Introdução ao conversor de inferência da Cloud TPU v5e
Introdução
O conversor de inferência da Cloud TPU prepara e otimiza um modelo do TensorFlow 2 (TF2) para inferência de TPU. O conversor é executado em um shell local ou de VM TPU. O shell da VM de TPU é recomendado porque vem pré-instalado com as ferramentas de linha de comando necessárias para o conversor. Ele usa um SavedModel exportado e executa as seguintes etapas:
- Conversão de TPU: adiciona
TPUPartitionedCalle outras operações de TPU ao modelo para que ele possa ser servido na TPU. Por padrão, um modelo exportado para inferência não tem essas operações e não pode ser veiculado na TPU, mesmo que tenha sido treinado nela. - Agrupamento: adiciona operações de agrupamento ao modelo para permitir o agrupamento no gráfico e melhorar a capacidade.
- Conversão de BFloat16: converte o formato de dados do modelo de
float32parabfloat16para melhorar o desempenho computacional e reduzir o uso da memória de alta largura de banda (HBM, na sigla em inglês) na TPU. - Otimização de forma de E/S: otimiza as formas de tensor para dados transferidos entre a CPU e a TPU para melhorar a utilização da largura de banda.
Ao exportar um modelo, os usuários criam aliases de função para todas as funções que gostariam de executar na TPU. Elas transmitem essas funções ao Conversor, que as coloca na TPU e as otimiza.
O conversor de inferência do Cloud TPU está disponível como uma imagem do Docker que pode ser executada em qualquer ambiente com o Docker instalado.
Tempo estimado para concluir as etapas acima: ~20 a 30 minutos
Pré-requisitos
- O modelo precisa ser do TF2 e exportado no formato SavedModel.
- O modelo precisa ter um alias de função para a função TPU. Consulte o
exemplo de código
para saber como fazer isso. Os exemplos a seguir usam
tpu_funccomo o alias da função TPU. - Verifique se a CPU da máquina oferece suporte a instruções de Extensões vetoriais avançadas (AVX, na sigla em inglês).
A biblioteca Tensorflow (a dependência do conversor de inferência da Cloud TPU) é compilada para usar instruções AVX.
A maioria das CPUs
tem suporte para AVX.
- Você pode executar
lscpu | grep avxpara verificar se o conjunto de instruções AVX é compatível.
- Você pode executar
Antes de começar
Antes de começar a configuração, faça o seguinte:
Criar um projeto: no console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Cloud.
Configurar uma VM de TPU: crie uma nova VM de TPU usando o console do Google Cloud ou
gcloud, ou use uma VM de TPU existente para executar a inferência com o modelo convertido na VM de TPU.- Verifique se a imagem da VM da TPU é baseada no TensorFlow. Por exemplo,
--version=tpu-vm-tf-2.11.0 - O modelo convertido será carregado e disponibilizado nessa VM do TPU.
- Verifique se a imagem da VM da TPU é baseada no TensorFlow. Por exemplo,
Verifique se você tem as ferramentas de linha de comando necessárias para usar o conversor de inferência do Cloud TPU. É possível instalar o SDK Google Cloud e o Docker localmente ou usar uma VM TPU com esse software instalado por padrão. Use essas ferramentas para interagir com a imagem do Conversor.
Conecte-se à instância com SSH usando o seguinte comando:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Configuração do ambiente
Configure o ambiente no shell da VM do TPU ou no shell local.
Shell da VM da TPU
No shell da VM da TPU, execute os comandos a seguir para permitir o uso de contêineres não raiz:
sudo usermod -a -G docker ${USER} newgrp docker
Inicialize os auxiliares de credenciais do Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Shell local
No shell local, configure o ambiente seguindo estas etapas:
Instale o SDK Cloud, que inclui a ferramenta de linha de comando
gcloud.Instale o Docker:
Permitir o uso do Docker não raiz:
sudo usermod -a -G docker ${USER} newgrp docker
Faça login no ambiente:
gcloud auth login
Inicialize os auxiliares de credenciais do Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Extraia a imagem do Docker do Inference Converter:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Converter imagem
A imagem é para fazer conversões de modelo únicas. Defina os caminhos do modelo e ajuste as opções do conversor de acordo com suas necessidades. A seção Exemplos de uso apresenta vários casos de uso comuns.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inferência com o modelo convertido na VM de TPU
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Exemplos de uso
Adicionar um alias de função para a função TPU
- Encontre ou crie uma função no modelo que agrupe tudo o que você quer
executar na TPU. Se
@tf.functionnão existir, adicione-o. - Ao salvar o modelo, forneça as SaveOptions abaixo para dar
model.tpu_funcum aliasfunc_on_tpu. - É possível transmitir esse alias de função para o conversor.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Converter um modelo com várias funções de TPU
É possível colocar várias funções na TPU. Basta criar vários aliases de função e transmiti-los em converter_options_string para o conversor.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Quantização.
