Este tópico mostra como medir o anonimato k de um conjunto de dados através da Proteção de dados confidenciais e visualizá-lo no Looker Studio. Ao fazê-lo, também pode compreender melhor o risco e ajudar a avaliar as concessões na utilidade que pode estar a fazer se ocultar ou desidentificar dados.
Embora o foco deste tópico seja a visualização da métrica de análise de risco de reidentificação de k-anonimato, também pode visualizar a métrica de l-diversidade através dos mesmos métodos.
Este tópico pressupõe que já conhece o conceito de anonimato k e a sua utilidade para avaliar a reidentificação de registos num conjunto de dados. Também é útil ter alguma familiaridade com a forma de calcular a anonimização k através da proteção de dados confidenciais e com a utilização do Looker Studio.
Introdução
As técnicas de desidentificação podem ser úteis para proteger a privacidade dos seus sujeitos enquanto processa ou usa dados. Mas como é que sabe se um conjunto de dados foi suficientemente anonimizado? Como é que sabe se a desidentificação resultou numa perda de dados excessiva para o seu exemplo de utilização? Ou seja, como pode comparar o risco de reidentificação com a utilidade dos dados para ajudar a tomar decisões baseadas em dados?
O cálculo do valor de k-anonimato de um conjunto de dados ajuda a responder a estas perguntas através da avaliação da capacidade de reidentificação dos registos do conjunto de dados. A proteção de dados confidenciais contém uma funcionalidade incorporada para calcular um valor de k-anonimato num conjunto de dados com base nos quase identificadores que especificar. Isto ajuda a avaliar rapidamente se a desidentificação de uma determinada coluna ou combinação de colunas vai resultar num conjunto de dados com maior ou menor probabilidade de ser reidentificado.
Exemplo de conjunto de dados
Seguem-se as primeiras linhas de um exemplo de conjunto de dados grande.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Para os efeitos deste tutorial, user_id não vai ser abordado, uma vez que o foco
é nos quase identificadores. Num cenário do mundo real, deve garantir que user_id é ocultado ou que é gerado um token de forma adequada. A coluna score é proprietária deste conjunto de dados e é pouco provável que um atacante a consiga descobrir por outros meios, pelo que não a vai incluir na análise. O seu foco vai estar nas colunas age e title restantes, com as quais um atacante pode potencialmente saber mais sobre um indivíduo através de outras fontes de dados. As perguntas às quais está a tentar responder para o conjunto de dados são:
- Que efeito terão os dois quase identificadores,
ageetitle, no risco geral de reidentificação dos dados desidentificados? - Como é que a aplicação de uma transformação de desidentificação afeta este risco?
Quer certificar-se de que a combinação de age e title não é mapeada para um pequeno número de utilizadores. Por exemplo, suponhamos que existe apenas um utilizador no conjunto de dados cujo título é Programador I e que tem 69 anos. Um atacante pode conseguir fazer uma referência cruzada dessas informações com dados demográficos ou outras informações disponíveis, descobrir quem é a pessoa e saber o valor da respetiva pontuação.
Para mais informações acerca deste fenómeno, consulte a secção "IDs de entidades e computação
k-anonimato" no tópico conceptual Análise de
riscos.
Passo 1: calcule o k-anonimato no conjunto de dados
Primeiro, use a proteção de dados confidenciais para calcular o anonimato k no conjunto de dados enviando o seguinte JSON para o recurso DlpJob. Neste JSON, define o ID da entidade para a coluna user_id e identifica os dois quase identificadores como as colunas age e title. Também está a instruir a proteção de dados confidenciais para guardar os resultados numa nova tabela do BigQuery.
Entrada JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}Assim que a tarefa de k-anonimato estiver concluída, a proteção de dados confidenciais envia os resultados da tarefa para uma tabela do BigQuery denominada dlp-demo-2.dlp_testing.test_results.
Passo 2: associe os resultados ao Looker Studio
Em seguida, associa a tabela do BigQuery que criou no passo 1 a um novo relatório no Looker Studio.
