Cloud TPU v5e 추론 변환기 소개
소개
Cloud TPU 추론 변환기는 TPU 추론을 위해 TensorFlow 2(TF2) 모델을 준비하고 최적화합니다. 이 변환기는 로컬 또는 TPU VM 셸에서 실행됩니다. TPU VM 셸은 변환기에 필요한 명령줄 도구가 사전 설치되어 있으므로 권장됩니다. 내보낸 SavedModel을 가져와 다음 단계를 수행합니다.
- TPU 변환:
TPUPartitionedCall및 기타 TPU 작업을 모델에 추가하여 TPU에 서빙되도록 합니다. 기본적으로 추론을 위해 내보낸 모에는 이러한 작업이 없으며 TPU에서 학습되었더라도 TPU에서 서빙할 수 없습니다. - 일괄 처리: 처리량 향상을 위해 그래프 내 일괄 처리를 사용 설정하도록 모델에 일괄 작업을 추가합니다.
- BFloat16 변환: TPU의 컴퓨팅 성능을 향상시키고 고대역폭 메모리(HBM) 사용량을 낮추기 위해 모델의 데이터 형식을
float32에서bfloat16으로 변환합니다. - IO 형태 최적화: CPU와 TPU 간에 전송되는 데이터의 텐서 형태를 최적화하여 대역폭 사용률을 향상시킵니다.
모델을 내보낼 때 사용자는 TPU에서 실행하려는 모든 함수의 함수 별칭을 만듭니다. 이러한 함수를 변환기에 전달하면 변환기는 이를 TPU에 배치하고 최적화합니다.
Cloud TPU 추론 변환기는 Docker가 설치된 모든 환경에서 실행할 수 있는 Docker 이미지로 제공됩니다.
위에 표시된 단계를 완료하는 데 걸리는 예상 시간: ~20분~30분
기본 요건
- 모델은 TF2 모델이어야 하며 SavedModel 형식으로 내보내야 합니다.
- 모델에는 TPU 함수의 함수 별칭이 있어야 합니다. 자세한 방법은 코드 예시를 참조하세요. 다음 예시에서는
tpu_func를 TPU 함수 별칭으로 사용합니다. - TensorFlow 라이브러리(Cloud TPU 추론 변환기의 종속 항목)가 AVX 명령을 사용하도록 컴파일되므로 머신의 CPU가 Advanced Vector eXtensions(AVX) 명령을 지원하는지 확인합니다.
대부분의 CPU는 AVX를 지원합니다.
lscpu | grep avx를 실행하여 AVX 명령 집합이 지원되는지 확인할 수 있습니다.
시작하기 전에
설정을 시작하기 전에 다음을 수행하세요.
새 프로젝트 만들기: Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Cloud 프로젝트를 선택하거나 만듭니다.
TPU VM 설정: Google Cloud 콘솔 또는
gcloud를 사용하여 새 TPU VM을 만들거나 TPU VM에서 기존 TPU VM을 사용하여 변환된 모델로 추론을 실행합니다.- TPU VM 이미지가 TensorFlow 기반인지 확인합니다. 예를 들면
--version=tpu-vm-tf-2.11.0입니다. - 변환된 모델이 로드되고 이 TPU VM에 서빙됩니다.
- TPU VM 이미지가 TensorFlow 기반인지 확인합니다. 예를 들면
Cloud TPU 추론 변환기를 사용하는 데 필요한 명령줄 도구가 있는지 확인합니다. 로컬에 Google Cloud SDK 및 Docker를 설치하거나 이 소프트웨어가 기본적으로 설치된 TPU VM을 사용할 수 있습니다. 이 도구를 사용하여 변환기 이미지와 상호작용합니다.
다음 명령어를 사용하여 SSH를 사용하는 인스턴스에 연결합니다.
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
환경 설정
TPU VM 셸 또는 로컬 셸에서 환경을 설정합니다.
TPU VM 셸
TPU VM 셸에서 다음 명령어를 실행하여 루트가 아닌 Docker 사용을 허용합니다.
sudo usermod -a -G docker ${USER} newgrp docker
Docker 사용자 인증 정보 도우미를 초기화합니다.
gcloud auth configure-docker \ us-docker.pkg.dev
로컬 셸
로컬 셸에서 다음 단계를 수행하여 환경을 설정합니다.
추론 변환기 Docker 이미지를 가져옵니다.
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
변환기 이미지
이 이미지는 일회성 모델 변환을 수행하기 위한 것입니다. 모델 경로를 설정하고 필요에 맞게 변환기 옵션을 조정하세요. 사용 예시 섹션에서는 몇 가지 일반적인 사용 사례를 제공합니다.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
TPU VM에서 변환된 모델 추론
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
사용 예시
TPU 함수의 함수 별칭 추가
- TPU에서 실행하려는 모든 것을 래핑하는 함수를 모델에서 찾거나 만듭니다.