A quantização é uma técnica que reduz a precisão dos números usados para representar os parâmetros de um modelo. Isso resulta em um modelo menor e em uma computação mais rápida. Um modelo quantizado oferece ganhos na taxa de inferência, além de menor uso de memória e tamanho de armazenamento, à custa de pequenas quedas na precisão.
O novo recurso de quantização pós-treinamento no TensorFlow que é direcionado a TPU é desenvolvido com base no recurso semelhante existente no TensorFlow Lite usado para segmentar dispositivos móveis e de borda. Para saber mais sobre a quantização em geral, consulte o documento do TensorFlow Lite (em inglês).
Conceitos de quantização
Esta seção define conceitos relacionados especificamente à quantização com o Inference Converter.
Conceitos relacionados a outras configurações de TPU (por exemplo, fatias, hosts, chips e TensorCores) são descritos na página Arquitetura do sistema de TPU.
Quantização pós-treinamento (PTQ, na sigla em inglês): a PTQ é uma técnica que reduz o tamanho e a complexidade computacional de um modelo de rede neural sem afetar significativamente a precisão dele. A PTQ converte os pesos e as ativações de ponto flutuante de um modelo treinado em números inteiros de menor precisão, como 8 ou 16 bits. Isso pode causar uma redução significativa no tamanho do modelo e na latência de inferência, com apenas uma pequena perda na precisão.
Calibração: a etapa de calibração para quantização é o processo de coleta de estatísticas sobre o intervalo de valores que os pesos e as ativações de um modelo de rede neural assumem. Essas informações são usadas para determinar os parâmetros de quantização do modelo, que são os valores que serão usados para converter os pesos e ativações de ponto flutuante em números inteiros.
Conjunto de dados representativo: um conjunto de dados representativo para quantização é um conjunto de dados pequeno que representa os dados de entrada reais do modelo. Ele é usado durante a etapa de calibração da quantização para coletar estatísticas sobre o intervalo de valores que os pesos e ativações do modelo vão assumir. O conjunto de dados representativo precisa atender às seguintes propriedades:
- Ele precisa representar corretamente as entradas reais para o modelo durante a inferência. Isso significa que ele precisa abranger o intervalo de valores que o modelo provavelmente vai encontrar no mundo real.
- Ele precisa fluir coletivamente por cada ramificação de condicionais
(como
tf.cond), se houver alguma. Isso é importante porque o processo de quantização precisa ser capaz de processar todas as entradas possíveis para o modelo, mesmo que elas não sejam representadas explicitamente no conjunto de dados representativo. - Ele precisa ser grande o suficiente para coletar estatísticas suficientes e reduzir o erro. Como regra geral, é recomendável usar mais de 200 amostras representativas.
O conjunto de dados representativo pode ser um subconjunto do conjunto de dados de treinamento ou um conjunto de dados separado projetado especificamente para representar as entradas do mundo real no modelo. A escolha de qual conjunto de dados usar depende do aplicativo específico.
Quantização de intervalo estático (SRQ, na sigla em inglês): a SRQ determina o intervalo de valores para os pesos e as ativações de um modelo de rede neural uma vez, durante a etapa de calibração. Isso significa que o mesmo intervalo de valores é usado para todas as entradas do modelo. Isso pode ser menos preciso do que a quantização de intervalo dinâmico, especialmente para modelos com uma ampla gama de valores de entrada. No entanto, a quantização de intervalo estático requer menos computação no momento de execução do que a quantização de intervalo dinâmico.
