本文档介绍了如何使用 Cloud SQL 中的 AI 辅助功能来排查 Cloud SQL 中的高数据库负载问题。您可以使用 Cloud SQL 和 Gemini Cloud Assist 的 AI 辅助功能来调查、分析、获取建议,并最终实施这些建议,以优化 Cloud SQL 中的查询。
通过访问 Google Cloud 控制台中的Query Insights信息中心,您可以分析数据库并在系统遇到高于平均水平的数据库负载时排查事件。Cloud SQL 会使用所选时间范围之前 24 小时的数据来计算数据库的预期负载。您可以调查高负载事件的原因,并分析性能下降背后的证据。最后,Cloud SQL 会提供一些建议,以便您优化数据库以提升性能。
准备工作
如需借助 AI 辅助功能排查数据库负载过高问题,请执行以下操作:
所需的角色和权限
如需了解借助 AI 辅助功能排查数据库负载过高问题所需的角色和权限,请参阅借助 AI 观察和排查问题。
使用 AI 辅助功能
如需使用 AI 辅助功能排查数据库负载过高问题,请在 Google Cloud 控制台中前往实例概览页面或Query Insights信息中心。
实例概览页面
如需在实例概览页面内借助 AI 辅助功能排查数据库负载过高问题,请按以下步骤操作:
-
在 Google Cloud 控制台中,前往 Cloud SQL 实例页面。
- 如需打开实例的概览页面,请点击实例名称。
- 在概览页面中,从图表菜单中选择数据库的指标。您可以选择任何指标。
- 可选:如需选择特定的分析时间段,请使用时间范围过滤条件选择 1 小时、6 小时、1 天、7 天、30 天或自定义范围。
