Introduzione
La previsione e il rilevamento di anomalie su miliardi di serie temporali richiede un calcolo intensivo. La maggior parte dei sistemi esistenti esegue la previsione e il rilevamento delle anomalie come job batch (ad esempio pipeline di rischio, previsione del traffico, pianificazione della domanda e così via). Ciò limita notevolmente il tipo di analisi che puoi eseguire online, ad esempio decidere se inviare un avviso in base a un aumento o una diminuzione improvvisi in un insieme di dimensioni evento.
Gli obiettivi principali dell'API Timeseries Insights sono:
- Esegui lo scale fino a miliardi di serie temporali costruite dinamicamente da eventi non elaborati e dalle relative proprietà, in base ai parametri di query.
- Fornire risultati di previsione e rilevamento di anomalie in tempo reale. In altre parole, in pochi secondi, rileva le tendenze e la stagionalità per tutte le serie temporali e decidi se le sezioni sono in aumento o in diminuzione in modo imprevisto.
Funzionalità dell'API
- Gestire i set di dati
- Indicizzare e caricare un set di dati composto da più origini dati archiviate su Cloud Storage. Consente di aggiungere nuovi eventi in streaming.
- Scaricare un set di dati non più necessario.
- Chiedi lo stato di elaborazione di un set di dati.
- Esegui query sui set di dati
- Recupera la serie temporale corrispondente ai valori della proprietà specificati. La serie temporale viene prevista fino a un orizzonte temporale specificato. La serie temporale viene anche valutata per rilevare eventuali anomalie.
- Rileva automaticamente combinazioni di valori delle proprietà per rilevare anomalie.
- Aggiorna i set di dati
- Importa i nuovi eventi avvenuti di recente e incorporali nell'indice quasi in tempo reale (con un ritardo di pochi secondi o minuti).
Ripristino di emergenza
L'API Timeseries Insights non funge da backup per Cloud Storage né restituisce aggiornamenti non elaborati in streaming. I clienti sono responsabili di archiviare e eseguire il backup dei dati separatamente.
Dopo un'interruzione a livello di regione, il servizio esegue un ripristino secondo il criterio del "best effort". I metadati (informazioni sul set di dati e sullo stato operativo) e i dati utente in streaming aggiornati entro 24 ore dall'inizio dell'interruzione potrebbero non essere recuperati.
Durante il recupero, le query e gli aggiornamenti in streaming dei set di dati potrebbero non essere disponibili.
Dati di input
