匿名化是一種去識別化技術,可將私密資料值替換為以加密編譯方式產生的代碼。在金融和醫療照護等產業中,假名化技術廣為採用,有助於降低使用中資料的風險、縮小法規遵循範圍,以及盡量減少系統中敏感資料的曝光,同時保留資料的實用性和準確度。
Sensitive Data Protection 支援三種去識別化匿名化技術,並對原始機密資料值套用三種加密轉換方法之一,產生權杖。然後將每個原始私密值替換為對應的代碼。 假名化有時也稱為「權杖化」或「替代替換」。
假名化技術可產生單向或雙向權杖。單向權杖經過不可逆的轉換,雙向權杖則可還原。由於權杖是使用對稱式加密建立,因此可用於產生新權杖的加密金鑰,也能反向產生權杖。如果不需要可逆性,可以使用採用安全雜湊機制的單向權杖。
瞭解假名化如何保護敏感資料,同時讓業務營運和分析工作流程輕鬆存取及使用所需資料,對您很有幫助。本主題將探討假名化概念,以及 Sensitive Data Protection 支援的三種資料轉換密碼編譯方法。
如需如何實作這些假名化方法的說明,以及更多使用 Sensitive Data Protection 的範例,請參閱「去識別化私密資料」。
Sensitive Data Protection 支援的加密方法
Sensitive Data Protection 支援三種去識別化技術,全都使用加密金鑰。可用的方法如下:
- 使用 AES-SIV 進行確定性加密:輸入值會替換為使用 AES-SIV 加密演算法和加密金鑰加密的值,並以 base64 編碼,然後在前面加上代理註解 (如有指定)。這個方法會產生雜湊值,因此不會保留輸入值的字元集或長度。加密和雜湊處理過的值可使用原始加密編譯金鑰和整個輸出值 (包括代理值註解) 重新識別。進一步瞭解使用 AES-SIV 加密技術代碼化的值格式。
- 格式保留加密:使用 FPE-FFX 加密演算法和加密編譯金鑰加密輸入值,然後將輸入值替換為加密值,並視需要加上代理註解。根據設計,輸出值會保留輸入值的字元集和長度。使用原始加密編譯金鑰和完整輸出值 (包括代理值註解),即可重新識別加密值。(如要瞭解使用這項加密方法時的重要考量,請參閱本主題後文的「保留格式的加密」一節)。
- 加密編譯雜湊:輸入值會替換為經過加密和雜湊處理的值,而加密和雜湊處理是使用雜湊式訊息驗證碼 (HMAC)-安全雜湊演算法 (SHA)-256,以加密金鑰對輸入值進行處理。經過雜湊處理的轉換輸出長度一律相同,且無法重新識別。進一步瞭解使用加密雜湊函式權杖化值的格式。
下表匯總了這些去識別化方法。表格列的說明如下。
| 使用 AES-SIV 的確定性加密 | 格式保留加密 | 加密編譯雜湊 | |
|---|---|---|---|
| 加密類型 | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| 支援的輸入值 | 長度至少要有 1 個字元,且沒有字元集限制。 | 長度至少 2 個字元,且必須採 ASCII 編碼。 | 必須是字串或整數值。 |
| 代理值註解 | 選填。 | 選填。 | 不適用 |
| 調整情境 | 選填。 | 選填。 | 不適用 |
| 保留字元集和長度 | ✗ | ✓ | ✗ |
| 可復原 | ✓ | ✓ | ✗ |
| 參照完整性 | ✓ | ✓ | ✓ |
- 加密類型:去識別化轉換中使用的加密類型。
- 支援的輸入值:輸入值的最低要求。
- 替代註解:使用者指定的註解,會加在加密值前面,為使用者提供背景資訊,並提供資訊給敏感資料保護機制,用於重新識別去識別化值。如要重新識別非結構化資料,必須提供替代註解。使用
RecordTransformation轉換結構化或表格資料的資料欄時,可選擇是否要指定。 - 結構定義修正項:參照資料欄位,用來「修正」輸入值,以便將相同的輸入值去識別化為不同的輸出值。使用
RecordTransformation轉換結構化或表格資料的資料欄時,可選擇調整內容。詳情請參閱「使用內容調整」。 - 保留字元集和長度:去識別化值是否由與原始值相同的字元集組成,以及去識別化值的長度是否與原始值相符。
- 可還原:可使用加密編譯金鑰、代理值註解和任何情境調整項目重新識別。
- 參照完整性: 參照完整性可讓記錄保持彼此的關係,即使個別資料已去識別化也一樣。假設加密編譯金鑰和背景資訊調整項相同,每次轉換資料表時,都會將資料替換成相同的模糊形式,以確保值 (以及結構化資料中的記錄) 之間的連結得以保留,即使是跨資料表也一樣。