Abra o Looker Studio.
Clique em Criar > Relatório.
No painel Adicionar dados ao relatório, em Associar a dados, clique em BigQuery. Pode ter de autorizar o Looker Studio a aceder às suas tabelas do BigQuery.
No seletor de colunas, selecione Os meus projetos. Em seguida, escolha o projeto, o conjunto de dados e a tabela. Quando terminar, clique em Adicionar. Se vir um aviso a indicar que está prestes a adicionar dados a este relatório, clique em Adicionar ao relatório.
Os resultados da análise de k-anonimato foram adicionados ao novo relatório do Looker Studio. No passo seguinte, vai criar o gráfico.
Passo 3: crie o gráfico
Faça o seguinte para inserir e configurar o gráfico:
- No Looker Studio, se for apresentada uma tabela de valores, selecione-a e prima Delete para a remover.
- No menu Inserir, clique em Gráfico combinado.
- Clique e desenhe um retângulo na tela onde quer que o gráfico seja apresentado.
Em seguida, configure os dados do gráfico no separador Dados para que o gráfico mostre o efeito da variação dos intervalos de tamanho e valor dos contentores:
- Limpe os campos nos seguintes títulos apontando para cada campo
e clicando no X, como mostrado aqui:
- Dimensão do intervalo de datas
- Dimensão
- Métrica
- Ordenar
- Com todos os campos limpos, arraste o campo upper_endpoint da coluna Campos disponíveis para o cabeçalho Dimensão.
- Arraste o campo upper_endpoint para o cabeçalho Ordenar e, de seguida, selecione Ascendente.
- Arraste os campos bucket_size e bucket_value_count para o cabeçalho Métrica.
- Aponte para o ícone à esquerda da métrica bucket_size e é apresentado um ícone de edição.
Clique no ícone Editar
e, de seguida, faça o seguinte:
- No campo Nome, escreva
Unique row loss. - Em Tipo, escolha Percentagem.
- Em Cálculo de comparação, escolha Percentagem do total.
- Em Cálculo em execução, escolha Soma em execução.
