A pseudonimização é uma técnica de desidentificação que substitui valores de dados confidenciais por tokens gerados criptograficamente. A pseudonimização é amplamente usada em setores como finanças e saúde para ajudar a reduzir o risco de dados em uso, restringir o escopo de conformidade e minimizar a exposição de dados confidenciais aos sistemas, preservando a utilidade e a precisão dos dados.
A Proteção de dados sensíveis é compatível com três técnicas de pseudonimização de desidentificação e gera tokens aplicando um dos três métodos de transformação criptográfica aos valores de dados confidenciais originais. Cada valor confidencial original é substituído pelo token correspondente. Às vezes, a pseudonimização é chamada de tokenização ou substituição alternativa.
As técnicas de pseudonimização permitem tokens unidirecionais ou bidirecionais. Um token unidirecional foi transformado de forma irrevogável, enquanto um token bidirecional pode ser revertido. Como o token é criado usando criptografia simétrica, a mesma chave criptográfica que gera novos tokens também pode reverter tokens. Para situações em que você não precisa de reversão, é possível usar tokens unidirecionais que usam mecanismos de hash seguros.
É útil entender como a pseudonimização pode ajudar a proteger os dados confidenciais e, ao mesmo tempo, permitir que suas operações de negócios e fluxos de trabalho analíticos tenham fácil acesso e usem os dados de que precisam. Este tópico explora o conceito de pseudonimização e os três métodos criptográficos para transformar dados compatíveis com a proteção de dados sensíveis.
Para instruções sobre como implementar esses métodos de pseudonimização e mais exemplos de uso da Proteção de Dados Sensíveis, consulte Como desidentificar dados sensíveis.
Métodos criptográficos compatíveis na Proteção de Dados Sensíveis
A Proteção de dados sensíveis é compatível com três técnicas de pseudonimização, que usam chaves criptográficas. Veja a seguir os métodos disponíveis:
- Criptografia determinística usando AES-SIV: um valor de entrada é substituído por um valor que foi criptografado usando o algoritmo de criptografia AES-SIV com uma chave criptográfica, codificada com base64 e, em seguida, anexada com uma anotação alternativa, se especificada. Esse método produz um valor de hash. Portanto, ele não preserva o conjunto de caracteres ou o comprimento do valor de entrada. Os valores de hash criptografados podem ser reidentificados com a chave criptográfica original e todo o valor de saída, inclusive a anotação alternativa. Saiba mais sobre o formato dos valores tokenizados usando a criptografia AES-SIV.
- Criptografia com preservação de formato:um valor de entrada é substituído por um valor que foi criptografado usando o algoritmo de criptografia FPE-FFX com uma chave criptográfica e, em seguida, anexado com uma anotação alternativa, se especificada. Por design, o conjunto de caracteres e o comprimento do valor de entrada são preservados no valor de saída. Os valores criptografados podem ser identificados novamente usando a chave criptográfica original e todo o valor de saída, incluindo anotação alternativa. Para algumas considerações importantes sobre o uso desse método de criptografia, consulte Como preservar a criptografia de formato neste tópico.
- Hash criptográfico: um valor de entrada é substituído por um valor criptografado e com hash usando o código de autenticação de mensagem baseado em hash (HMAC, na sigla em inglês) e algoritmo de hash seguro (SHA)-256 no valor de entrada com uma chave criptográfica. A saída com hash da transformação tem sempre o mesmo tamanho e não pode ser reidentificada. Saiba mais sobre o formato dos valores tokenizados usando hash criptográfico.
