Vous trouverez sur cette page la procédure à suivre pour mesurer le k-anonymat d'un ensemble de données à l'aide de la protection des données sensibles et pour le visualiser dans Looker Studio. Ainsi, vous serez également en mesure de mieux comprendre les risques et d'évaluer les compromis que vous pouvez être amené à faire au niveau de l'utilité des données si vous les masquez ou les anonymisez.
Bien que cette rubrique soit axée sur la visualisation de la métrique d'analyse des risques de restauration de l'identification k-anonymat, vous pouvez également visualiser la métrique l-diversité à l'aide des mêmes méthodes.
Cette rubrique suppose que vous connaissez déjà le concept de k-anonymat et son utilité pour évaluer la possibilité de restaurer l'identification des enregistrements au sein d'un ensemble de données. Vous devez également connaître les bases du calcul de k-anonymat à l'aide de la protection des données sensibles et de l'utilisation de Looker Studio.
Introduction
Les techniques de suppression de l'identification peuvent s'avérer utiles pour protéger la vie privée des personnes concernées pendant que vous traitez ou exploitez des données. Mais comment savoir si un ensemble de données a été suffisamment anonymisé ? Et comment saurez-vous si la suppression de l'identification a entraîné une perte de données excessive pour votre cas d'utilisation ? En d'autres termes : comment pouvez-vous comparer le risque de restauration de l'identification et l'utilité de ces données, pour vous aider à prendre les bonnes décisions en ce qui les concerne ?
Le calcul de la valeur de k-anonymat d'un ensemble de données permet de répondre à ces questions en évaluant la possibilité de restaurer l'identification des enregistrements qu'il contient. La protection des données sensibles bénéficie d'une fonctionnalité intégrée grâce à laquelle il est possible de calculer une valeur de k-anonymat sur un ensemble de données à partir des quasi-identifiants que vous spécifiez. Cela vous permet d'évaluer rapidement si l'anonymisation d'une colonne ou d'une combinaison de colonnes spécifiques conduira à augmenter ou réduire le risque de restauration de l'identification sur l'ensemble de données.
Exemple d'ensemble de données
Voici les premières lignes d'un ensemble de données volumineux servant d'exemple :
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Pour les besoins de ce tutoriel, nous n'aborderons pas user_id, car l'accent est mis sur les quasi-identifiants. Dans un scénario réel, vous devez vous assurer que user_id est masqué ou tokenisé de manière adéquate. La colonne score est spécifique à cet ensemble de données, et il est peu probable qu'un pirate informatique puisse accéder au contenu par d'autres moyens. Par conséquent, vous ne l'incluez pas dans l'analyse. Nous allons donc nous focaliser sur les colonnes age et title restantes, qu'un pirate informatique pourrait exploiter via d'autres sources de données pour identifier un individu. Les questions auxquelles vous essayez de répondre pour cet ensemble de données sont les suivantes :
- Quel effet les deux quasi-identifiants
ageettitleauront-ils sur le risque global de restauration des éléments d'identification des données ? - Comment l'application d'une transformation de suppression des éléments d'identification affectera-t-elle ce risque ?
Vous voulez vous assurer que la combinaison des informations age et title ne permettra pas d'identifier un petit groupe d'utilisateurs. Par exemple, supposons qu'un seul utilisateur de l'ensemble de données ait un poste de programmeur et soit âgé de 69 ans. Un pirate informatique pourrait être en mesure de faire un rapprochement entre ces informations et des données démographiques, ou toute autre information disponible, et ainsi déterminer qui est cette personne ainsi que la valeur de son score.
Pour plus d'informations sur ce phénomène, consultez la section ID d'entité et calcul de k-anonymat de la page de présentation des concepts intitulée Analyse des risques.
Étape 1 : Calculez le k-anonymat sur l'ensemble de données
Pour commencer, servez-vous de Sensitive Data Protection pour calculer le k-anonymat sur l'ensemble de données en envoyant le JSON suivant à la ressource DlpJob. Dans ce JSON, vous définissez l'ID d'entité sur la colonne user_id, et vous désignez les deux colonnes age et title comme quasi-identifiants. Vous demandez également à Sensitive Data Protection d'enregistrer les résultats dans une nouvelle table BigQuery.
Entrée JSON :
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}Une fois que la tâche de calcul de k-anonymat est terminée, Sensitive Data Protection envoie les résultats à une table BigQuery nommée dlp-demo-2.dlp_testing.test_results.
Étape 2 : Connectez les résultats à Looker Studio
L'étape suivante consiste à connecter la table BigQuery produite lors de l'étape 1 à un nouveau rapport dans Looker Studio.
Ouvrez Looker Studio.
Cliquez sur Créer > Rapport.
Dans le volet Ajouter des données au rapport, sous Se connecter aux données, cliquez sur BigQuery. Vous devrez peut-être autoriser Looker Studio à accéder à vos tables BigQuery.