@tf.function이 없는 경우 추가합니다. - 모델을 저장할 때 아래와 같이 SaveOptions를 제공하여
model.tpu_func에 별칭func_on_tpu를 부여합니다. - 이 함수 별칭을 변환기에 전달할 수 있습니다.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
여러 TPU 함수로 모델 변환
TPU에 여러 함수를 넣을 수 있습니다. 간단하게 여러 개의 함수 별칭을 만들고 converter_options_string에서 변환기에 전달합니다.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
양자화
양자화는 모델 매개변수를 나타내는 데 사용되는 숫자의 정밀도를 줄이는 기법입니다. 따라서 모델 크기가 줄어들고 계산 속도가 빨라집니다. 양자화 모델에서는 추론 처리량이 향상되고 메모리 사용량과 스토리지 크기가 줄어들지만 정확성이 약간 저하됩니다.
TPU를 대상으로 하는 TensorFlow의 새로운 학습 후 양자화 기능은 모바일 및 에지 기기를 대상으로 하는 데 사용되는 TensorFlow Lite의 유사한 기존 기능에서 개발되었습니다. 일반적인 양자화에 대해 자세히 알아보려면 TensorFlow Lite 문서를 참조하세요.
양자화 개념
이 섹션에서는 추론 변환기를 사용한 양자화와 관련된 개념을 정의합니다.
다른 TPU 구성과 관련된 개념(예: 슬라이스, 호스트, 칩, TensorCore)은 TPU 시스템 아키텍처 페이지에 설명되어 있습니다.
학습 후 양자화(PTQ): PTQ는 신경망 모델의 크기와 계산의 복잡성을 줄여 정확성에 큰 영향을 미치지 않는 기법입니다. PTQ는 학습된 모델의 부동 소수점 가중치와 활성화를 8비트 또는 16비트 정수와 같은 정밀도가 낮은 정수로 변환하는 방식으로 작동합니다. 이로 인해 모델 크기 및 추론 지연 시간이 크게 줄어들면서 정확성이 약간 손실될 뿐입니다.
조정: 양자화를 위한 조정 단계는 신경망 모델의 가중치 및 활성화에 사용되는 값 범위에 대한 통계를 수집하는 프로세스입니다. 이 정보는 모델의 양자화 매개변수를 결정하는 데 사용됩니다. 이 매개변수는 부동 소수점 가중치와 활성화를 정수로 변환하는 데 사용되는 값입니다.
대표 데이터 세트: 양자화를 위한 대표 데이터 세트는 모델의 실제 입력 데이터를 나타내는 작은 데이터 세트입니다. 양자화 조정 단계에서 모델의 가중치와 활성화가 사용하는 값 범위에 대한 통계를 수집하기 위해 사용됩니다. 대표 데이터 세트는 다음 속성을 충족해야 합니다.
- 추론 중에 모델에 대한 실제 입력을 올바르게 나타내야 합니다. 즉, 모델이 실제 환경에서 볼 가능성이 높은 값의 범위를 포함해야 합니다.
- 조건부(예:
tf.cond)가 있는 경우 각 브랜치를 통해 집합적으로 흘러야 합니다. 이는 양자화 프로세스가 대표 데이터 세트에 명시적으로 표현되지 않더라도 모델에 대한 모든 가능한 입력을 처리할 수 있어야 하기 때문에 중요합니다. - 통계를 충분히 수집하고 오류를 줄일 수 있을 만큼 충분히 커야 합니다. 일반적으로 200개가 넘는 대표 샘플을 사용하는 것이 좋습니다.
대표 데이터 세트는 학습 데이터 세트의 하위 집합이거나 모델에 대한 실제 입력을 나타내도록 특별히 설계된 별도의 데이터 세트일 수 있습니다. 사용할 데이터 세트는 특정 애플리케이션에 따라 달라집니다.
정적 범위 양자화(SRQ): SRQ는 조정 단계 중에 신경망 모델의 가중치 및 활성화에 대한 값 범위를 한 번 결정합니다. 즉, 모델의 모든 입력에 동일한 값 범위가 사용됩니다. 특히 입력 값의 범위가 넓은 모델의 경우 동적 범위 양자화보다 정확도가 떨어질 수 있습니다. 그러나 정적 범위 양자화에는 런타임 시 동적 범위 양자화보다 적은 계산이 필요합니다.
동적 범위 양자화(DRQ): DRQ는 각 입력의 신경망 모델 가중치 및 활성화에 대한 값 범위를 결정합니다. 이렇게 하면 모델이 입력 데이터의 값 범위에 맞게 조정하여 정확성을 개선할 수 있습니다. 하지만 동적 범위 양자화에는 런타임 시 정적 범위 양자화보다 더 많은 계산이 필요합니다.