È normale che i dati numerici e categorici vengano raccolti nel tempo. Ad esempio, la figura seguente mostra l'utilizzo della CPU, l'utilizzo della memoria e lo stato di un singolo job in esecuzione in un data center ogni minuto per un determinato periodo di tempo. L'utilizzo della CPU e della memoria sono valori numerici e lo stato è un valore categorico.
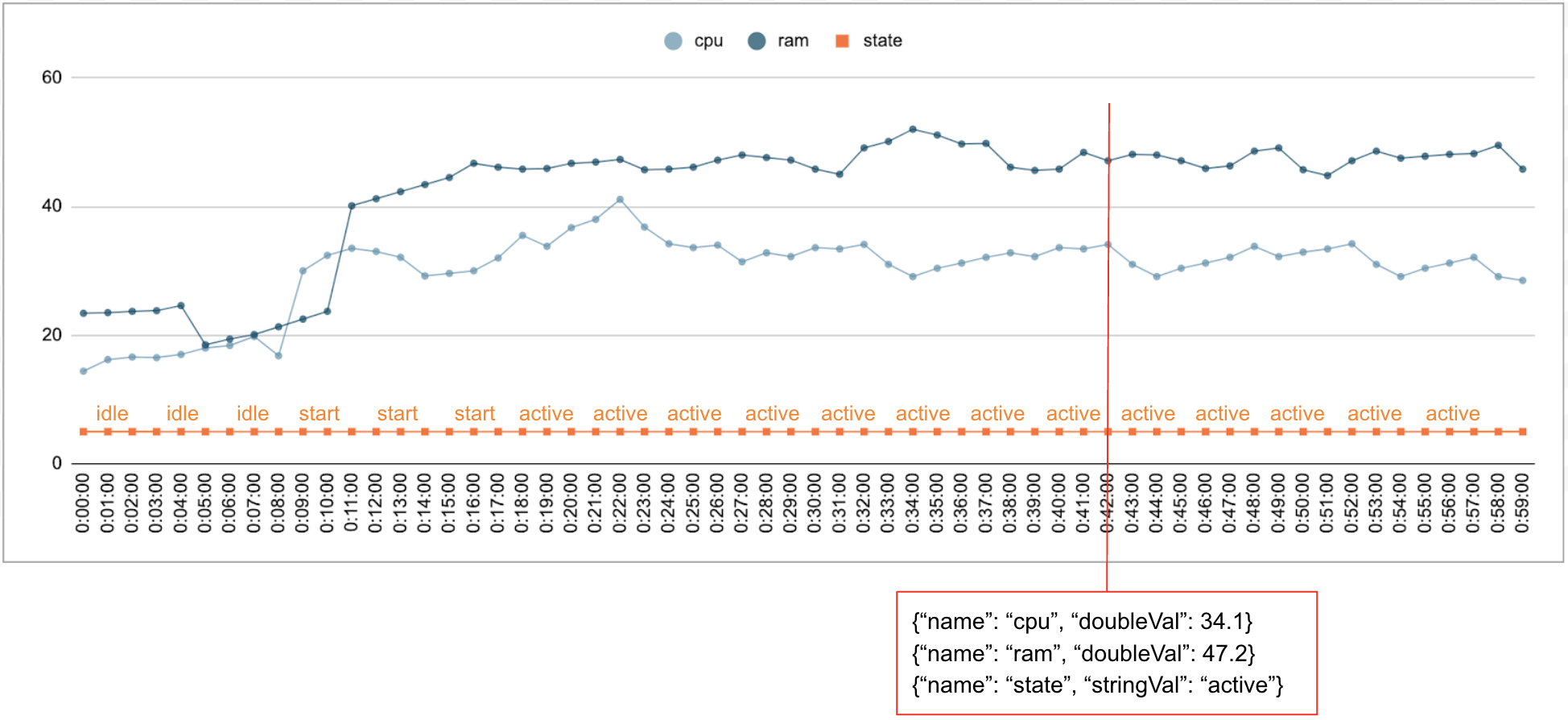
Evento
L'API Timeseries Insights utilizza gli eventi come voce di dati di base. Ogni evento ha un timestamp e una raccolta di dimensioni, ovvero coppie chiave/valore in cui la chiave è il nome della dimensione. Questa semplice rappresentazione ci consente di gestire dati su scala di trilioni. Ad esempio, il data center, l'utente, i nomi dei job e i numeri delle attività vengono inclusi per rappresentare completamente un singolo evento. La figura sopra mostra una serie di eventi registrati per un singolo job che illustra un sottoinsieme di dimensioni.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
Un DataSet è una raccolta di eventi. Le query vengono eseguite nello stesso set di dati. Ogni progetto può avere più set di dati.
Un set di dati viene creato a partire da dati in batch e in streaming. La creazione di dati batch legge da più URI Cloud Storage come origini dati. Al termine della compilazione collettiva, il set di dati può essere aggiornato con i dati in streaming. Utilizzando la compilazione batch per i dati storici, il sistema può evitare i problemi di avvio a freddo.
Un set di dati deve essere creato o indicizzato prima di poter essere sottoposto a query o aggiornato. L'indicizzazione inizia al momento della creazione del set di dati e in genere richiede da alcuni minuti a diverse ore, a seconda della quantità di dati. Nello specifico, le origini dati vengono sottoposte a scansione una volta durante l'indicizzazione iniziale. Se i contenuti degli URI Cloud Storage cambiano al termine dell'indicizzazione iniziale, non vengono sottoposti nuovamente a scansione. Utilizza gli aggiornamenti in streaming per dati aggiuntivi. Gli aggiornamenti in streaming vengono indicizzati continuamente quasi in tempo reale.
Serie temporali e rilevamento di anomalie
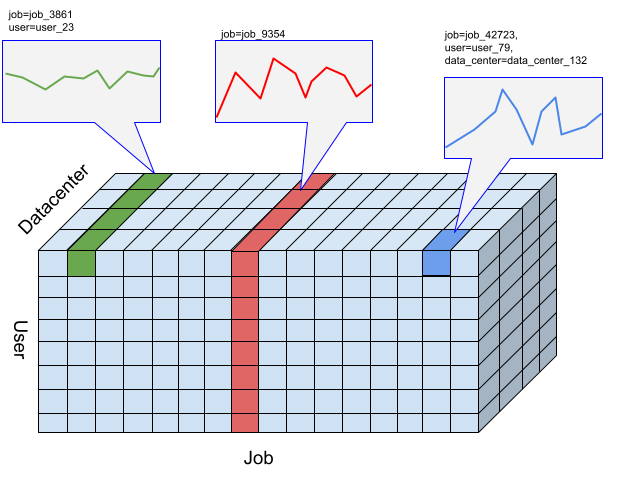
Per l'API Timeseries Insights, un sezionamento è una raccolta di eventi con una determinata combinazione di valori delle dimensioni. Siamo interessati a misurare gli eventi che rientrano in questi intervalli nel tempo.