Dans le sélecteur de colonnes, sélectionnez Mes projets. Sélectionnez ensuite le projet, l'ensemble de données et la table. Lorsque vous avez terminé, cliquez sur Ajouter. Si un message vous informe que vous êtes sur le point d'ajouter des données à ce rapport, cliquez sur Ajouter au rapport.
Les résultats de l'analyse du k-anonymat ont maintenant été ajoutés au nouveau rapport Looker Studio. À l'étape suivante, vous allez créer le graphique.
Étape 3 : Créez le graphique
Procédez comme suit pour insérer et configurer le graphique :
- Dans Looker Studio, si une table de valeurs s'affiche, sélectionnez-la et appuyez sur la touche Suppr pour la supprimer.
- Dans le menu Insertion, cliquez sur Graphique combiné.
- Cliquez et tracez un rectangle sur le canevas à l'endroit où vous souhaitez faire figurer le graphique.
Configurez ensuite le graphique dans l'onglet Données, pour qu'il présente l'effet des variations sur la taille et les plages de valeurs des buckets :
- Effacez les champs sous les en-têtes suivants en pointant la souris sur chacun d'eux, puis en cliquant sur la croix , comme illustré ci-dessous :
- Dimension associée à la plage de dates
- Dimension
- Métrique
- Trier
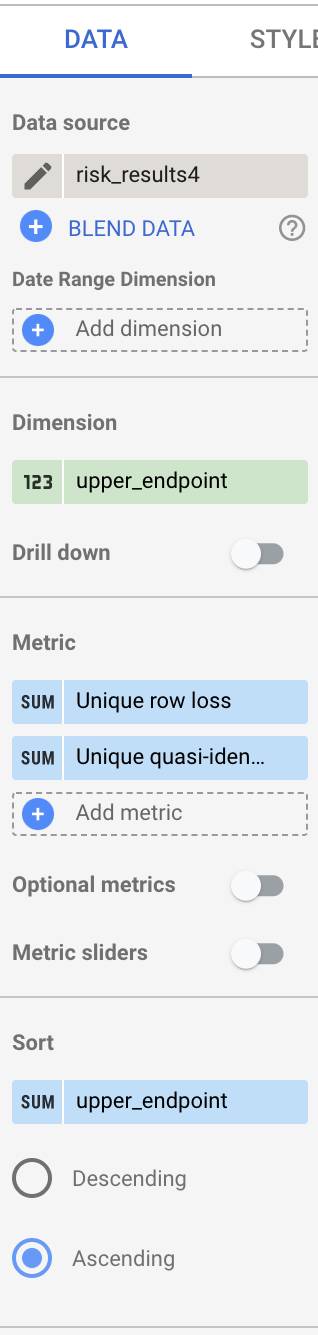
- Une fois tous les champs effacés, faites glisser le champ upper_endpoint de la colonne Champs disponibles vers l'en-tête Dimension.
- Faites glisser le champ upper_endpoint vers l'en-tête Trier, puis sélectionnez Croissant.
- Faites glisser les champs bucket_size et bucket_value_count vers l'en-tête Métrique.
- Pointez la souris sur l'icône à gauche de la métrique bucket_size. L'icône Modifier apparaît.
Cliquez sur l'icône Modifier , puis procédez comme suit :
- Dans le champ Nom, saisissez
Unique row loss. - Sous Type, sélectionnez Pourcentage.
- Sous Calcul de comparaison, sélectionnez Pourcentage du total.
- Sous Calcul cumulé, sélectionnez Somme cumulée.
- Dans le champ Nom, saisissez
- Répétez l'étape précédente pour la métrique bucket_value_count, mais saisissez
Unique quasi-identifier combination lossdans le champ Nom.
Une fois que vous avez terminé, la colonne doit se présenter comme illustré ci-dessous :
Enfin, configurez le graphique de sorte qu'il affiche des courbes pour ces deux métriques :
- Cliquez sur l'onglet Style dans le volet situé à droite de la fenêtre.
- Pour les séries n°1 et n°2, choisissez Ligne.
- Pour afficher le graphique final, cliquez sur le bouton Afficher dans l'angle supérieur droit de la fenêtre.
Voici un exemple de graphique que vous pouvez obtenir après avoir suivi les étapes précédentes.