특성 정적 범위 양자화 동적 범위 양자화 값 범위 조정 중 한 번 결정 입력마다 결정 정확성 특히 다양한 입력 값을 사용하는 모델의 경우 정확성이 떨어질 수 있음 특히 다양한 입력 값을 사용하는 모델의 경우 더 정확할 수 있음 복잡성 더 간편함 더 복잡함 런타임 시 계산 더 적은 계산 더 많은 계산 가중치 전용 양자화: 가중치 전용 양자화는 신경망 모델의 가중치만 양자화하고 활성화 값은 부동 소수점으로 남겨두는 양자화 유형입니다. 모델의 정확성 보존에 도움이 될 수 있으므로 정확성에 민감한 모델에 적합한 옵션입니다.
양자화 사용 방법
변환기 옵션에 QuantizationOptions를 구성하고 설정하여 양자화를 적용할 수 있습니다. 주목할 만한 옵션은 다음과 같습니다.
- 태그: 양자화할
SavedModel내의MetaGraphDef를 식별하는 태그 모음입니다.MetaGraphDef기 하나만 있는 경우 지정할 필요는 없습니다. - signature_keys: 입력 및 출력이 포함된
SignatureDef를 식별하는 키 시퀀스입니다. 지정하지 않으면 ['serving_default']가 사용됩니다. - quantization_method: 적용할 양자화 방법입니다. 지정하지 않으면
STATIC_RANGE양자화가 적용됩니다. - op_set: XLA로 유지해야 합니다. 이는 현재 기본 옵션이며 지정할 필요가 없습니다.
- representative_datasets: 양자화 매개변수를 조정하는 데 사용되는 데이터 세트를 지정합니다.
대표 데이터 세트 빌드
대표 데이터 세트는 기본적으로 샘플의 반복 가능한 항목입니다.
여기서 샘플은 {input_key: input_value}의 맵입니다. 예를 들면 다음과 같습니다.
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
대표 데이터 세트는 현재 tf-nightly pip 패키지에서 제공되는 TfRecordRepresentativeDatasetSaver 클래스를 사용하여 TFRecord 파일로 저장해야 합니다. 예를 들면 다음과 같습니다.
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
예시
다음 예시에서는 serving_default의 서명 키와 tpu_func의 함수 별칭으로 모델을 양자화합니다.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
일괄 처리 추가
변환기를 사용하여 모델에 일괄 처리를 추가할 수 있습니다. 조정할 수 있는 일괄 처리 옵션에 대한 설명은 일괄 처리 옵션 정의를 참조하세요.
기본적으로 변환기는 모델의 모든 TPU 함수를 일괄 처리합니다. 또한 사용자 제공 서명과 함수를 일괄 처리하여 성능을 향상시킬 수 있습니다. 모든 TPU 함수, 사용자 제공 함수 또는 일괄 처리되는 서명은 일괄 처리 작업의 엄격한 형태 요구사항을 충족해야 합니다.
변환기는 기존 일괄 처리 옵션을 업데이트할 수도 있습니다. 다음은 모델에 일괄 처리를 추가하는 방법의 예시입니다. 일괄 처리에 대한 자세한 내용은 일괄 처리 심층 분석을 참조하세요.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
bfloat16 및 IO 형태 최적화 사용 중지
BFloat16 및 IO 형태 최적화는 기본적으로 사용 설정되어 있습니다. 모델에서 제대로 작동하지 않으면 사용 중지할 수 있습니다.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
변환 보고서
추론 변환기를 실행한 후 로그에서 이 변환 보고서를 찾을 수 있습니다. 아래에 예시가 나와 있습니다.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
이 보고서는 CPU 및 TPU에서 출력 모델의 연산 비용을 추정하고 각 함수별로 TPU 비용을 세분화하여 변환기 옵션에서 TPU 함수 선택을 반영해야 합니다.
TPU를 더 잘 활용하려면 모델 구조를 실험하고 변환기 옵션을 조정해야 할 수 있습니다.
FAQ
TPU에 어떤 함수를 배치해야 하나요?
대부분의 작업은 TPU에서 더 빠르게 실행되므로 TPU에 최대한 많은 모델을 배치하는 것이 좋습니다.
모델에 TPU와 호환되지 않는 작업, 문자열, 희소 텐서가 포함되지 않은 경우 일반적으로 모델 전체를 TPU에 배치하는 것이 가장 좋습니다. 전체 모델을 래핑하는 함수를 찾거나 만들고, 이를 위한 함수 별칭을 만들고, 변환기에 전달하여 이 작업을 수행할 수 있습니다.