Quantização de intervalo dinâmico (DRQ, na sigla em inglês): a DRQ determina o intervalo de valores para os pesos e as ativações de um modelo de rede neural para cada entrada. Isso permite que o modelo se adapte ao intervalo de valores dos dados de entrada, o que pode melhorar a precisão. No entanto, a quantização de intervalo dinâmico exige mais computação no momento da execução do que a quantização de intervalo estático.
Recurso Quantização de intervalo estático Quantização de alcance dinâmico Intervalo de valores Determinado uma vez, durante a calibração Determinado para cada entrada Precisão Pode ser menos preciso, especialmente para modelos com uma ampla gama de valores de entrada Pode ser mais preciso, especialmente para modelos com uma ampla gama de valores de entrada Complexidade Mais simples Mais complexo Cálculo no momento da execução Menos computação Mais computação Quantização somente de peso: é um tipo de quantização que quantifica apenas os pesos de um modelo de rede neural, deixando as ativações em ponto flutuante. Essa pode ser uma boa opção para modelos sensíveis à precisão, já que ajuda a preservar a precisão do modelo.
Como usar a quantização
A quantização pode ser aplicada configurando e definindo QuantizationOptions nas opções do conversor. As opções mais importantes são:
- tags: coleção de tags que identificam o
MetaGraphDefdentro doSavedModelpara quantização. Não é necessário especificar se você tiver apenas umMetaGraphDef. - signature_keys: sequência de chaves que identificam
SignatureDefcom entradas e saídas. Se não for especificado, ["serving_default"] será usado. - quantization_method: método de quantização a ser aplicado. Se não
for especificado, a quantização
STATIC_RANGEserá aplicada. - op_set: precisa ser mantido como XLA. No momento, essa é a opção padrão. Não é necessário especificar.
- representative_datasets: especifique o conjunto de dados usado para calibrar os parâmetros de quantização.
Como criar o conjunto de dados representativo
Um conjunto de dados representativo é basicamente um iterável de amostras.
Onde uma amostra é um mapa de: {input_key: input_value}. Exemplo:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
Os conjuntos de dados representativos precisam ser salvos como arquivos TFRecord
usando a classe TfRecordRepresentativeDatasetSaver
disponível no pacote tf-nightly pip. Exemplo:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Examples
O exemplo a seguir quantifica o modelo com a chave de assinatura
de serving_default e o alias de função de tpu_func:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Adicionar lotes
O Conversor pode ser usado para adicionar lotes a um modelo. Para uma descrição das opções de lote que podem ser ajustadas, consulte Definição das opções de lote.
Por padrão, o Conversor agrupa todas as funções de TPU no modelo. Ele também pode processar em lote as assinaturas e as funções fornecidas pelo usuário, o que pode melhorar ainda mais o desempenho. Qualquer função TPU, função fornecida pelo usuário ou assinatura que seja agrupada precisa atender aos requisitos de forma estrita da operação de agrupamento.
O Conversor também pode atualizar as opções de lote atuais. Confira a seguir um exemplo de como adicionar o processamento em lote a um modelo. Para mais informações sobre o agrupamento, consulte Aprofundamento sobre o agrupamento.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Desativar as otimizações de forma bfloat16 e IO
O BFloat16 e as otimizações de forma de E/S são ativados por padrão. Se eles não funcionarem bem com seu modelo, eles poderão ser desativados.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Relatório de conversão
Você pode encontrar esse relatório de conversão no registro depois de executar o Converter de inferência. Veja um exemplo abaixo.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
Esse relatório estima o custo computacional do modelo de saída na CPU e no TPU e detalha o custo do TPU para cada função, o que deve refletir sua seleção das funções do TPU nas opções do conversor.
Se você quiser utilizar melhor o TPU, experimente a estrutura do modelo e ajuste as opções do conversor.
Perguntas frequentes
Quais funções devo colocar na TPU?
É melhor colocar o máximo possível do modelo na TPU, porque a grande maioria das operações é executada mais rapidamente na TPU.
Se o modelo não tiver nenhuma operação, string ou tensor esparso incompatível com a TPU, colocar o modelo inteiro na TPU geralmente é a melhor estratégia. E isso pode ser feito encontrando ou criando uma função que envolva todo o modelo, criando um alias de função para ele e transmitindo-o ao Conversor.