- 点击分析实例性能,开始借助 AI 辅助功能排查数据库负载过高问题。这会生成分析数据库负载页面。
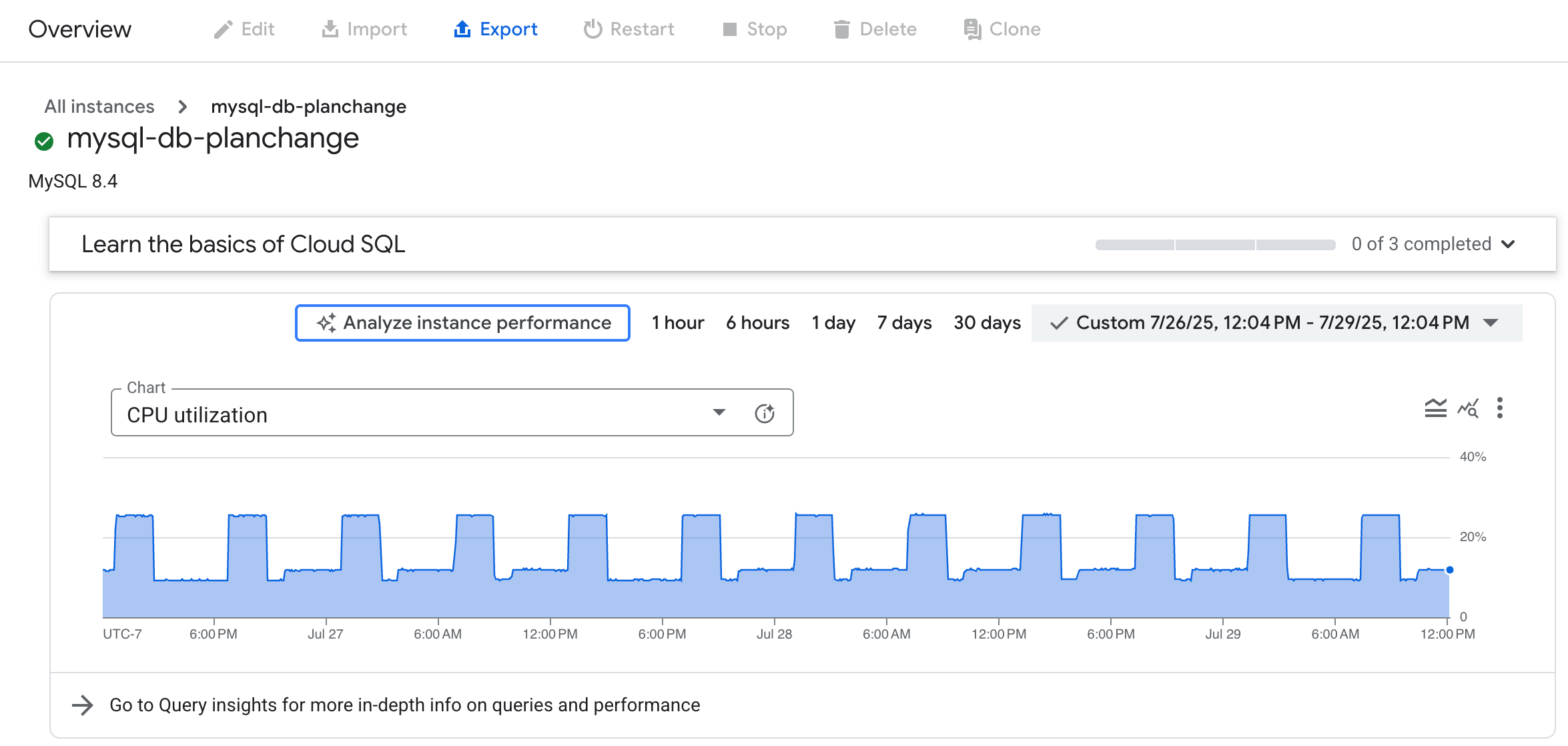
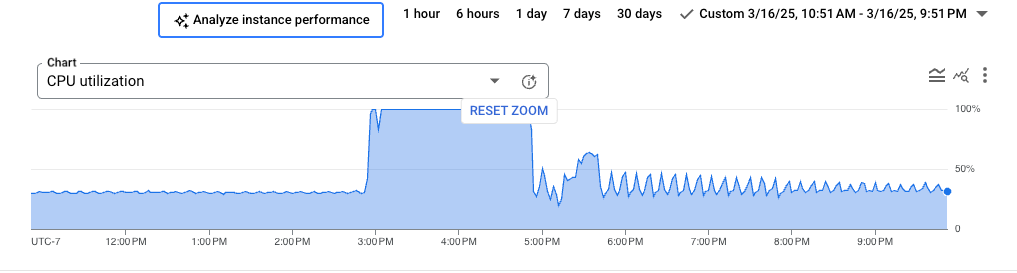
您可以放大图表的特定部分,以便分析您发现的高负载区域。例如,高负载区域可能会显示接近 100% 的 CPU 利用率。 如需放大图表,请点击并选择图表的一部分。
Query Insights 信息中心
如需在Query Insights信息中心内借助 AI 辅助功能排查数据库负载过高问题,请按以下步骤操作:
-
在 Google Cloud 控制台中,前往 Cloud SQL 实例页面。
- 如需打开实例的概览页面,请点击实例名称。
- 点击查询数据分析以打开查询数据分析信息中心。
- 可选:使用时间范围过滤条件选择 1 小时、6 小时、1 天、7 天、30 天或自定义范围。
- 在数据库负载图表中,点击分析实例性能,开始借助 AI 辅助功能排查数据库负载过高问题。 这会生成分析数据库负载页面。
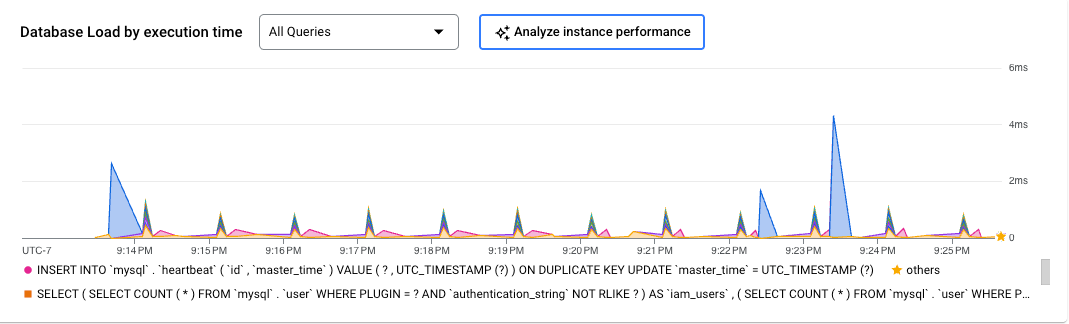
您可以放大图表的特定部分,以便查看查询执行时间较高的数据库负载区域。 如需放大图表,请点击并选择图表的一部分。
分析数据库负载过高的情况
借助 AI 辅助功能,您可以对数据库负载的详细信息进行分析和问题排查。
在分析数据库负载页面中,您可以查看 Cloud SQL 实例的以下详细信息:
- 分析时间段
- CPU 利用率 (p99)