모델에 TPU에서 작동할 수 없는 부분(예: TPU 비호환 작업, 문자열, 희소 텐서)이 포함된 경우 TPU 함수를 선택할 수 있는 위치는 호환되지 않는 부분의 위치에 따라 달라집니다.
- 모델의 시작 또는 끝 부분에 있으면 모델을 리팩터링하여 CPU에서 유지할 수 있습니다. 예를 들어 문자열 사전 및 사후 처리 단계가 있습니다. 코드를 CPU로 이동하는 방법에 대한 자세한 내용은 '모델의 일부를 CPU로 이동하려면 어떻게 해야 하나요?'를 참조하세요. 여기에서 모델을 리팩터링하는 일반적인 방법을 보여줍니다.
- 모델 중간단계에 있으면 모델을 세 부분으로 분할하고 중간 부분에 TPU 비호환 작업을 모두 포함하여 CPU에서 실행하는 것이 좋습니다.
- 희소 텐서인 경우 CPU에서
tf.sparse.to_dense를 호출하여 결과 밀도 텐서를 모델의 TPU 부분에 전달하는 것이 좋습니다.
고려해야 할 또 다른 요소는 HBM 사용량입니다. 테이블을 임베딩하면 많은 HBM을 사용할 수 있습니다. TPU의 하드웨어 한도를 초과하는 경우 조회 작업과 함께 CPU에 배치해야 합니다.
가능하다면 한 개의 서명 아래에 TPU 함수 하나만 있어야 합니다. 모델 구조에 따라 수신 추론 요청당 여러 TPU 함수가 호출되어야 하는 경우 CPU와 TPU 간에 텐서를 전송할 때 지연 시간이 추가된다는 점을 알고 있어야 합니다.
TPU 함수 선택을 평가하는 좋은 방법은 변환 보고서를 확인하는 것입니다. TPU에 배치된 계산 비율과 각 TPU 함수 비용 분석을 보여줍니다.
모델의 일부를 CPU로 이동하려면 어떻게 해야 하나요?
모델에 TPU에서 서빙할 수 없는 부분이 포함된 경우 모델을 리팩터링하여 해당 부분을 CPU로 이동해야 합니다. 다음은 장난감 예시입니다. 모델은 사전 처리 단계가 있는 언어 모델입니다. 편의상 레이어 정의 및 함수 코드는 생략합니다.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
이 모델은 두 가지 이유로 TPU에 직접 서빙될 수 없습니다. 먼저 매개변수는 문자열입니다. 둘째, preprocess 함수는 여러 문자열 작업을 포함할 수 있습니다. 둘 다 TPU와 호환되지 않습니다.
이 모델을 리팩터링하기 위해서는 tpu_func라는 또 다른 함수를 만들어 계산 집약적인 bert_layer를 호스팅할 수 있습니다. 그런 다음 tpu_func의 함수 별칭을 만들고 변환기에 전달합니다. 이렇게 하면 tpu_func 내의 모든 항목이 TPU에서 실행되고 model_func에 남아 있는 모든 항목이 CPU에서 실행됩니다.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
모델에 TPU와 호환되지 않는 작업, 문자열, 희소 텐서가 있는 경우 어떻게 해야 하나요?
대부분의 표준 TensorFlow 작업은 TPU에서 지원되지만 희소 텐서와 문자열을 포함한 몇 가지 작업은 지원되지 않습니다. 변환기는 TPU와 호환되지 않는 작업을 확인하지 않습니다. 따라서 이러한 작업이 포함된 모델은 변환을 통과할 수 있습니다. 그러나 추론을 위해 실행하면 다음과 같은 오류가 발생합니다.
'tf.StringToNumber' op isn't compilable for TPU device.
모델에 TPU와 호환되지 않는 작업이 있으면 TPU 함수 외부에 배치해야 합니다. 또한 문자열이 TPU에서 지원되지 않는 데이터 형식입니다. 따라서 문자열 유형 변수를 TPU 함수에 배치해서는 안 됩니다. 또한 TPU 함수의 매개변수 및 반환 값도 문자열 유형으로 지정해서는 안 됩니다. 마찬가지로, 매개변수 및 반환 값을 포함하여 TPU 함수에 희소 텐서를 배치하면 안 됩니다.
일반적으로 모델의 호환되지 않는 부분을 리팩터링하고 CPU로 이동하기는 쉽지 않습니다. 예를 들면 다음과 같습니다.
모델에서 커스텀 작업을 지원하려면 어떻게 해야 하나요?
모델에서 커스텀 작업이 사용되는 경우 변환기가 이를 인식하지 못하고 모델을 변환하지 못할 수 있습니다. 해당 작업의 전체 정의가 포함된 커스텀 작업의 작업 라이브러리가 변환기에 연결되지 않았기 때문입니다.