Esses métodos de pseudonimização estão resumidos na tabela a seguir. As linhas da tabela são explicadas após a tabela.
| Criptografia determinística usando AES-SIV | Criptografia com preservação de formato | Hash criptográfico | |
|---|---|---|---|
| Tipo de criptografia | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Valores de entrada compatíveis | Ter no mínimo um caractere; sem limitações de conjuntos de caracteres. | Ter pelo menos 2 caracteres; ser codificado como ASCII. | Precisa ser uma string ou um valor inteiro. |
| Anotação alternativa | Opcional. | Opcional. | N/A |
| Ajuste de contexto | Opcional. | Opcional. | N/A |
| Conjunto de caracteres e comprimento preservados | ✗ | ✓ | ✗ |
| Reversível | ✓ | ✓ | ✗ |
| Integridade referencial | ✓ | ✓ | ✓ |
- Tipo de criptografia: o tipo de criptografia usado na transformação de desidentificação.
- Valores de entrada compatíveis: requisitos mínimos para valores de entrada.
- Anotação alternativa:uma anotação especificada pelo usuário que é anexada
a valores criptografados para fornecer contexto aos usuários e informações
para a Proteção de Dados Sensíveis usar na reidentificação de um valor
desidentificado. Uma anotação alternativa é necessária para a reidentificação de
dados não estruturados. É opcional ao transformar uma coluna de dados estruturados ou
tabulares com um
RecordTransformation. - Ajuste de contexto: uma referência a um campo de dados que ajuste o valor de entrada
para que os valores de entrada idênticos sejam desidentificados para diferentes valores
de saída. O ajuste de contexto é opcional ao transformar uma coluna de
dados estruturados ou tabulares, com um
RecordTransformation. Para mais informações, consulte Como usar os ajustes de contexto. - Conjunto de caracteres e comprimento preservado: se um valor desidentificado é composto pelo mesmo conjunto de caracteres que o valor original e se o comprimento do valor desidentificado corresponde ao do valor original.
- Gravidade: pode ser reidentificada usando a chave criptográfica, a anotação alternativa e qualquer ajuste de contexto.
- Integridade referencial:a integridade referencial permite que os registros mantenham o relacionamento entre si, mesmo depois que os dados são desidentificados individualmente. Da mesma chave criptográfica e ajuste de contexto, uma tabela de dados será substituída pela mesma forma ofuscada sempre que ela for transformada. Isso garante que as conexões entre os valores (e com os dados estruturados e registros) sejam preservadas, mesmo entre tabelas.
Como a tokenização funciona na Proteção de dados sensíveis
O processo básico de tokenização é o mesmo para os três métodos compatíveis com a proteção de dados sensíveis.
Etapa 1: a Proteção de dados sensíveis seleciona os dados para tokenizar. A maneira mais comum de fazer isso é usar um detector de infoType integrado ou personalizado para corresponder aos valores de dados confidenciais desejados. Se você estiver verificando dados estruturados (como uma tabela do BigQuery), também será possível realizar a tokenização em colunas inteiras de dados usando transformações de registro.
Para mais informações sobre as duas categorias de transformações (infoType e transformações de registro), consulte Transformações de desidentificação.
Etapa 2: com uma chave criptográfica, a Proteção de dados confidenciais criptografa cada valor de entrada. Há três maneiras de fornecer essa chave:
- Encapsulando-o usando o Cloud Key Management Service (Cloud KMS). Para ter o máximo de segurança, o Cloud KMS é o método preferido.
- Usando uma chave temporária, gerada pela Proteção de Dados Sensíveis no momento da desidentificação e, em seguida, descartada. Uma chave temporária mantém a integridade apenas por solicitação de API. Se você precisar de integridade ou planejar reidentificar esses dados, não use esse tipo de chave.
- Diretamente em formato de texto bruto. (Não recomendado.)
Para mais detalhes, consulte a seção Como usar chaves criptográficas, mais adiante neste tópico.
Etapa 3 (hash criptográfico e criptografia determinística apenas com AES-SIV): a Proteção de dados confidenciais codifica o valor criptografado usando base64. Com hash criptográfico, esse valor codificado é o token e o processo continua com a Etapa 6. Com a criptografia determinística usando o AES-SIV, esse valor criptografado e codificado é o valor alternativo, que é apenas um componente do token. O processo continua na Etapa 4.