Se o modelo tiver partes que não funcionam na TPU (por exemplo, operações incompatíveis com a TPU, strings ou tensors esparsas), a escolha das funções da TPU vai depender de onde está a parte incompatível.
- Se estiver no início ou no fim do modelo, você poderá refatorizar o modelo para mantê-lo na CPU. Exemplos são as fases de pré e pós-processamento de strings. Para mais informações sobre como mover o código para a CPU, consulte "Como mover uma parte do modelo para a CPU?" Ele mostra uma maneira típica de refatorar o modelo.
- Se estiver no meio do modelo, é melhor dividir o modelo em três partes e conter todas as operações incompatíveis com a TPU na parte do meio e fazer com que ela seja executada na CPU.
- Se for um tensor esparsa, chame
tf.sparse.to_densena CPU e transmita o tensor denso resultante para a parte do TPU do modelo.
Outro fator a considerar é o uso do HBM. A incorporação de tabelas pode usar muita HBM. Se elas ultrapassarem a limitação de hardware da TPU, elas precisarão ser colocadas na CPU, junto com as operações de pesquisa.
Sempre que possível, apenas uma função da TPU deve existir em uma assinatura. Se a estrutura do modelo exigir a chamada de várias funções de TPU por pedido de inferência, fique atento à latência adicional do envio de tensores entre a CPU e a TPU.
Uma boa maneira de avaliar a seleção de funções de TPU é verificar o Relatório de conversão. Ele mostra a porcentagem de computação que foi colocada na TPU e um detalhe do custo de cada função da TPU.
Como faço para mover uma parte do modelo para a CPU?
Se o modelo tiver partes que não podem ser atendidas na TPU, será necessário refatorizar o modelo para movê-las para a CPU. Confira um exemplo de brinquedo. O modelo é um modelo de linguagem com um estágio de pré-processamento. O código para definições de camada e funções foi omitido para simplificar.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Esse modelo não pode ser veiculado diretamente no TPU por dois motivos. Primeiro, o
parâmetro é uma string. Em segundo lugar, a função preprocess pode conter muitas operações
de string. Nenhum dos dois é compatível com TPU.
Para refatorar esse modelo, crie outra função chamada tpu_func para
hospedar o bert_layer de uso intensivo de computação. Em seguida, crie um alias de função para
tpu_func e transmita-o ao conversor. Dessa forma, tudo dentro de
tpu_func será executado na TPU, e tudo o que restar em model_func será executado na
CPU.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
O que devo fazer se o modelo tiver operações, strings ou tensors esparsas incompatíveis com o TPU?
A maioria das operações padrão do TensorFlow tem suporte à TPU, mas algumas, incluindo tensores e strings raros, não têm. O conversor não verifica operações incompatíveis com a TPU. Portanto, um modelo que contém essas operações pode transmitir a conversão. Mas, ao executar para inferência, erros como os abaixo vão ocorrer.
'tf.StringToNumber' op isn't compilable for TPU device.
Se o modelo tiver operações incompatíveis com a TPU, elas precisarão ser colocadas fora da função da TPU. Além disso, a string é um formato de dados não compatível com o TPU. Portanto, as variáveis do tipo string não podem ser colocadas na função TPU. Além disso, os parâmetros e os valores de retorno da função TPU não podem ser do tipo string. Da mesma forma, evite colocar tensores esparsas na função TPU, incluindo os parâmetros e valores de retorno.
Geralmente, não é difícil refatorar a parte incompatível do modelo e movimentá-la para a CPU. Confira um exemplo.
Como oferecer suporte a operações personalizadas no modelo?
Se as operações personalizadas forem usadas no modelo, o Conversor poderá não reconhecê-las e não converter o modelo. Isso ocorre porque a biblioteca de operações da operação personalizada, que contém a definição completa da operação, não está vinculada ao Conversor.
Como o código do conversor ainda não é de código aberto, ele não pode ser criado com uma operação personalizada.
O que devo fazer se tiver um modelo do TensorFlow 1?
O Conversor não oferece suporte a modelos do TensorFlow 1. Os modelos do TensorFlow 1 precisam ser migrados para o TensorFlow 2.
Preciso ativar a ponte MLIR ao executar meu modelo?