- No campo Nome, escreva
- Repita o passo anterior para a métrica bucket_value_count, mas no campo Nome, escreva
Unique quasi-identifier combination loss.
Quando terminar, a coluna deve aparecer conforme mostrado aqui:
Por último, configure o gráfico para apresentar um gráfico de linhas para ambas as métricas:
- Clique no separador Estilo no painel à direita da janela.
- Para a Série n.º 1 e a Série n.º 2, escolha Linha.
- Para ver o gráfico final sozinho, clique no botão Ver no canto superior direito da janela.
Segue-se um exemplo de gráfico após a conclusão dos passos anteriores.
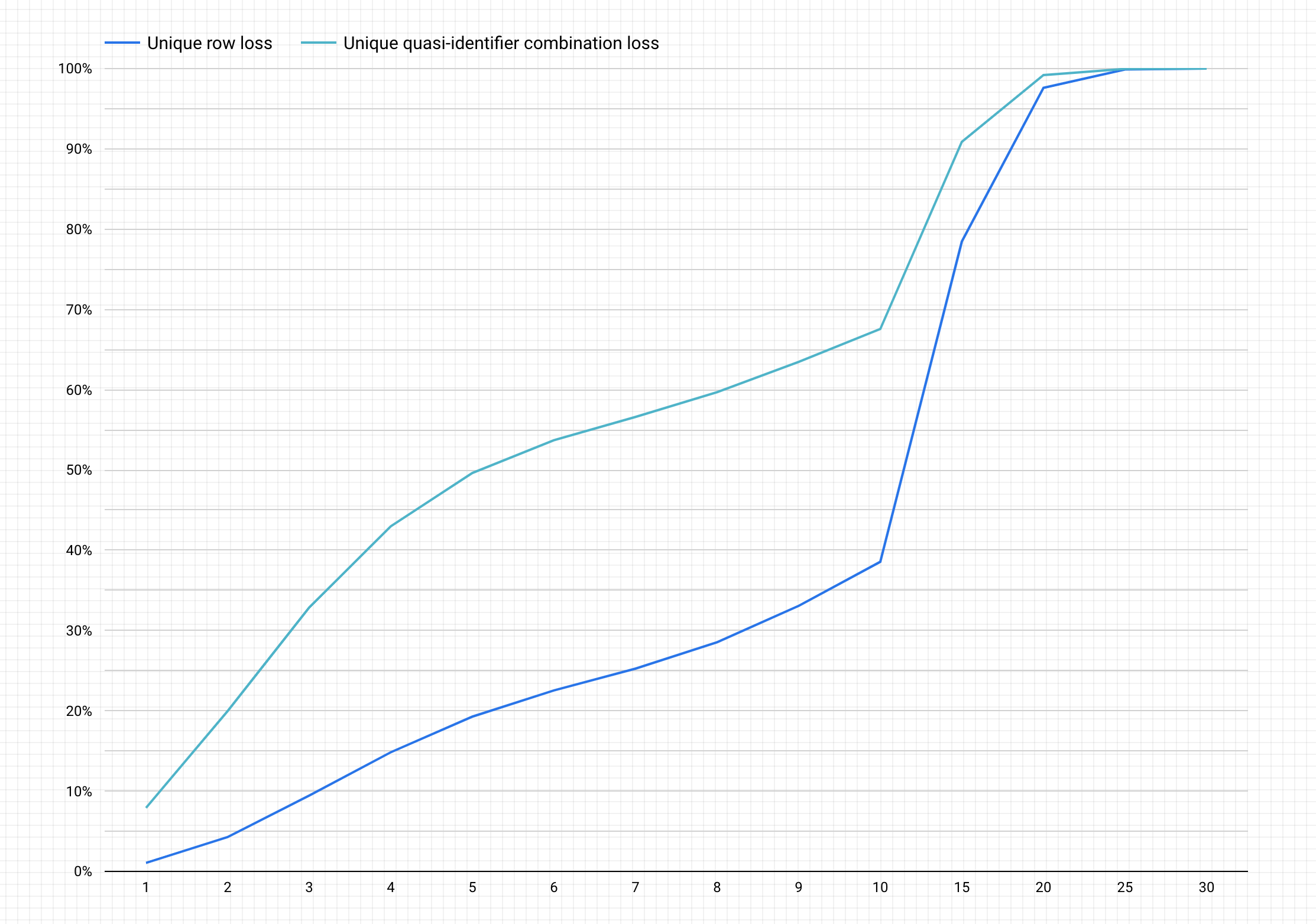
Interpretar o gráfico
O gráfico gerado representa, no eixo y, a percentagem potencial de perda de dados para linhas únicas e combinações de quase identificadores únicos para alcançar, no eixo x, um valor de anonimato k.
Os valores de anonimato k mais elevados indicam um menor risco de reidentificação. No entanto, para alcançar valores de anonimato k mais elevados, teria de remover percentagens mais elevadas do total de linhas e combinações de quase identificadores únicos mais elevadas, o que pode diminuir a utilidade dos dados.
Felizmente, ignorar dados não é a única opção para reduzir o risco de reidentificação. Outras técnicas de desidentificação podem encontrar um melhor equilíbrio entre a perda e a utilidade. Por exemplo, para resolver o tipo de perda de dados associado a valores de anonimato k mais elevados e a este conjunto de dados, pode experimentar agrupar idades ou cargos para reduzir a singularidade das combinações de idade/cargo. Por exemplo, pode experimentar agrupar as idades em intervalos de 20 a 25, 25 a 30, 30 a 35 e assim sucessivamente. Para mais informações sobre como o fazer, consulte os artigos Generalização e agrupamento e Remoção da identificação de dados sensíveis em conteúdo de texto.