Etapa 4 (preservação de formato e criptografia determinística apenas com AES-SIV):
a Proteção de Dados Sensíveis adiciona uma anotação alternativa opcional ao valor
criptografado. A anotação alternativa ajuda a identificar valores alternativos criptografados anexando
uma string descritiva definida por você. Por exemplo, sem
uma anotação, talvez você não consiga distinguir um número de telefone
desidentificado e um CPF desidentificado ou outro número de identificação. Além disso,
para reidentificar valores em dados não estruturados que foram desidentificados
usando o formato que preserva a criptografia ou a criptografia determinística, é preciso
especificar uma anotação alternativa. As anotações alternativas não são necessárias
ao transformar uma coluna de dados estruturados ou tabulares com um
RecordTransformation.
Etapa 5 (preservação de formato e criptografia determinística com AES-SIV apenas de dados estruturados): a Proteção de dados sensíveis pode usar o contexto opcional de outro campo para ajustar o token gerado. Isso permite que você altere o escopo do token. Por exemplo, suponha que você tenha um banco de dados de campanha de marketing que inclua endereços de e-mail e queira gerar tokens exclusivos para o mesmo endereço de e-mail "ajustado" pelo ID da campanha. Isso permite que alguém mescle dados do mesmo usuário na mesma campanha, mas não em diferentes campanhas. Se um ajuste de contexto for usado para criar o token, esse ajuste também será necessário para que as transformações de desidentificação sejam revertidas. Preservação de formato e criptografia determinística usando contextos de suporte AES-SIV. Saiba mais sobre como usar os ajustes de contexto.
Etapa 6: a Proteção de dados sensíveis substitui o valor original pelo valor desidentificado.
Comparação de valores tokenizados
Nesta seção, demonstramos como os tokens típicos parecem depois de serem
desidentificados usando cada um dos três métodos discutidos neste tópico. O valor de dados
confidenciais de exemplo é um número de telefone da América do Norte (1-206-555-0123).
Criptografia determinística usando AES-SIV
Com a desidentificação usando criptografia determinística e AES-SIV, um valor de entrada (e, opcionalmente, qualquer ajuste de contexto especificado) é criptografado usando AES-SIV com uma chave criptográfica, codificado usando base64 e, opcionalmente, anexado por uma anotação alternativa, se especificado. Esse método não preserva o conjunto de caracteres (ou "alfabeto") do valor de entrada. Para gerar a saída imprimível, o valor resultante é codificado em base64.
O token resultante, supondo que um InfoType alternativo tenha sido especificado, está no formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
O diagrama anotado a seguir mostra um token de exemplo: a saída de uma
operação de desidentificação usando criptografia determinística com AES-SIV no
valor 1-206-555-0123. O InfoType alternativo opcional foi definido como
NAM_PHONE_NUMB:

- Anotação alternativa
- InfoType alternativo (definido pelo usuário)
- Comprimento do caractere do valor transformado
- Valor alternativo (transformado)
Se você não especificar uma anotação alternativa, o token resultante será igual ao
valor transformado ou número 4 no diagrama anotado. Para reidentificar
dados não estruturados, todo o token é obrigatório, incluindo a anotação
alternativa. Ao transformar dados estruturados, como uma tabela, a anotação
alternativa é opcional. A proteção de dados sensíveis pode realizar a desidentificação
e a reidentificação em uma coluna inteira usando um
RecordTransformation
sem uma anotação alternativa.
Criptografia com preservação de formato
Com a desidentificação usando criptografia com preservação de formato, um valor de entrada (e, opcionalmente, qualquer ajuste de contexto especificado) é criptografado usando o modo FFX da criptografia de preservação de formato ("FPE-FFX") com uma chave criptográfica, e, opcionalmente, com uma anotação alternativa, se especificada.
Ao contrário dos outros métodos de tokenização descritos neste tópico, o valor alternativo de saída é o mesmo que o valor de entrada e não é codificado usando base64. Você define o conjunto de caracteres (ou "alfabeto") de que o valor criptografado é composto. Há três maneiras de especificar o alfabeto para a Proteção de Dados Sensíveis usar no valor de saída:
- Use um dos quatro valores enumerados que representam os quatro conjuntos de caracteres/alfabetos mais comuns.
