isso ajuda a gerar um
conjunto diferente de respostas com menor chance de bloqueio.
Prefixo do código de erro
O primeiro dígito é o prefixo do código de erro.
| 1 | O código de erro se aplica ao comando enviado ao modelo. |
| 2 | O código de erro se aplica à resposta do modelo. |
Motivo do código de erro
O segundo e o terceiro dígitos constituem o motivo do código de erro.
Os motivos dos códigos de erro que começam com 3 ou 4 indicam que os comandos ou respostas foram bloqueadas porque o limite de confiança para uma violação de atributo de segurança foi alcançado.
Os motivos dos códigos de erro que começam com 5 indicam comandos ou respostas em que
conteúdo não seguro foi encontrado.
| 10 | A resposta foi bloqueada devido a um problema de qualidade ou uma configuração de parâmetro que afeta os metadados da citação. Isso se aplica apenas às respostas do modelo. Ou seja, O verificador de citações identifica problemas de qualidade ou decorrentes de uma
configuração de parâmetro. Tente aumentar os parâmetros Para mais informações, consulte Filtro de citações. |
| 20 | O idioma fornecido ou retornado não é aceito. Confira a lista de idiomas compatíveis emSuporte ao idioma. |
| 30 | A solicitação ou resposta foi bloqueada porque foi considerada potencialmente perigosa. Um termo está incluído na lista de bloqueio de terminologia. Reformule seu comando. |
| 31 | O conteúdo pode incluir informações sensíveis de identificação pessoal (SPII). Reformule seu comando. |
| 40 | A solicitação ou resposta foi bloqueada porque foi considerada potencialmente perigosa. O conteúdo viola as configurações do SafeSearch. Reformule seu comando. |
| 50 | O comando ou a resposta foi bloqueado porque pode conter conteúdo sexualmente explícito. Reformule seu comando. |
| 51 | O comando ou a resposta foi bloqueado porque pode conter conteúdo de discurso de ódio. Reformule seu comando. |
| 52 | O comando ou a resposta foi bloqueado porque pode conter conteúdo de assédio. Reformule seu comando. |
| 53 | O comando ou a resposta foi bloqueado porque pode conter conteúdo violento. Reformule seu comando. |
| 54 | O comando ou a resposta foi bloqueada porque pode apresentar conteúdo tóxico. Reformule seu comando. |
| 00 | Motivo desconhecido. Reformule seu comando. |
A seguir
- Saiba mais sobre a IA responsável.
- Saiba mais sobre governança de dados.