- 内存利用率 (p99)
Cloud SQL 会显示一个 MySQL 查询图表,您可以在其中查看所选时间段内的查询活动。您可以检查特定时间段内的活动是否突然激增。
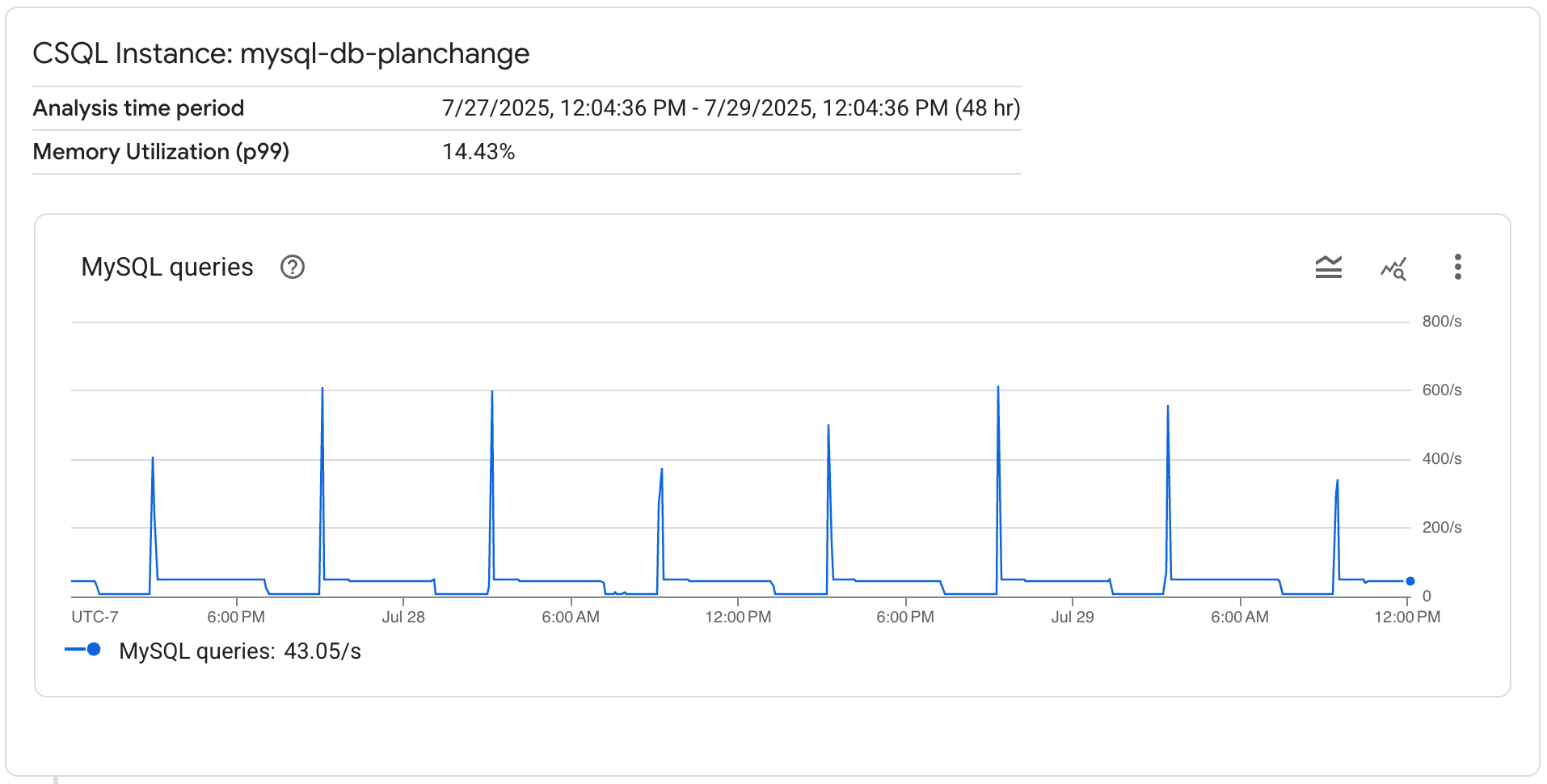
分析时间段
Cloud SQL 会分析您在Query Insights信息中心或实例概览页面的数据库负载图表中选择的时间段内的数据库。如果您选择的时间段不足 24 小时,Cloud SQL 会分析整个时间段。如果您选择的时间段超过 24 小时,Cloud SQL 将仅选择该时间段的最后 24 小时进行分析。
为了计算数据库的基准性能分析,Cloud SQL 会在分析时间段内纳入 24 小时的基准时间段。如果您选择的时间段不是从周一开始的,那么 Cloud SQL 会使用所选时间段前 24 小时作为基准时间段。如果您选择的时间段是周一,则 Cloud SQL 会使用所选时间段前 7 天作为基准时间段。
情况
当 Cloud SQL 开始分析时,会检查以下关键指标是否存在重大变化:
- 每秒查询次数 (QPS)
- CPU
- 内存
- 磁盘 I/O
Cloud SQL 会将数据库的基准汇总数据与分析时间窗口的性能数据进行比较。如果 Cloud SQL 检测到关键指标的阈值发生了显著变化,则 Cloud SQL 会指示数据库可能存在问题。系统识别出的情况可能说明了所选时间段内数据库负载过高的根本原因。
例如,您可能会看到系统识别出多种导致数据库负载过高的原因:
- 线程并发数过多
- CPU 利用率发生显著变化
- 磁盘 IOPS 发生显著变化
- QPS 发生显著变化