현재 변환기 코드는 오픈소스로 제공되지 않으므로 커스텀 작업으로 변환기를 빌드할 수 없습니다.
TensorFlow 1 모델이 있는 경우 어떻게 해야 하나요?
변환기는 TensorFlow 1 모델을 지원하지 않습니다. TensorFlow 1 모델은 TensorFlow 2로 마이그레이션해야 합니다.
모델을 실행할 때 MLIR 브리지를 사용 설정해야 하나요?
대부분의 변환된 모델은 최신 TF2XLA MLIR 브리지 또는 원래 TF2XLA 브리지로 실행할 수 있습니다.
함수 별칭 없이 이미 내보낸 모델을 변환하려면 어떻게 해야 하나요?
함수 별칭 없이 모델을 내보낸 경우 다시 내보내는 가장 쉬운 방법은 함수 별칭을 만드는 것입니다.
다시 내보내기를 사용할 수 없는 경우에도 concrete_function_name을 제공하여 모델을 변환할 수 있습니다. 그러나 올바른 concrete_function_name을 식별하려면 몇 가지 감지 작업이 필요합니다.
함수 별칭은 사용자 정의 문자열에서 특정 함수 이름으로의 매핑입니다. 모델의 특정 함수를 쉽게 참조할 수 있습니다. 변환기는 함수 별칭과 원시 특정 함수 이름을 모두 허용합니다.
특정 함수 이름은 saved_model.pb를 조사하여 확인할 수 있습니다.
다음 예시에서는 TPU에 __inference_serve_24라는 특정 함수를 넣는 방법을 보여줍니다.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
컴파일 시간 상수 제약조건 오류를 어떻게 해결하나요?
학습 및 추론에 모두 XLA를 사용하려면 특정 작업에 대한 입력은 TPU 컴파일 시점에 알려진 형태가 있어야 합니다. 즉, XLA가 프로그램의 TPU 부분을 컴파일할 때 이러한 작업에 대한 입력은 정적으로 알려진 형태를 가져야 합니다.
이 문제의 해결 방법은 다음 두 가지입니다.
- 가장 좋은 옵션은 XLA가 TPU 프로그램을 컴파일할 때 정적으로 알려진 형태를 갖도록 작업의 입력을 업데이트하는 것입니다. 이 컴파일은 모델의 TPU 부분이 실행되기 직전에 수행됩니다. 즉,
TpuFunction실행 시기까지 형태를 정적으로 알아야 합니다. - 또 다른 옵션은 문제가 있는 작업을 더 이상 포함하지 않도록
TpuFunction을 수정하는 것입니다.
일괄 처리 형태 오류가 발생하는 이유는 무엇인가요?
일괄 처리에는 수신 요청을 0번째 차원(일괄 차원이라고도 함)에 따라 일괄 처리할 수 있도록 하는 엄격한 형태 요구사항이 있습니다. 이러한 형태 요구사항은 TensorFlow 일괄 처리 작업에서 비롯되며 완화할 수 없습니다.
해당 요구사항을 충족하지 못하면 다음과 같은 오류가 발생합니다.
- 입력 텐서를 일괄 처리하는 데 차원이 하나 이상 있어야 합니다.
- 입력 차원이 일치해야 합니다.
- 지정된 작업 호출에서 제공되는 입력 텐서를 일괄 처리하는 차원은 0번째 차원이어야 합니다.
- 일괄 출력 텐서의 0번째 차원은 입력 텐서의 0번째 차원 크기 합계와 같지 않습니다.
이러한 요구사항을 충족하려면 일괄 처리에 다른 함수 또는 서명을 제공하는 것이 좋습니다. 이러한 요구사항을 충족하도록 기존 함수를 수정해야 할 수도 있습니다.
함수가 일괄 처리되는 경우 @tf.function의 input_signature의 형태가 모두 0번째 차원에서 None인지 확인합니다. 서명이 일괄 처리되는 경우 0번째 차원의 모든 입력에 -1이 있는지 확인합니다.
이러한 오류가 발생하는 이유와 해결 방법에 대한 자세한 설명은 일괄 처리 심층 분석을 참조하세요.
알려진 문제
TPU 함수가 다른 TPU 함수를 간접적으로 호출할 수 없음
변환기는 CPU-TPU 경계에서 대부분의 함수 호출 시나리오를 처리할 수 있지만 하나의 드문 극단적인 사례에서 실패합니다. TPU 함수가 다른 TPU 함수를 간접적으로 호출하는 경우입니다.
