Introdução
A previsão e a deteção de anomalias em milhares de milhões de séries cronológicas são computacionalmente intensivas. A maioria dos sistemas existentes executa a previsão e a deteção de anomalias como tarefas em lote (por exemplo, pipelines de risco, previsão de tráfego, planeamento da procura, etc.). Isto limita severamente o tipo de análise que pode realizar online, como decidir se deve emitir um alerta com base num aumento ou numa diminuição súbita num conjunto de dimensões de eventos.
Os principais objetivos da API Timeseries Insights são:
- Escalar para milhares de milhões de séries cronológicas construídas dinamicamente a partir de eventos não processados e das respetivas propriedades, com base nos parâmetros de consulta.
- Fornecer resultados de previsão e deteção de anomalias em tempo real. Ou seja, em poucos segundos, detetar tendências e sazonalidade em todas as séries cronológicas e decidir se alguma fatia está a aumentar ou a diminuir inesperadamente.
Funcionalidade da API
- Faça a gestão dos conjuntos de dados
- Indexe e carregue um conjunto de dados composto por várias origens de dados armazenadas no Cloud Storage. Permitir a anexação de novos eventos de forma contínua.
- Descarregue um conjunto de dados de que já não precisa.
- Pedir o estado de processamento de um conjunto de dados.
- Consultar conjuntos de dados
- Recupere a série cronológica que corresponde aos valores de propriedade especificados. A série cronológica é prevista até um horizonte temporal especificado. A série cronológica também é avaliada quanto a anomalias.
- Detetar automaticamente combinações de valores de propriedades para anomalias.
- Atualize conjuntos de dados
- Carregar novos eventos ocorridos recentemente e incorporá-los no índice em tempo quase real (atraso de segundos a minutos).
Recuperação de desastres
A API Timeseries Insights não funciona como uma cópia de segurança do Cloud Storage nem devolve atualizações de streaming não processadas. Os clientes são responsáveis por armazenar e fazer cópias de segurança dos dados separadamente.
Após uma interrupção regional, o serviço faz uma recuperação com base no melhor esforço. Os metadados (informações sobre o conjunto de dados e o estado operacional) e os dados de utilizadores transmitidos atualizados no prazo de 24 horas após o início da indisponibilidade podem não ser recuperados.
Durante a recuperação, as consultas e as atualizações de streaming aos conjuntos de dados podem não estar disponíveis.