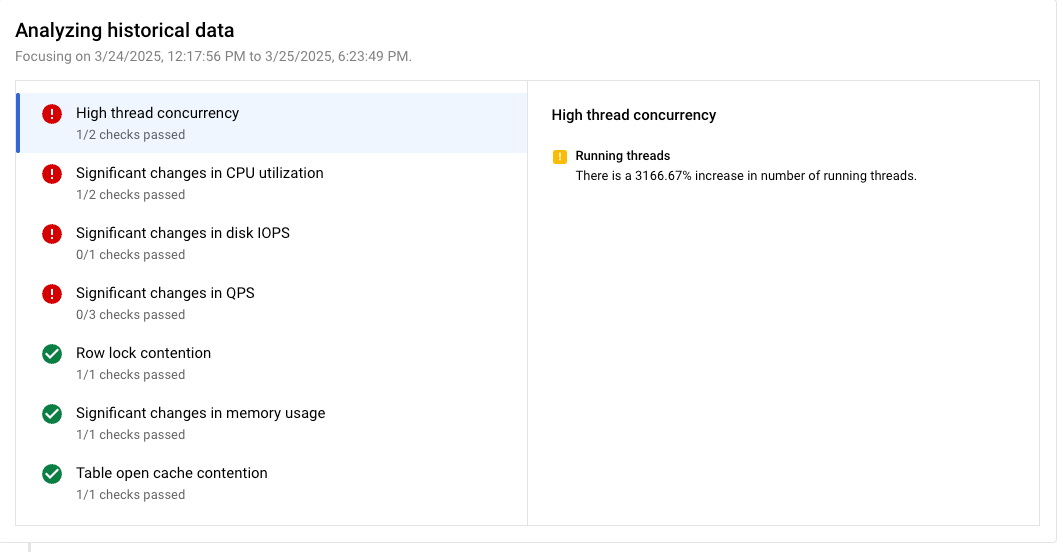
证据
对于每种情况,Cloud SQL 都会提供一系列证据来支持发现结果。Cloud SQL 会根据从实例收集的指标来确定证据。
每种情况都有支持性证据,用于检测系统性能方面的异常。当系统性能超出特定阈值或符合特定时限条件时,Cloud SQL 会检测到异常情况。Cloud SQL 会针对每种情况定义这些阈值或条件。
为了支持检测到关键指标发生显著变化的情况,您可能会看到以下证据:
- 总 QPS:平均值从 18,534.22 更改为 37,619.86,p20 从 3.55 更改为 5.45,p80 从 5.62 更改为 112,050.8。
- 读取 QPS:平均值从 1,802.98 更改为 3,657.93,p20 从 1.17 更改为 2.1,p80 从 2.12 更改为 10,908.8。
- 写入 QPS:平均值从 1,751.61 更改为 3,553.48,p20 从 0.2 更改为 0.2,p80 从 0.2 更改为 10,600.13。
- CPU 使用率发生变化:检测到 CPU 利用率发生了显著变化。 平均值变化幅度为 183.85%。p80 变化幅度为 2,630.49%。p20 变化幅度为 6.75%。
- 磁盘 IOPS:检测到磁盘 IOPS 发生了显著变化。 平均值变化幅度为 173.39%。p80 变化幅度为 20,832.44%。p20 变化幅度为 1.88%。
- 正在运行的线程数:正在运行的线程数增加了 3,166.67%。
如需查看分析期间检索到的证据,请点击每种情况。 证据会显示在相应情况旁边的窗格中。