이는 변환기가 TPU 함수 자체 호출에서 TPU 호출 스텁 호출로 TPU 함수의 직접 호출자를 수정하기 때문입니다. 호출 스텁에는 CPU에서만 작동할 수 있는 작업이 포함됩니다. TPU 함수가 최종적으로 직접 호출자를 호출하는 함수를 호출하면 해당 CPU 작업이 TPU에서 실행될 수 있으며 이로 인해 누락된 커널 오류가 발생합니다. 이 사례는 다른 TPU 함수를 직접 호출하는 TPU 함수와 다릅니다. 이 경우 변환기는 호출 스텁을 호출하도록 두 함수를 수정하지 않으므로 작동할 수 있습니다.
변환기에서는 이러한 시나리오의 감지를 구현했습니다. 다음 오류가 표시되면 모델이 이 특이 사례에 도달한 것입니다.
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
일반적인 해결책은 이러한 함수 호출 시나리오를 피하기 위해 모델을 리팩터링하는 것입니다. 해결이 어려운 경우 Google 지원팀에 문의하여 자세히 알아보세요.
참조
Protobuf 형식의 변환기 옵션
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
일괄 처리 심층 분석
일괄 처리는 처리량과 TPU 사용률을 개선하는 데 사용됩니다. 여러 요청을 동시에 처리할 수 있습니다. 학습 중에는 tf.data를 사용하여 일괄 처리를 수행할 수 있습니다. 추론 중에는 일반적으로 수신 요청을 일괄 처리하는 그래프에 작업을 추가하면 됩니다. 이 작업은 요청이 충분하거나 제한 시간에 도달할 때까지 기다린 후에 개별 요청으로부터 대규모 배치를 생성합니다. 배치 크기 및 제한 시간을 포함하여 조정할 수 있는 다양한 일괄 처리 옵션에 대한 자세한 내용은 일괄 처리 옵션 정의를 참조하세요.

기본적으로 변환기는 TPU 연산 바로 앞에 일괄 처리 작업을 삽입합니다. 사용자 제공 TPU 함수와 모델의 기존 TPU 연산을 일괄 처리 작업으로 래핑합니다. 변환기에 일괄 처리해야 할 함수 또는 서명을 지시하여 이 기본 동작을 재정의할 수 있습니다.
다음 예시에서는 기본 일괄 처리를 추가하는 방법을 보여줍니다.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
서명 일괄 처리
서명 일괄 처리는 서명 입력에서 시작하여 서명 출력으로 이동하는 전체 모델을 일괄 처리합니다. 변환기의 기본 일괄 처리 동작과 달리 서명 일괄 처리는 TPU 계산 및 CPU 계산을 모두 일괄 처리합니다. 일부 모델에서 추론 중에 10% ~ 20%의 성능 향상을 얻을 수 있습니다.
모든 일괄 처리와 마찬가지로 서명 일괄 처리에는 엄격한 형태 요구사항이 있습니다.
이러한 형태 요구사항이 충족되도록 하려면 서명 입력에 최소 2개 차원의 형태가 있어야 합니다. 첫 번째 차원은 배치 크기입니다. 크기는 -1이어야 합니다. 예를 들어 (-1, 4), (-1), (-1,
128, 4, 10)은 모두 유효한 입력 형태입니다. 그렇게 할 수 없는 경우 기본 일괄 처리 동작 또는 함수 일괄 처리를 사용하는 것이 좋습니다.
서명 일괄 처리를 사용하려면 BatchOptions를 사용하여 서명 이름을 signature_name으로 제공합니다.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
함수 일괄 처리
함수 일괄 처리는 변환기에 일괄 처리할 함수를 알리는 데 사용할 수 있습니다. 기본적으로 변환기는 모든 TPU 함수를 일괄 처리합니다. 함수 일괄 처리는 이 기본 동작을 재정의합니다.
함수 일괄 처리는 CPU 계산을 일괄 처리하는 데 사용할 수 있습니다. 많은 모델이 CPU 계산이 일괄 처리될 때 성능이 향상됩니다. CPU 계산을 일괄 처리하는 가장 좋은 방법은 서명 일괄 처리를 사용하는 것이지만, 일부 모델에서는 작동하지 않을 수 있습니다. 이러한 경우 함수 일괄 처리를 사용하여 TPU 계산 외에도 CPU 계산의 일부를 일괄 처리할 수 있습니다. 일괄 처리 작업은 TPU에서 실행할 수 없으므로 제공되는 모든 일괄 처리 함수를 CPU에서 호출해야 합니다.
함수 일괄 처리는 일괄 처리 작업으로 적용되는 엄격한 형태 요구사항을 충족하는 데도 사용할 수 있습니다. TPU 함수가 일괄 처리 작업의 형태 요구사항을 충족하지 않는 경우 함수 일괄 처리를 사용하여 변환기에 여러 함수를 일괄 처리하도록 지시할 수 있습니다.