A maioria dos modelos convertidos pode ser executada com a ponte MLIR TF2XLA mais recente ou a ponte TF2XLA original.
Como converter um modelo que já foi exportado sem um alias de função?
Se um modelo foi exportado sem um alias de função, a maneira mais fácil é exportá-lo
novamente e
criar um alias de função.
Se a reexportação não for uma opção, ainda será possível converter o modelo fornecendo um concrete_function_name. No entanto, identificar o
concrete_function_name correto exige um pouco de trabalho de detetive.
Os aliases de função são um mapeamento de uma string definida pelo usuário para um nome de função concreto. Eles facilitam a referência a uma função específica no modelo. O conversor aceita nomes de função concretos e nomes de função concretos brutos.
Os nomes de função concretos podem ser encontrados examinando o saved_model.pb.
O exemplo a seguir mostra como colocar uma função específica chamada
__inference_serve_24 na TPU.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
Como resolver um erro de restrição constante no tempo de compilação?
Para treinamento e inferência, a XLA exige que as entradas de determinadas operações tenham uma forma conhecida no momento da compilação da TPU. Isso significa que, quando a XLA compila a parte do TPU do programa, as entradas para essas operações precisam ter uma forma conhecida estaticamente.
Há duas maneiras de resolver esse problema.
- A melhor opção é atualizar as entradas da operação para ter uma forma conhecida
estática até que o XLA compile o programa TPU. Essa compilação acontece
logo antes que a parte da TPU do modelo seja executada. Isso significa que a forma
precisa ser conhecida de forma estática no momento em que o
TpuFunctionestá prestes a ser executado. - Outra opção é modificar o
TpuFunctionpara não incluir mais a operação problemática.
Por que estou recebendo um erro de lote de formas?
O agrupamento tem requisitos de forma rígidos que permitem que as solicitações recebidas sejam agrupadas na dimensão 0 (também conhecida como dimensão de agrupamento). Esses requisitos de forma vêm da operação de lote do TensorFlow e não podem ser relaxados.
O não cumprimento desses requisitos resultará em erros como:
- Os tensors de entrada em lote precisam ter pelo menos uma dimensão.
- As dimensões das entradas precisam ser iguais.
- Os tensores de entrada em lote fornecidos em uma determinada invocação de operação precisam ter o mesmo tamanho da dimensão 0.
- A dimensão 0 do tensor de saída em lote não é igual à soma dos tamanhos da dimensão 0 dos tensores de entrada.
Para atender a esses requisitos, forneça uma função ou uma assinatura diferente para o lote. Também pode ser necessário modificar as funções atuais para atender a esses requisitos.
Se uma função
estiver sendo agrupada, verifique se todas as formas de input_signature da @tf.function
têm None na dimensão 0. Se uma assinatura
estiver sendo agrupada, verifique se todas as entradas dela têm -1 na dimensão 0.
Para uma explicação completa sobre por que esses erros estão acontecendo e como resolvê-los, consulte Aprofundamento sobre lotes.
Problemas conhecidos
A função da TPU não pode chamar indiretamente outra função da TPU.
Embora o Conversor possa processar a maioria dos cenários de chamada de função na fronteira CPU-TPU, há um caso raro de falha. É quando uma função TPU chama indiretamente outra função TPU.
Isso acontece porque o Conversor modifica o autor da chamada direta de uma função TPU, chamando a própria função TPU para chamar um stub de chamada TPU. O stub de chamada contém operações que só podem funcionar na CPU. Quando uma função da TPU chama qualquer função que chama o autor da chamada direta, essas operações da CPU podem ser trazidas para a TPU para execução, o que gera erros de kernel ausentes. Observe que esse caso é diferente de uma função de TPU que chama diretamente outra função de TPU. Nesse caso, o Conversor não modifica nenhuma função para chamar o stub de chamada.
No Conversor, implementamos a detecção desse cenário. Se você receber o seguinte erro, significa que seu modelo atingiu este caso extremo:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
A solução geral é refatorar o modelo para evitar esse cenário de chamada de função. Se isso for difícil, entre em contato com a equipe de suporte do Google para discutir mais.