建议
根据分析的所有情况,Cloud SQL 会为您提供一个或多个切实可行的建议,帮助您解决数据库负载过高的问题。Cloud SQL 会通过成本效益分析来提供建议,以便您据此做出是否实施建议的明智决策。
在某些情况下,根据分析结果,可能不会提供建议。

例如,您可能会收到以下建议:
查看并发工作负载:使用Query Insights分析过去和当前的工作负载。
- 当 CPU 使用率增加时,请关注最耗资源的查询,以确定潜在的低效问题。
- 当 CPU 使用率降低时,请查看等待事件,以确定潜在的争用情况。
查看与 IO 相关的数据库标志:数据库标志修改可能会导致磁盘 IOPS 波动。
一些可能影响 IOPS 的关键标志包括但不限于:
innodb_buffer_pool_sizeinnodb_redo_log_capacityinnodb_io_capacityinnodb_flush_neighborsinnodb_lru_scan_depthtemptable_max_ram
查看这些设置有助于确定 IO 变化的潜在原因。
查看其他 IO 指标:如需更好地了解 IOPS 的变化,请分析以下系统分析洞见指标:
Disk read/write operationsRead/write InnoDB pages
此外,还可以在 Metrics Explorer 中查看其他 InnoDB I/O 指标。
如果您想继续排查问题或在系统性能方面获得更多帮助,也可以打开 Gemini Cloud Assist。如需了解详情,请参阅使用 AI 辅助功能进行观测并排查问题。