Dados de entrada
É comum que os dados numéricos e de categoria sejam recolhidos ao longo do tempo. Por exemplo, a figura seguinte mostra a utilização da CPU, a utilização da memória e o estado de uma única tarefa em execução num centro de dados a cada minuto durante um período. A utilização da CPU e a utilização da memória são valores numéricos, e o estado é um valor categórico.
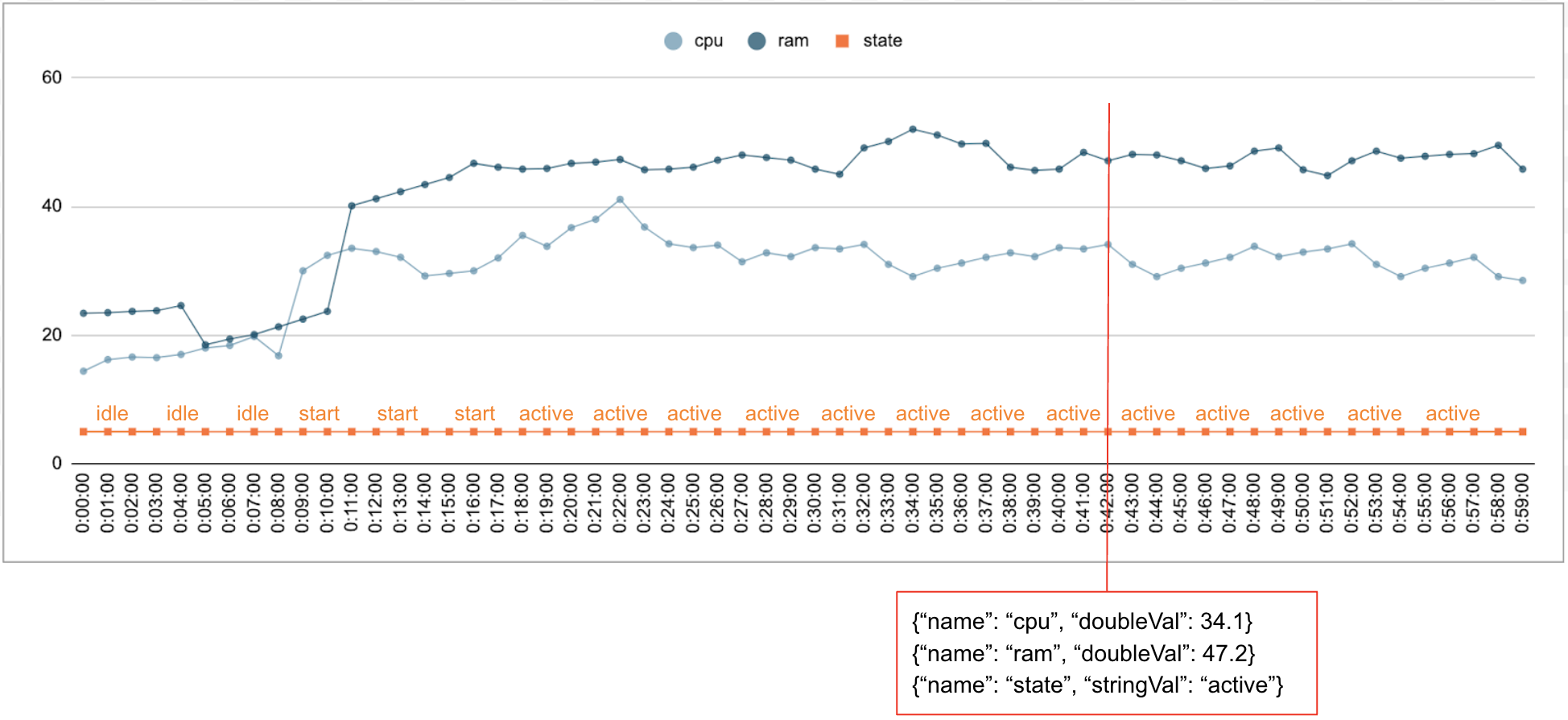
Evento
A API Timeseries Insights usa eventos como a entrada de dados básica. Cada evento tem uma data/hora e uma coleção de dimensões, ou seja, pares de chave-valor em que a chave é o nome da dimensão. Esta representação simples permite-nos processar dados à escala de biliões. Por exemplo, o centro de dados, o utilizador, os nomes das tarefas e os números das tarefas são incluídos para representar totalmente um único evento. A figura acima mostra uma série de eventos registados para uma única tarefa que ilustra um subconjunto de dimensões.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
DataSet
Um DataSet é uma coleção de eventos. As consultas são realizadas no mesmo conjunto de dados. Cada projeto pode ter vários conjuntos de dados.
Um conjunto de dados é criado a partir de dados em lote e por streaming. Ler dados em lote de vários URIs do Cloud Storage como origens de dados. Depois de a criação em lote estar concluída, o conjunto de dados pode ser atualizado com dados de streaming. Ao usar a compilação em lote para dados do histórico, o sistema pode evitar problemas de arranque a frio.
É necessário criar ou indexar um conjunto de dados antes de poder ser consultado ou atualizado. A indexação começa quando o conjunto de dados é criado e, normalmente, demora minutos a horas a ser concluída, consoante a quantidade de dados. Mais especificamente, as origens de dados são analisadas uma vez durante a indexação inicial. Se o conteúdo dos URI do Google Cloud Storage for alterado após a conclusão da indexação inicial, não é analisado novamente. Use atualizações de streaming para dados adicionais. As atualizações de streaming são indexadas continuamente quase em tempo real.
Séries cronológicas e deteção de anomalias
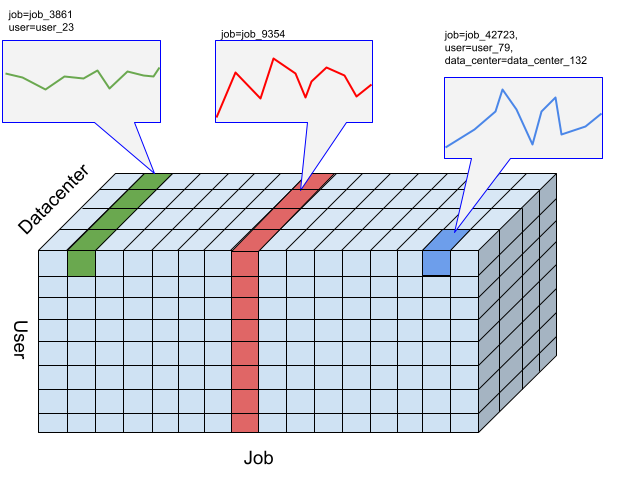
Para a API Timeseries Insights, uma divisão é uma coleção de eventos com uma determinada combinação de valores de dimensões. Estamos interessados numa medida dos eventos que se enquadram nestes segmentos ao longo do tempo.