Referência
Opções do conversor no formato Protobuf
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Aprofundamento sobre a execução em lote
O lote é usado para melhorar a capacidade e a utilização da TPU. Isso permite
que várias solicitações sejam processadas ao mesmo tempo. Durante o treinamento, o agrupamento
pode ser feito usando tf.data. Durante a inferência, isso geralmente é feito adicionando uma
operação no gráfico que agrupa as solicitações recebidas. A operação vai aguardar até receber solicitações
suficientes ou até que um tempo limite seja atingido antes de gerar um lote grande das
solicitações individuais. Consulte
Definição de opções de lote
para mais informações sobre as diferentes opções de lote que podem ser ajustadas,
incluindo tamanhos e tempos limite de lote.
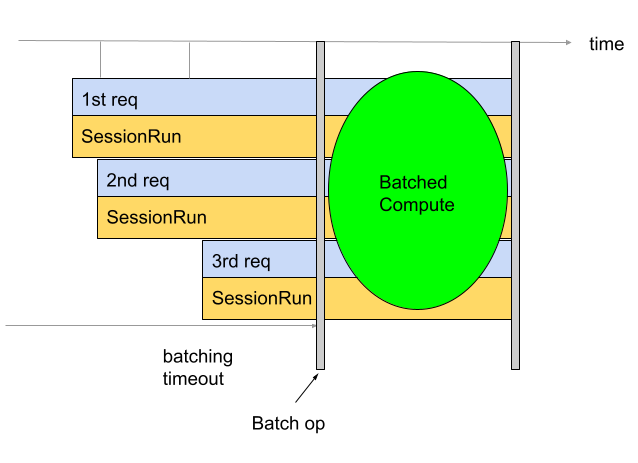
Por padrão, o Conversor insere a operação de lote diretamente antes da computação do TPU. Ele envolve as funções de TPU fornecidas pelo usuário e qualquer computação de TPU preexistente no modelo com operações de lote. É possível substituir esse comportamento padrão informando ao Conversor quais funções e/ou assinaturas precisam ser agrupadas.
O exemplo a seguir mostra como adicionar o lote padrão.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Lotes de assinaturas
O agrupamento de assinaturas agrupa todo o modelo, começando pelas entradas da assinatura e indo até as saídas. Ao contrário do comportamento padrão de agrupamento do Conversor, o agrupamento de assinaturas agrupa a computação da TPU e da CPU. Isso gera um ganho de 10% a 20% no desempenho durante a inferência em alguns modelos.
Como todos os lotes, o lote de assinaturas tem
requisitos de formato rígidos.
Para garantir que esses requisitos sejam atendidos, as entradas de assinatura precisam ter
formas com pelo menos duas dimensões. A primeira dimensão é o tamanho do lote
e precisa ter um tamanho de -1. Por exemplo, (-1, 4), (-1) ou (-1,
128, 4, 10) são formas de entrada válidas. Se isso não for possível, considere usar
o comportamento padrão de agrupamento ou
agrupamento de funções.
Para usar o agrupamento de assinaturas, forneça os nomes das assinaturas como signature_name
usando o BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Função em lote
O agrupamento de funções pode ser usado para informar ao Conversor quais funções precisam ser agrupadas. Por padrão, o Conversor agrupa todas as funções de TPU. O lote de funções substitui esse comportamento padrão.
O lote de funções pode ser usado para agrupar a computação da CPU. Muitos modelos apresentam uma melhoria no desempenho quando a computação da CPU é agrupada. A melhor maneira de processar a CPU em lote é usando a assinatura em lote, mas ela pode não funcionar para alguns modelos. Nesses casos, o agrupamento de funções pode ser usado para agrupar parte da CPU e da TPU. A operação de agrupamento não pode ser executada na TPU. Portanto, qualquer função de agrupamento fornecida precisa ser chamada na CPU.
O agrupamento de funções também pode ser usado para atender aos requisitos de formato estrito imppostos pela operação de agrupamento. Nos casos em que as funções de TPU não atendem aos requisitos de formato da operação de agrupamento, o agrupamento de funções pode ser usado para informar ao conversor para agrupar diferentes funções.
Para usar isso, gere um function_alias para a função que precisa ser
processada em lote. Para isso, encontre ou crie uma função no modelo
que agrupe tudo o que você quer processar em lote. Verifique se essa função atende aos
requisitos de forma estrita
impedidos pela operação de lote. Adicione @tf.function se ela ainda não tiver um.
