En este tema se muestra cómo medir la k-anonimato de un conjunto de datos con Protección de Datos Sensibles y cómo visualizarlo en Looker Studio. De esta forma, también podrás comprender mejor los riesgos y evaluar las ventajas y desventajas que pueden surgir si redactas o anonimizas datos.
.Aunque este tema se centra en la visualización de la métrica de análisis de riesgo de reidentificación k-anonymity, también puede visualizar la métrica l-diversity con los mismos métodos.
En este tema se da por hecho que ya conoces el concepto de k-anonimato y su utilidad para evaluar la posibilidad de reidentificar registros en un conjunto de datos. También te será útil tener al menos cierta familiaridad con cómo calcular la k-anonimato con Protección de Datos Sensibles y con el uso de Looker Studio.
Introducción
Las técnicas de desidentificación pueden ser útiles para proteger la privacidad de los interesados mientras procesas o usas los datos. Pero ¿cómo sabes si un conjunto de datos se ha desidentificado lo suficiente? ¿Y cómo sabrá si la anonimización ha provocado una pérdida de datos excesiva para su caso práctico? Es decir, ¿cómo puedes comparar el riesgo de reidentificación con la utilidad de los datos para tomar decisiones basadas en datos?
Calcular el valor de k-anonymity de un conjunto de datos ayuda a responder estas preguntas al evaluar la posibilidad de reidentificar los registros del conjunto de datos. Protección de Datos Sensibles incluye funciones integradas para calcular el valor de k-anonimato de un conjunto de datos en función de los cuasidentificadores que especifiques. De esta forma, puede evaluar rápidamente si la anonimización de una columna o una combinación de columnas concretas dará como resultado un conjunto de datos con más o menos probabilidades de ser reidentificado.
Conjunto de datos de ejemplo
A continuación se muestran las primeras filas de un conjunto de datos de ejemplo grande.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
En este tutorial no se tratará el tema de user_id, ya que nos centraremos en los cuasiidentificadores. En un caso práctico, deberías asegurarte de que user_id se oculte o de que se tokenice correctamente. La columna score es propiedad de este conjunto de datos y es poco probable que un atacante pueda obtenerla por otros medios, por lo que no la incluirá en el análisis. Te centrarás en las columnas age y title restantes, con las que un atacante podría obtener información sobre una persona a través de otras fuentes de datos. Las preguntas que intentas responder sobre el conjunto de datos son las siguientes:
- ¿Qué efecto tendrán los dos cuasi-identificadores (
ageytitle) en el riesgo general de reidentificación de los datos desidentificados? - ¿Cómo afectará la aplicación de una transformación de anonimización a este riesgo?
Quieres asegurarte de que la combinación de age y title no se asigne a un número reducido de usuarios. Por ejemplo, supongamos que solo hay un usuario en el conjunto de datos cuyo cargo es Programador I y que tiene 69 años. Un atacante podría cruzar esa información con datos demográficos u otra información disponible, averiguar quién es la persona y conocer el valor de su puntuación.
Para obtener más información sobre este fenómeno, consulte la sección IDs de entidad y cálculo de la k-anonimatodel tema conceptual Análisis de riesgos.
Paso 1: Calcula k-anonymity en el conjunto de datos
Primero, usa Protección de Datos Sensibles para calcular la k-anonimato del conjunto de datos enviando el siguiente JSON al recurso DlpJob. En este JSON, asigna el ID de entidad a la columna user_id e identifica los dos cuasi-identificadores como las columnas age y title. También le indicas a Protección de Datos Sensibles que guarde los resultados en una tabla de BigQuery.
Entrada JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}Una vez que se haya completado el trabajo de k-anonimato, Protección de Datos Sensibles enviará los resultados del trabajo a una tabla de BigQuery llamada dlp-demo-2.dlp_testing.test_results.
Paso 2: Conecta los resultados a Looker Studio
A continuación, conectará la tabla de BigQuery que ha creado en el paso 1 a un nuevo informe de Looker Studio.