Sensitive Data Protection 中的權杖化運作方式
Sensitive Data Protection 支援三種權杖化方法,基本程序都相同。
步驟 1:Sensitive Data Protection 會選取要權杖化的資料。最常見的做法是使用內建或自訂 infoType 偵測工具,比對所需的機密資料值。如果您掃描的是結構化資料 (例如 BigQuery 資料表),也可以使用記錄轉換,對整欄資料執行權杖化。
如要進一步瞭解這兩類轉換 (infoType 和記錄轉換),請參閱「去識別化轉換」。
步驟 2:使用加密金鑰,Sensitive Data Protection 會加密每個輸入值。您可透過下列其中一種方式提供這個金鑰:
- 使用 Cloud Key Management Service (Cloud KMS) 包裝金鑰。(為確保最高安全性,建議使用 Cloud KMS)。
- 使用暫時性金鑰,這類金鑰會在去識別化時由 Sensitive Data Protection 產生,然後捨棄。暫時性金鑰只會在每個 API 要求中保持完整性。如果您需要確保資料完整性或打算重新識別這項資料,請勿使用這類金鑰。
- 直接以原始文字形式。(不建議使用)。
詳情請參閱本主題稍後的「使用加密金鑰」一節。
步驟 3 (僅限使用 AES-SIV 進行加密雜湊和確定性加密):私密/機密資料保護功能會使用 Base64 編碼加密值。透過密碼編譯雜湊,這個編碼加密值就是權杖,程序會繼續執行步驟 6。使用 AES-SIV 進行確定性加密時,這個經過編碼和加密的值就是代理值,只是權杖的其中一個元件。接著繼續執行步驟 4。
步驟 4 (僅限使用 AES-SIV 進行保留格式的確定性加密):
Sensitive Data Protection 會在加密值中加入選用的替代註解。代理註解會在加密代理值前面加上您定義的描述性字串,協助識別這些值。舉例來說,如果沒有註解,您可能無法分辨去識別化的電話號碼和去識別化的身分證字號或其他識別號碼。此外,如要重新識別已去識別化的非結構化資料值 (使用格式保留加密或確定性加密),您必須指定代理註解。(使用 RecordTransformation 轉換結構化或表格資料欄時,不需要替代註解)。
步驟 5 (僅限結構化資料,使用 AES-SIV 進行格式保留和決定性加密):Sensitive Data Protection 可以使用另一個欄位的選用內容來「調整」產生的符記。這可讓您變更權杖的範圍。舉例來說,假設您有行銷廣告活動資料庫,其中包含電子郵件地址,且您想為廣告活動 ID「調整」後的相同電子郵件地址產生專屬權杖。這樣一來,使用者就能在同一個廣告活動中加入同一位使用者的資料,但無法跨不同廣告活動加入資料。如果使用情境調整項建立權杖,則還原去識別化轉換時也需要使用這個情境調整項。使用 AES-SIV 支援內容,保留格式並確定加密。進一步瞭解如何使用情境調整。
步驟 6:Sensitive Data Protection 會將原始值替換為去識別化值。
代幣化價值比較
本節將示範如何使用本主題討論的三種方法,對一般權杖進行去識別化。敏感資料值範例為北美洲電話號碼 (1-206-555-0123)。
使用 AES-SIV 的確定性加密
使用確定性加密和 AES-SIV 進行去識別化時,系統會使用加密金鑰透過 AES-SIV 加密輸入值 (以及任何指定的內容調整項,視需要),並使用 Base64 編碼,然後視需要加上替代註解。這個方法不會保留輸入值的字元集 (或「字母表」)。為產生可列印的輸出內容,系統會以 Base64 編碼結果值。
假設已指定代理值 infoType,產生的權杖格式如下:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
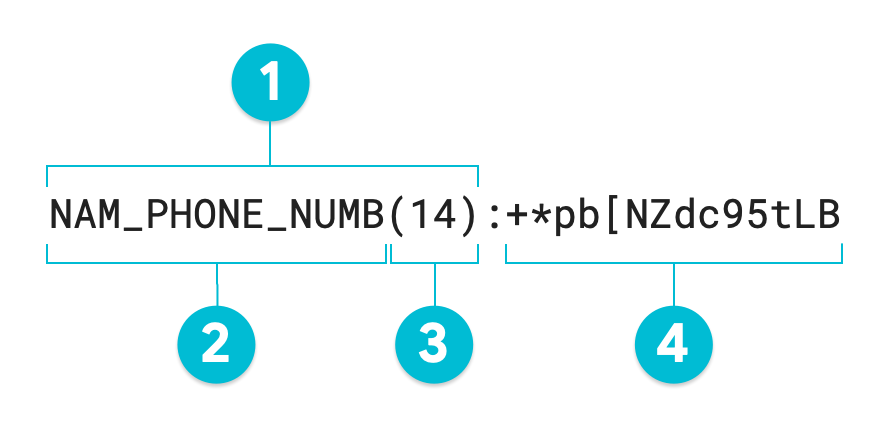
下圖為註解範例,顯示使用 AES-SIV 對值 1-206-555-0123 執行確定性加密去識別化作業後產生的權杖。選用的代理值 infoType 已設為 NAM_PHONE_NUMB:

- 替代註解
- 代理值 infoType (由使用者定義)
- 轉換值的字元長度
- 替代 (轉換) 值