É importante fornecer o input_signature para o @tf.function. A dimensão 0 precisa ser None porque é a dimensão do lote, então não pode ter um tamanho fixo. Por exemplo, [None, 4], [None] ou [None, 128, 4, 10] são
formas de entrada válidas. Ao salvar o modelo, forneça SaveOptions como os mostrados
abaixo para dar a model.batch_func um alias "batch_func". Em seguida, transmita esse
alias de função para o conversor.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Em seguida, transmita os function_alias usando as BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Definição das opções de lote
num_batch_threads: (número inteiro) número de linhas de execução de programação para processar lotes de trabalho. Determina o número de lotes processados em paralelo. Isso deve ser aproximadamente o mesmo que o número de núcleos de TPU disponíveis.max_batch_size: (número inteiro) tamanho máximo do lote permitido. Pode ser maior do queallowed_batch_sizespara usar a divisão de lotes grandes.batch_timeout_micros: (número inteiro) número máximo de microssegundos a serem aguardados antes de gerar um lote incompleto.allowed_batch_sizes: (lista de números inteiros) se a lista não estiver vazia, ela vai preencher os lotes até o tamanho mais próximo na lista. A lista precisa ser crescente e o elemento final precisa ser menor ou igual amax_batch_size.max_enqueued_batches: (número inteiro) número máximo de lotes enfileirados para processamento antes que as solicitações falhem rapidamente.
Como atualizar as opções de lote
É possível adicionar ou atualizar opções de lote executando a imagem do Docker especificando
batch_options e definindo disable_default_optimizations como verdadeiro usando a
flag --converter_options_string. As opções de lote serão aplicadas a todas
as funções de TPU ou operações de lote preexistentes.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Requisitos de forma em lote
Os lotes são criados concatenando tensores de entrada em solicitações ao longo da dimensão (0ª) do lote. Os tensores de saída são divididos pela dimensão 0. Para realizar essas operações, a operação de agrupamento tem requisitos de forma rígidos para as entradas e saídas.
Tutorial
Para entender esses requisitos, é útil entender primeiro como
o agrupamento é realizado. No exemplo abaixo, estamos agrupando uma operação
tf.matmul simples.
def my_func(A, B) return tf.matmul(A, B)
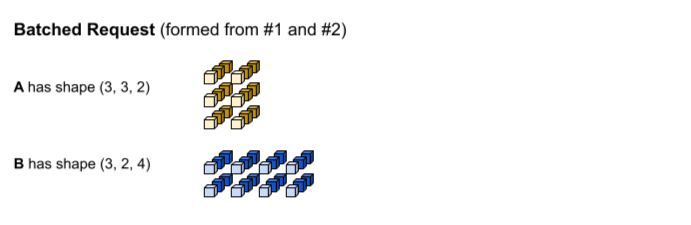
A primeira solicitação de inferência produz as entradas A e B com as formas (1, 3,
2) e (1, 2, 4), respectivamente. A segunda solicitação de inferência produz as
entradas A e B com as formas (2, 3, 2) e (2, 2, 4).

O tempo limite de lote foi atingido. O modelo oferece suporte a um tamanho de lote de 3, para que
as solicitações de inferência 1 e 2 sejam agrupadas sem preenchimento. Os
tensores agrupados são formados concatenando as solicitações 1 e 2 ao longo da dimensão
do lote (0). Como o A de #1 tem a forma (1, 3, 2) e o A de #2 tem a forma (2, 3, 2), quando eles são concatenados ao longo da dimensão do lote (0), a forma resultante é (3, 3, 2).
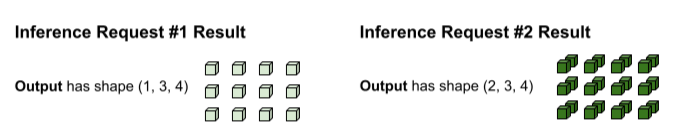
O tf.matmul é executado e produz uma saída com a forma (3, 3,
4).

A saída do tf.matmul é agrupada, então ela precisa ser dividida em
solicitações separadas. A operação de lote faz isso dividindo a dimensão do lote (0)
de cada tensor de saída. Ele decide como dividir a dimensão 0 com base
no formato das entradas originais. Como as formas da solicitação 1 têm uma dimensão 0 de 1, a saída tem uma dimensão 0 de 1 para uma forma de (1, 3, 4).