Abre Looker Studio.
Haz clic en Crear > Informe.
En el panel Añadir datos al informe, en Conectar con datos, haga clic en BigQuery. Es posible que tengas que autorizar a Looker Studio para que acceda a tus tablas de BigQuery.
En el selector de columnas, selecciona Mis proyectos. A continuación, elige el proyecto, el conjunto de datos y la tabla. Cuando hayas terminado, haz clic en Añadir. Si ves un aviso que indica que vas a añadir datos a este informe, haz clic en Añadir al informe.
Los resultados del análisis de k-anonimato se han añadido al nuevo informe de Looker Studio. En el siguiente paso, crearás el gráfico.
Paso 3: Crea el gráfico
Para insertar y configurar el gráfico, siga estos pasos:
- En Looker Studio, si aparece una tabla de valores, selecciónala y pulsa Suprimir para quitarla.
- En el menú Insertar, haz clic en Gráfico combinado.
- Haz clic y dibuja un rectángulo en el lienzo donde quieras que aparezca el gráfico.
A continuación, configure los datos del gráfico en la pestaña Datos para que el gráfico muestre el efecto de variar el tamaño y los intervalos de valores de los contenedores:
- Borra los campos de los siguientes encabezados colocando el cursor sobre cada campo
y haciendo clic en la X, como se muestra aquí:
- Dimensión de periodo
- Dimensión
- Métrica
- Ordenar
- Con todos los campos borrados, arrastra el campo upper_endpoint de la columna Campos disponibles al encabezado Dimensión.
- Arrastra el campo upper_endpoint al encabezado Ordenar y, a continuación, selecciona Ascendente.
- Arrastre los campos bucket_size y bucket_value_count al encabezado Métrica.
- Coloca el cursor sobre el icono situado a la izquierda de la métrica bucket_size para que aparezca el icono Editar.
Haz clic en el icono Editar
y, a continuación, haz lo siguiente:
- En el campo Nombre, escribe
Unique row loss. - En Type (Tipo), elige Percent (Porcentaje).
- En Cálculo de la comparación, elija Porcentaje del total.
- En Cálculo acumulativo, elige Suma acumulativa.
- En el campo Nombre, escribe
- Repite el paso anterior con la métrica bucket_value_count, pero en el campo Nombre, escribe
Unique quasi-identifier combination loss.
Cuando hayas terminado, la columna debería tener este aspecto:
Por último, configure el gráfico para que muestre un gráfico de líneas de ambas métricas:
- En el panel de la derecha de la ventana, haz clic en la pestaña Estilo.
- En Serie 1 y Serie 2, elige Línea.
- Para ver el gráfico final por sí solo, haga clic en el botón Ver, situado en la esquina superior derecha de la ventana.
A continuación, se muestra un ejemplo de gráfico después de completar los pasos anteriores.