이를 사용하려면 일괄 처리해야 하는 함수의 function_alias를 생성합니다. 이렇게 하려면 모델에서 일괄 처리할 모든 항목을 래핑하는 함수를 찾거나 만들면 됩니다. 이 함수가 일괄 처리 작업에서 적용하는 엄격한 형태 요구사항을 충족하는지 확인하세요. @tf.function이 없으면 추가합니다.
@tf.function에 input_signature를 제공하는 것이 중요합니다. 0번째 차원은 배치 차원이므로 고정된 크기가 될 수 없기 때문에 None이어야 합니다. 예를 들어 [None, 4], [None], [None, 128, 4, 10]은 모두 유효한 입력 형태입니다. 모델을 저장할 때 아래 표시된 것과 같이 SaveOptions를 제공하여 model.batch_func에 'batch_func' 별칭을 지정합니다. 그런 다음 이 함수 별칭을 변환기에 전달할 수 있습니다.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
그 다음 BatchOptions를 사용하여 function_alias를 전달합니다.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
일괄 처리 옵션의 정의
num_batch_threads: (정수) 작업 배치를 처리하기 위한 예약 스레드 수입니다. 동시에 처리되는 배치 수를 결정합니다. 이는 사용 가능한 TPU 코어 수와 대략 일치합니다.max_batch_size: (정수) 허용되는 최대 배치 크기입니다. 대규모 배치 분할을 활용하려면allowed_batch_sizes보다 커야 합니다.batch_timeout_micros: (정수) 불완전한 배치를 출력하기 전에 기다릴 최대 마이크로초 수입니다.allowed_batch_sizes: (정수 목록) 목록이 비어 있지 않으면 목록에서 가장 가까운 크기까지 배치를 패딩합니다. 목록은 단조 증가해야 하며 최종 요소는max_batch_size이하여야 합니다.max_enqueued_batches: (정수) 요청이 빠르게 실패하기 전에 처리를 위해 큐에 추가된 최대 배치 수입니다.
기존 일괄 처리 옵션 업데이트
batch_options를 지정하고 --converter_options_string 플래그를 사용하여 disable_default_optimizations를 true로 설정하여 일괄 처리 옵션을 추가하거나 업데이트할 수 있습니다. 배치 옵션은 모든 TPU 함수 또는 기존 일괄 처리 작업에 적용됩니다.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
형태 요구사항 일괄 처리
배치는 배치(0번째) 차원에 따라 요청 간에 입력 텐서를 연결하여 생성됩니다. 출력 텐서가 0번째 차원에 따라 분할됩니다. 이러한 작업을 수행하려면 일괄 처리 작업의 입력과 출력에 엄격한 형태 요구사항이 있어야 합니다.
둘러보기
이러한 요구사항을 이해하려면 먼저 일괄 처리 수행 방법을 이해하면 도움이 됩니다. 아래 예시에서는 간단한 tf.matmul 작업을 일괄 처리합니다.
def my_func(A, B) return tf.matmul(A, B)
첫 번째 추론 요청은 각각 (1, 3,
2) 및 (1, 2, 4) 형태를 사용해서 입력 A와 B를 생성합니다. 두 번째 추론 요청은 (2, 3, 2) 및 (2, 2, 4) 형태를 사용해서 입력 A와 B를 생성합니다.

일괄 처리 제한 시간에 도달했습니다. 모델은 배치 크기 3을 지원하므로 추론 요청 1과 2는 패딩 없이 함께 일괄 처리됩니다. 일괄 처리된 텐서는 배치(0번째) 차원에 따라 요청 1과 2를 연결하여 형성됩니다. 요청 1의 A는 (1, 3, 2) 형태를 갖고 요청 2의 A는 (2, 3, 2) 형태를 가지므로 배치(0번째) 차원을 따라 연결하면 결과 형태는 (3, 3, 2)가 됩니다.
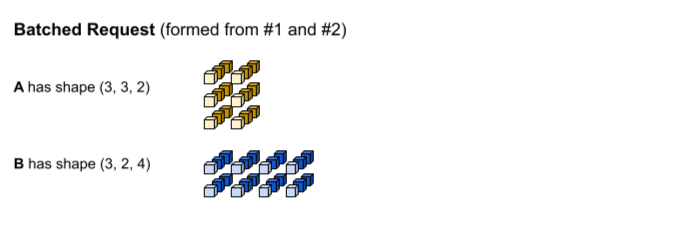
tf.matmul이 실행되고 (3, 3,
4) 형태의 출력을 생성합니다.

tf.matmul 출력은 일괄 처리되므로 다시 개별 요청으로 분할해야 합니다. 일괄 처리 작업은 각 출력 텐서의 배치(0번째) 차원을 따라 분할하여 이를 수행합니다. 원본 입력의 형태에 따라 0번째 차원을 분할하는 방법이 결정됩니다. 요청 1의 형태는 0번째 차원이 1이기 때문에 출력은 (1, 3, 4) 형태에서 0번째 차원이 1입니다.