如未指定替代註解,產生的權杖會等於轉換後的值,或註解圖中的 #4。如要重新識別非結構化資料,必須提供整個權杖,包括替代註解。轉換資料表等結構化資料時,可選擇是否要使用替代註解;Sensitive Data Protection 可使用 RecordTransformation 對整欄資料執行去識別化和重新識別化作業,不必使用替代註解。
格式保留加密
使用格式保留加密進行去識別化時,系統會使用加密編譯金鑰,透過格式保留加密的 FFX 模式 (「FPE-FFX」) 加密輸入值 (以及任何指定的內容調整項,視需要而定),然後視需要預先加上代理註解 (如有指定)。
與本主題說明的其他權杖化方法不同,輸出代理值與輸入值長度相同,且不會使用 Base64 編碼。您定義加密值所用的字元集 (或「字母表」)。您可以透過三種方式指定字母,供 Sensitive Data Protection 用於輸出值:
- 請使用四個列舉值之一,代表四個最常見的字元集/字母。
- 使用基數值,指定字母的大小。指定
2的最小基數值會產生只包含0和1的字母。指定95的最大基數值,會產生包含所有數字字元、大寫英文字母字元、小寫英文字母字元和符號字元的字母。 - 列出要使用的確切字元,建立字母。舉例來說,指定
1234567890-*會產生僅由數字、連字號和星號組成的替代值。
下表列出四種常見的字元集,並分別提供列舉值 (FfxCommonNativeAlphabet)、基底值和字元集清單。最後一列會列出完整字元集,對應於最大基數值。
| 字母/字元集名稱 | Radix | 字元清單 |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
假設已指定代理值 infoType,產生的權杖格式如下:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
下方的註解圖表是 Sensitive Data Protection 去識別化作業的輸出內容,該作業使用格式保留加密,以 95 為基數加密值 1-206-555-0123。選用的代理值 infoType 已設為 NAM_PHONE_NUMB:
- 替代註解
- 代理值 infoType (由使用者定義)
- 轉換值的字元長度
- 代理 (轉換) 值 - 長度與輸入值相同
如未指定替代註解,產生的權杖會等於轉換後的值,或註解圖中的 #4。如要重新識別非結構化資料,必須提供整個權杖,包括替代註解。轉換資料表等結構化資料時,可選擇是否使用替代註解;Sensitive Data Protection 可使用 RecordTransformation 對整欄資料執行去識別化和重新識別化作業,不必使用替代註解。
加密編譯雜湊
使用加密雜湊進行去識別化時,系統會使用加密金鑰透過 HMAC-SHA-256 雜湊處理輸入值,然後使用 Base64 編碼。去識別化值一律為固定長度,實際長度則視金鑰大小而定。
與本主題討論的其他權杖化方法不同,加密雜湊會建立單向權杖。也就是說,使用加密雜湊進行去識別化後,就無法還原。
以下是針對值 1-206-555-0123 使用加密雜湊進行去識別化作業的輸出內容。這個輸出內容是以 Base64 編碼表示的雜湊值:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
使用加密金鑰
您可以使用三種加密金鑰,搭配私密資料保護服務的加密去識別化方法:
Cloud KMS 包裝的加密編譯金鑰:這是最安全的加密編譯金鑰類型,可搭配敏感資料保護去識別化方法使用。以 Cloud KMS 包裝的金鑰包含 128 位元、192 位元或 256 位元的加密編譯金鑰,並已使用其他金鑰加密。您提供第一個加密編譯金鑰,然後使用 Cloud Key Management Service 儲存的加密編譯金鑰包裝該金鑰。這類金鑰會儲存在 Cloud KMS 中,供日後重新識別。如要進一步瞭解如何建立及包裝金鑰,以便去識別化及重新識別化,請參閱「快速入門導覽課程:將機密文字去識別化及重新識別化」。
暫時性加密編譯金鑰:暫時性加密編譯金鑰會在去識別化時由敏感資料防護機制產生,然後捨棄。因此,請勿搭配任何您想還原的加密去識別化方法,使用暫時性的加密金鑰。暫時性加密編譯金鑰只會針對每個 API 要求維持完整性。如果您需要多個 API 要求的完整性,或打算重新識別資料,請勿使用這類金鑰。