Para uma determinada fatia, os eventos são agregados em valores numéricos por resolução de intervalos de tempo especificada pelo utilizador, que são as séries cronológicas para detetar anomalias. A figura anterior ilustra diferentes escolhas de fatias resultantes de diferentes combinações das dimensões "user", "job" e "data_center".
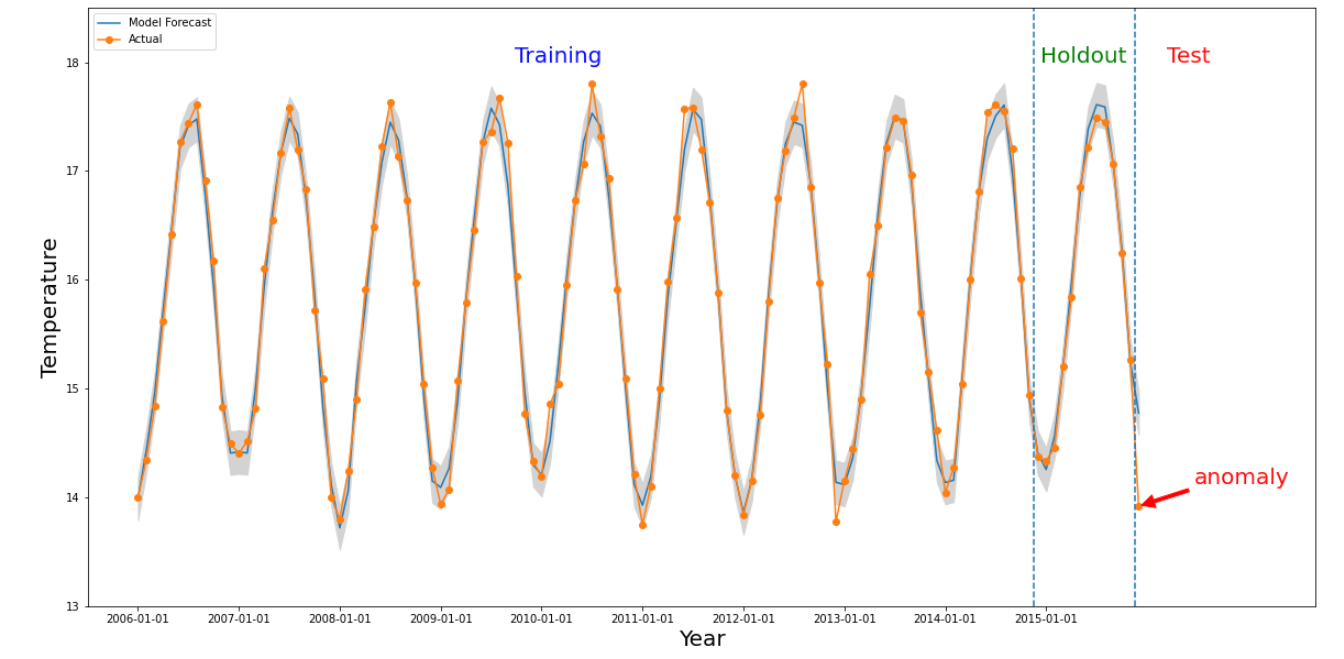
Ocorre uma anomalia para uma determinada fatia se o valor numérico do intervalo de tempo de interesse for significativamente diferente dos valores no passado. A figura acima ilustra um intervalo temporal com base nas temperaturas medidas em todo o mundo ao longo de 10 anos. Suponhamos que temos interesse em saber se o último mês de 2015 é uma anomalia. Uma consulta ao sistema especifica a hora de interesse,
detectionTime, como "2015/12/01" e o granularity como "1 mês". A série cronológica obtida antes do detectionTime é dividida num período de preparação anterior seguido de um período de retenção. O sistema usa dados do período de preparação para preparar um modelo e usa o período de retenção para verificar se o modelo consegue prever os valores seguintes de forma fiável. Para este exemplo, o período de
retenção é de 1 ano. A imagem mostra os dados reais e os valores previstos do modelo com limites superior e inferior. A temperatura para 2015/12 está marcada como
anomalia porque o valor real está fora dos limites previstos.