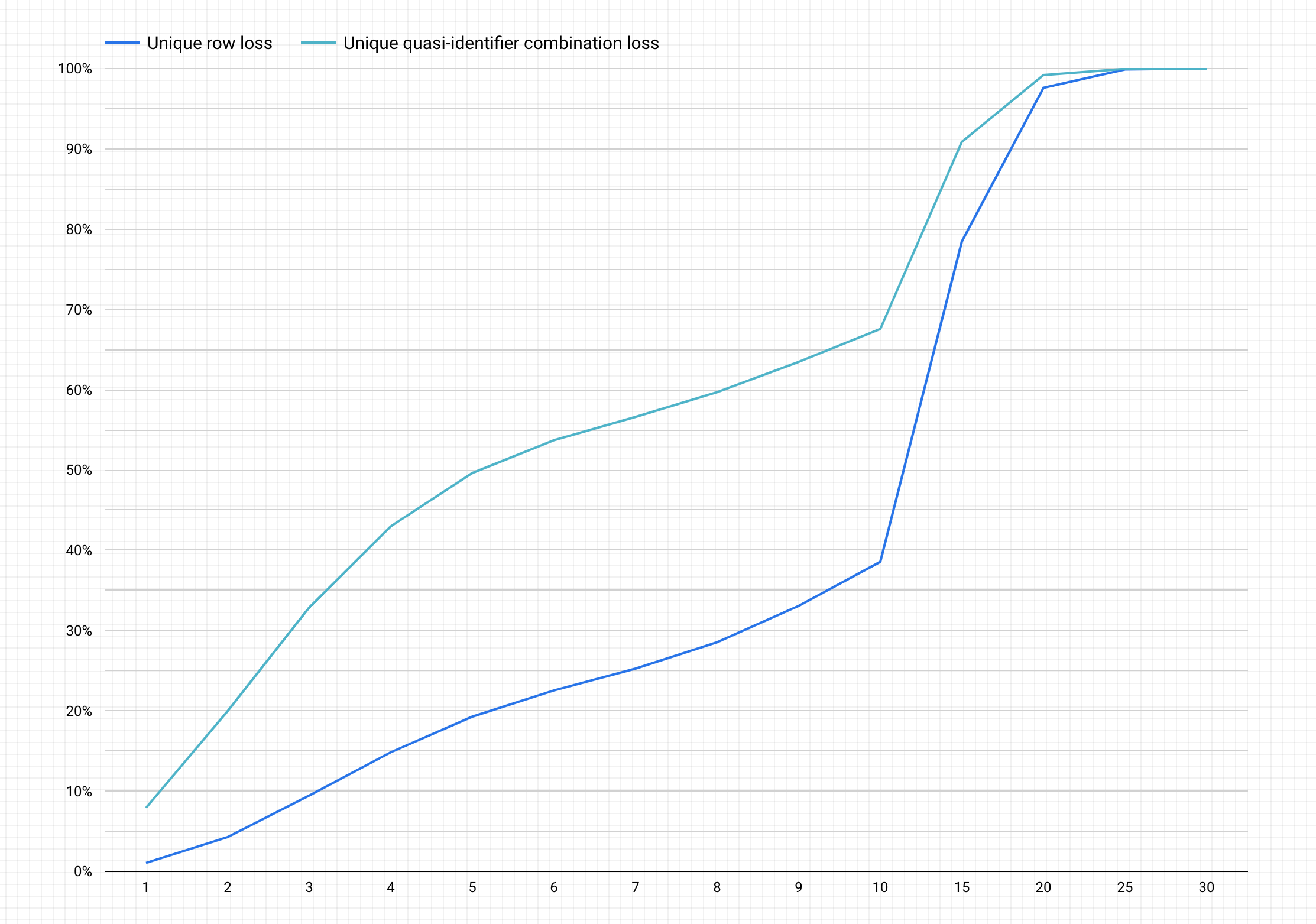
Interpréter le graphique
Le graphique généré présente sur l'axe y le pourcentage potentiel de perte de données pour les lignes uniques et les combinaisons de quasi-identifiants uniques afin d'obtenir une valeur k-anonymat sur l'axe x.
Plus la valeur k-anonymat est élevée, plus le risque de restauration de l'identification est faible. Toutefois, pour obtenir des valeurs k-anonymat plus élevées, vous devez supprimer les pourcentages les plus élevés du nombre total de lignes et les combinaisons de quasi-identifiants uniques les plus élevées, ce qui peut réduire l'utilité des données.
Heureusement, supprimer les données n'est pas votre seule option pour réduire le risque d'anonymisation. D'autres techniques d'anonymisation permettent d'atteindre un meilleur équilibre entre perte de données et utilité. Par exemple, pour réduire l'ampleur de la perte de données associée à des valeurs élevées de k-anonymat dans le cadre de cet ensemble de données, vous pouvez essayer de fragmenter les âges ou les fonctions afin de réduire le caractère unique des combinaisons d'âge et de fonction. Ainsi, vous pouvez essayer de fragmenter les âges dans des tranches allant de 20 à 25 ans, de 25 à 30 ans, de 30 à 35 ans, etc. Pour en savoir plus sur la procédure à suivre, consultez les pages Généralisation et binning et Supprimer l'identification des données sensibles dans le contenu textuel.