Como as formas da solicitação 2 têm uma dimensão 0 de 2, a saída tem uma dimensão 0
de 2 para uma forma de (2, 3, 4).
Requisitos de forma
Para realizar a concatenação de entrada e a divisão de saída descritas acima, a operação de lote tem os seguintes requisitos de forma:
As entradas para agrupamento não podem ser escalares. Para concatenar ao longo da dimensão 0, os tensores precisam ter pelo menos duas dimensões.
No tutorial acima. Nem A nem B são escalares.
Se esse requisito não for atendido, vai ocorrer um erro como:
Batching input tensors must have at least one dimension. Uma correção simples para esse erro é transformar o escalar em um vetor.Em diferentes solicitações de inferência (por exemplo, diferentes invocações de execução de sessão), os tensors de entrada com o mesmo nome têm o mesmo tamanho para cada dimensão, exceto a dimensão 0. Isso permite que as entradas sejam concatenadas de forma limpa ao longo da dimensão 0.
No tutorial acima, a solicitação 1 tem uma forma de
(1, 3, 2). Isso significa que qualquer solicitação futura precisa produzir uma forma com o padrão(X, 3, 2). A solicitação 2 atende a esse requisito com(2, 3, 2). Da mesma forma, a solicitação 1 tem uma forma de(1, 2, 4), então todas as solicitações futuras precisam produzir uma forma com o padrão(X, 2, 4).Se esse requisito não for atendido, vai ocorrer um erro como:
Dimensions of inputs should match.Para uma determinada solicitação de inferência, todas as entradas precisam ter o mesmo tamanho de dimensão 0. Se diferentes tensores de entrada para a operação de agrupamento tiverem dimensões diferentes, a operação de agrupamento não saberá como dividir os tensores de saída.
No tutorial acima, todos os tensores da solicitação 1 têm um tamanho de dimensão 0 de 1. Isso permite que a operação de lote saiba que a saída precisa ter um tamanho de dimensão 0 de 1. Da mesma forma, os tensores da solicitação 2 têm um tamanho de dimensão 0 de 2, então a saída terá um tamanho de dimensão 0 de 2. Quando a operação de agrupamento divide a forma final de
(3, 3, 4), ela produz(1, 3, 4)para a solicitação 1 e(2, 3, 4)para a solicitação 2.O não cumprimento desse requisito resultará em erros como:
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size.O tamanho da dimensão 0 de cada forma do tensor de saída precisa ser a soma do tamanho da dimensão 0 de todos os tensors de entrada, além de qualquer preenchimento introduzido pela operação de agrupamento para atender ao próximo
allowed_batch_sizemaior. Isso permite que a operação de agrupamento divida os tensors de saída ao longo da dimensão 0 com base na dimensão 0 dos tensors de entrada.No tutorial acima, os tensors de entrada têm uma dimensão 0 de 1 da solicitação 1 e 2 da solicitação 2. Portanto, cada tensor de saída precisa ter uma dimensão 0 de 3 porque 1+2=3. O tensor de saída
(3, 3, 4)atende a esse requisito. Se 3 não fosse um tamanho de lote válido, mas 4 fosse, a operação de lote teria que preencher a dimensão 0 das entradas de 3 para 4. Nesse caso, cada tensor de saída precisa ter um tamanho de dimensão 0 de 4.O não cumprimento desse requisito resultará em um erro como:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors.
Como resolver erros de requisitos de forma
Para atender a esses requisitos, forneça uma função ou uma assinatura diferente para o lote. Também pode ser necessário modificar as funções atuais para atender a esses requisitos.
Se uma
função
estiver sendo agrupada, verifique se todas as formas de input_signature do @tf.function
têm None na dimensão 0 (também conhecida como dimensão do lote). Se uma
assinatura
estiver sendo agrupada, verifique se todas as entradas dela têm -1 na dimensão 0.
A operação BatchFunction não aceita SparseTensors como entradas ou saídas.
Internamente, cada tensor esparsa é representado como três tensores separados que podem
ter diferentes tamanhos de dimensão 0.