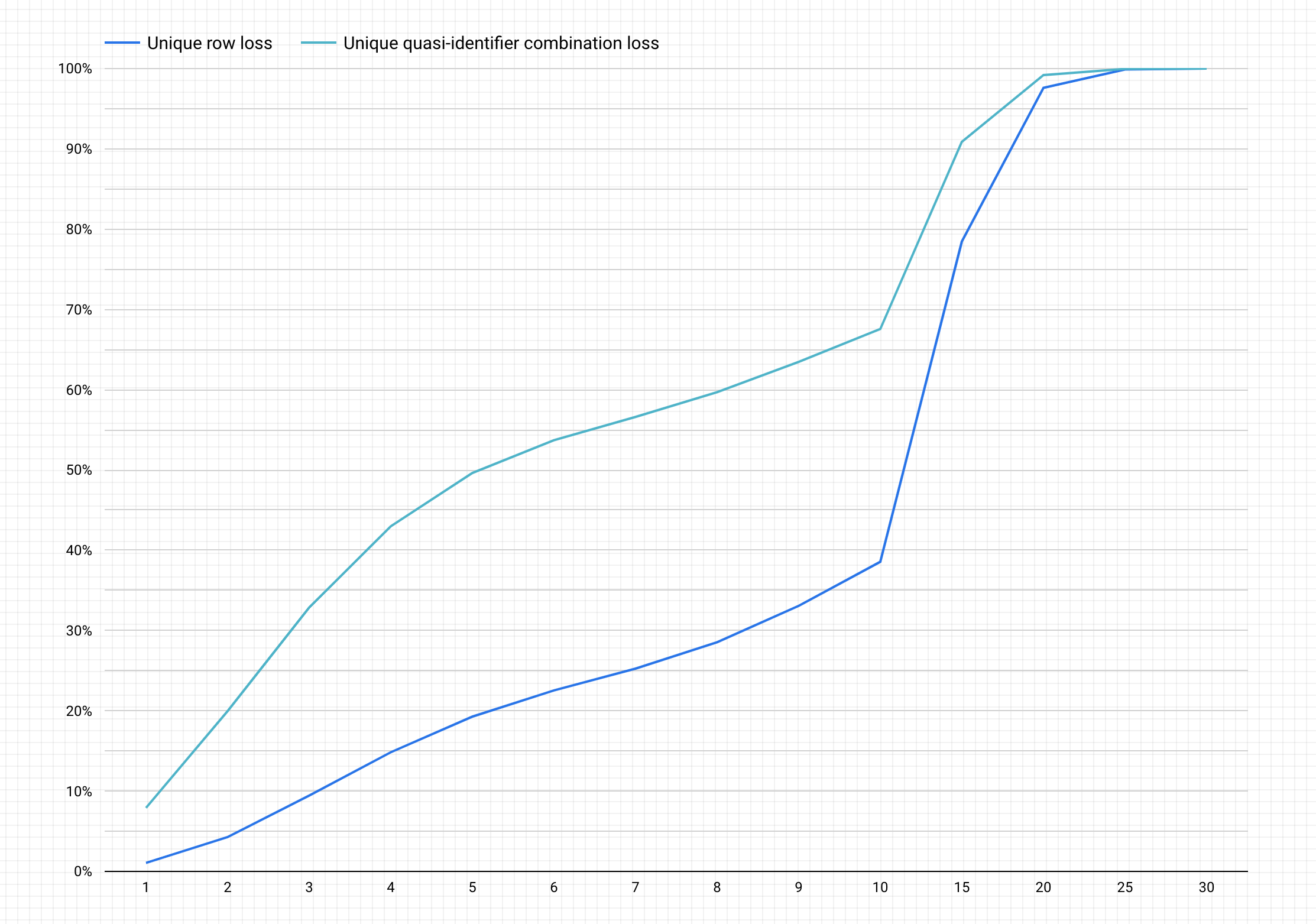
Interpretar el gráfico
En el gráfico generado, se representa en el eje y el porcentaje potencial de pérdida de datos de las filas únicas y de las combinaciones únicas de cuasi-identificadores para conseguir un valor de k-anonimato en el eje x.
Cuanto más altos sean los valores de k-anonimidad, menor será el riesgo de reidentificación. Sin embargo, para conseguir valores de k-anonimato más altos, tendrías que eliminar porcentajes más altos del total de filas y combinaciones únicas de cuasi-identificadores, lo que podría reducir la utilidad de los datos.
Por suerte, eliminar datos no es la única opción para reducir el riesgo de reidentificación. Otras técnicas de anonimización pueden lograr un mejor equilibrio entre la pérdida y la utilidad. Por ejemplo, para abordar el tipo de pérdida de datos asociado a valores de k-anonimato más altos y a este conjunto de datos, puedes probar a agrupar las edades o los puestos de trabajo para reducir la singularidad de las combinaciones de edad y puesto de trabajo. Por ejemplo, puedes probar a agrupar las edades en intervalos de 20-25, 25-30, 30-35, etc. Para obtener más información sobre cómo hacerlo, consulta Generalización y agrupación en contenedores y Desidentificar datos sensibles en contenido de texto.