Per un determinato intervallo, gli eventi vengono aggregati in valori numerici in base alla risoluzione specificata dall'utente degli intervalli di tempo, ovvero le serie temporali per rilevare le anomalie. La figura precedente mostra diverse scelte di slice risultanti da diverse combinazioni delle dimensioni "user", "job" e "data_center".
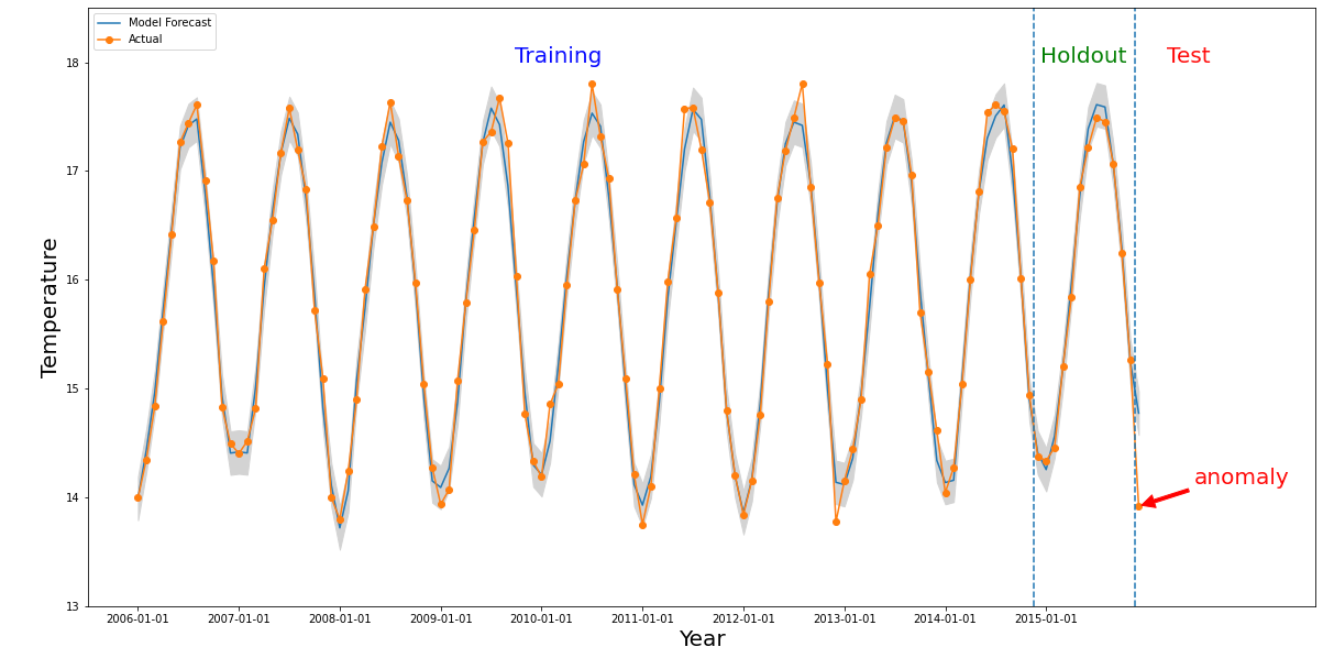
Un'anomalia si verifica per una determinata sezione se il valore numerico dell'intervallo di tempo di interesse è nettamente diverso dai valori del passato. La figura sopra illustra una serie temporale basata sulle temperature misurate in tutto il mondo in più di 10 anni. Supponiamo che siamo interessati a sapere se l'ultimo mese del 2015 è un'anomalia. Una query al sistema specifica la data di interesse,
detectionTime, come "01/12/2015" e granularity come "1 mese". La serie temporale recuperata prima del giorno detectionTime viene suddivisa in un periodo di addestramento precedente seguito da un periodo di holding. Il sistema utilizza i dati del periodo di addestramento per addestrare un modello e utilizza il periodo di conservazione per verificare che il modello possa prevedere in modo affidabile i valori successivi. Per questo esempio, il periodo di blocco è di 1 anno. L'immagine mostra i dati effettivi e i valori previsti del
modello con i limiti superiore e inferiore. La temperatura per il 12/12 è contrassegnata come erronea perché il valore effettivo è al di fuori dei limiti previsti.