未包裝的加密編譯金鑰:未包裝的金鑰是原始的 Base64 編碼 128、192 或 256 位元加密編譯金鑰,您會在去識別化要求中提供給 DLP API。您有責任妥善保存這類加密金鑰,以供日後重新識別。由於這類金鑰有意外洩漏的風險,因此不建議使用。這些金鑰可用於測試,但建議您改用 Cloud KMS 包裝的加密編譯金鑰,處理實際工作環境工作負載。
如要進一步瞭解使用加密編譯金鑰時可用的選項,請參閱 DLP API 參考資料中的 CryptoKey。
使用內容調整
根據預設,無論輸出權杖是單向或雙向,去識別化作業的所有密碼編譯轉換方法都具有參照完整性。也就是說,只要使用相同的加密編譯金鑰,輸入值一律會轉換為相同的加密值。如果資料重複或出現資料模式,重新識別化風險就會提高。如要讓相同輸入值一律轉換為不同的加密值,可以指定不重複的結構定義修正項。
轉換表格資料時,您會指定內容微調 (在 DLP API 中簡稱為 context),因為微調實際上是指向資料欄的指標,例如 ID。Sensitive Data Protection 會使用內容調整項指定欄位中的值,加密輸入值。為確保加密值一律為不重複值,請指定包含不重複 ID 的調整項資料欄。
請參考以下簡單範例。下表顯示多筆病歷,其中有些包含重複的病患 ID。
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0、I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1、R55 |
| ... | ... | ... |
如果您指示 Sensitive Data Protection 對資料表中的病患 ID 進行去識別化,系統預設會將重複的病患 ID 去識別化為相同的值,如下表所示。舉例來說,病患 ID「43789」的兩個執行個體都會去識別化為「47222」。(「patient_id」欄會顯示使用 FPE-FFX 假名化後的權杖值,且不包含替代註解。詳情請參閱「格式保留加密」一節。
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0、I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1、R55 |
| ... | ... | ... |
這表示參照完整性的範圍涵蓋整個資料集。
如要縮小範圍,避免發生這種行為,請指定內容調整項。 您可以將任何資料欄指定為內容調整項,但為確保每個去識別化值都是不重複的值,請指定每個值都不重複的資料欄。
假設您想查看同一位病患是否會出現在每個 icd10_codes 值中,但不想查看同一位病患是否會出現在不同的 icd10_codes 值中。如要這麼做,請將「icd10_codes」欄指定為情境修正項。
使用 icd10_codes 資料欄做為內容調整項,將 patient_id 資料欄去識別化後的資料表如下:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0、I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1、R55 |
| ... | ... | ... |
請注意,第四個和第五個去識別化 patient_id 值 (29460) 相同,因為不僅原始 patient_id 值相同,兩列的 icd10_codes 值也相同。您需要在 icd10_codes 值範圍內使用一致的病患 ID 執行分析,因此這正是您要的行為。
如要完全切斷 patient_id 值和 icd10_codes 值之間的參照完整性,可以改用 record_id 資料欄做為情境調整項:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0、I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1、R55 |
| ... | ... | ... |
請注意,資料表中每個去識別化的 patient_id 值現在都是不重複的。
如要瞭解如何在 DLP API 中使用內容微調,請注意下列轉換方法參考主題中 context 的用法:
- 格式保留加密:
CryptoReplaceFfxFpeConfig - 使用 AES-SIV 的確定性加密:
CryptoDeterministicConfig - 日期偏移:
DateShiftConfig