요청 2의 형태는 0번째 차원이 2이기 때문에 출력은 (2, 3, 4) 형태에서 0번째 차원이 2입니다.

형태 요구사항
위에 설명된 입력 연결 및 출력 분할을 수행하려면 일괄 처리 작업에 다음과 같은 형태 요구사항이 있어야 합니다.
일괄 처리에 대한 입력은 스칼라일 수 없습니다. 0번째 차원을 따라 연결하려면 텐서에 2개 이상의 차원이 있어야 합니다.
위의 둘러보기에서 확인할 수 있습니다. A와 B 모두 스칼라가 아닙니다.
이 요구사항을 충족하지 못하면
Batching input tensors must have at least one dimension과 같은 오류가 발생합니다. 이 오류의 간단한 해결 방법은 스칼라를 벡터로 만드는 것입니다.여러 추론 요청(예: 다양한 세션 실행 호출)에서 이름이 같은 입력 텐서는 0번째 차원을 제외하고 각 차원에 대해 크기가 동일합니다. 이렇게 하면 0번째 차원을 따라 입력을 깔끔하게 연결할 수 있습니다.
위 둘러보기에서 요청 1의 A에 대한 형태는
(1, 3, 2)입니다. 즉, 이후의 모든 요청은(X, 3, 2)패턴을 사용하여 형태를 생성해야 합니다. 요청 2는(2, 3, 2)로 이 요구사항을 충족합니다. 마찬가지로 요청 1의 B는(1, 2, 4)형태를 가지므로 이후의 모든 요청은(X, 2, 4)패턴으로 형태를 생성해야 합니다.이 요구사항을 충족하지 못하면
Dimensions of inputs should match와 같은 오류가 발생합니다.특정 추론 요청의 경우 모든 입력은 동일한 0번째 차원 크기를 가져야 합니다. 일괄 처리 작업의 다양한 입력 텐서에서 0차원이 다른 경우 일괄 처리 작업은 출력 텐서를 분할하는 방법을 알 수 없습니다.
위 둘러보기에서 요청 1의 텐서 모두 0번째 차원 크기는 1입니다. 이렇게 하면 일괄 처리 작업은 출력의 0번째 차원 크기가 1이어야 한다는 점을 알 수 있습니다. 마찬가지로 요청 2의 텐서의 0번째 차원 크기는 2이므로 출력의 0번째 차원 크기는 2입니다. 일괄 처리 작업에서
(3, 3, 4)의 최종 형태를 분할하면 요청 1의 경우(1, 3, 4), 요청 #2의 경우(2, 3, 4)를 생성합니다.이 요구사항을 충족하지 못하면
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size와 같은 오류가 발생합니다.각 출력 텐서 형태의 0번째 차원 크기는 모든 입력 텐서의 0번째 차원 크기(다음으로 가장 큰
allowed_batch_size를 충족하기 위해 일괄 처리 작업에서 도입하는 모든 패딩 포함)의 합계여야 합니다. 이렇게 하면 일괄 처리 작업이 입력 텐서의 0번째 차원을 기준으로 0번째 차원에 따라 출력 텐서를 분할할 수 있습니다.위 둘러보기에서 입력 텐서는 요청 1에서 1, 요청 2에서 2의 0번째 차원을 갖습니다. 따라서 1+2=3이므로 각 출력 텐서의 0차원은 3이어야 합니다. 출력 텐서
(3, 3, 4)가 이 요구사항을 충족합니다. 3이 유효한 배치 크기가 아니고 4가 유효한 경우 일괄 처리 작업은 입력의 0번째 차원을 3에서 4로 패딩해야 했습니다. 이 경우 각 출력 텐서는 0번째 차원 크기인 4를 가져야 합니다.이 요구사항을 충족하지 못하면
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors와 같은 오류가 발생합니다.
형태 요구사항 오류 해결
이러한 요구사항을 충족하려면 일괄 처리에 다른 함수 또는 서명을 제공하는 것이 좋습니다. 이러한 요구사항을 충족하도록 기존 함수를 수정해야 할 수도 있습니다.
함수가 일괄 처리되는 경우 @tf.function의 input_signature의 형태가 모두 0번째 차원(배치 차원이라고도 함)에서 None인지 확인합니다. 서명이 일괄 처리되는 경우 0번째 차원의 모든 입력에 -1이 있는지 확인합니다.
BatchFunction 작업은 입력 또는 출력으로 SparseTensors를 지원하지 않습니다.
내부적으로 각 희소 텐서는 서로 다른 0번째 차원 크기를 가질 수 있는 3개의 개별 텐서로 표현됩니다.