- Use um valor radix, que especifica o tamanho do alfabeto. Especificar o
valor mínimo de radix de
2resulta em um alfabeto que consiste apenas em0e1. A especificação do valor máximo de radix de95resulta em um alfabeto que inclui todos os caracteres numéricos, caracteres alfanuméricos maiúsculos, caracteres alfanuméricos minúsculos e caracteres de símbolo. - Crie um alfabeto listando os caracteres exatos que serão usados. Por exemplo,
especificar
1234567890-*resultaria em um valor alternativo que é composto apenas de números, hífens e asteriscos.
A tabela a seguir lista quatro conjuntos de caracteres comuns pelo valor enumerado de cada um
(FfxCommonNativeAlphabet),
valor de radix
e lista dos caracteres do conjunto. A linha final lista o conjunto completo
de caracteres, que corresponde ao valor máximo de radix.
| Nome do conjunto de caracteres/alfabeto | Radix | Lista de caracteres |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
O token resultante, supondo que um InfoType alternativo tenha sido especificado, está no formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
O diagrama anotado a seguir é a saída de uma operação de desidentificação da Proteção de dados sensíveis
usando a criptografia de preservação de formato no valor
1-206-555-0123 usando um radix de 95. O InfoType alternativo opcional foi
definido como NAM_PHONE_NUMB:
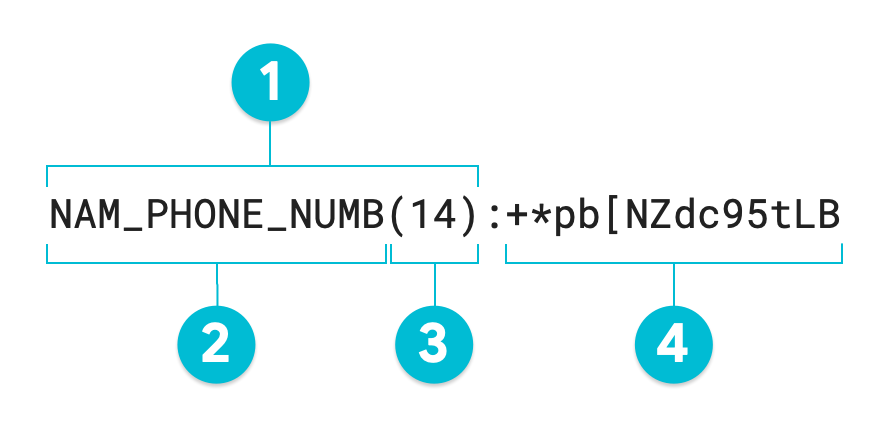
- Anotação alternativa
- InfoType alternativo (definido pelo usuário)
- Comprimento do caractere do valor transformado
- Valor alternativo (transformado): igual ao valor de entrada
Se você não especificar uma anotação alternativa, o token resultante será igual ao
valor transformado ou número 4 no diagrama anotado. Para reidentificar
dados não estruturados, todo o token é obrigatório, incluindo a anotação
alternativa. Ao transformar dados estruturados, como uma tabela, a anotação
alternativa é opcional. A proteção de dados sensíveis pode realizar a desidentificação
e a reidentificação em uma coluna inteira usando um
RecordTransformation
sem uma anotação alternativa.
Hash criptográfico
Com a desidentificação com hash criptográfico, um valor de entrada é em hash usando HMAC-SHA-256 com uma chave criptográfica e codificado usando base64. O valor desidentificado sempre é um tamanho uniforme, dependendo do tamanho da chave.
Ao contrário dos outros métodos de tokenização discutidos neste tópico, o hash criptográfico cria um token unidirecional. Ou seja, não é possível reverter a desidentificação por hash criptográfico.
Veja a seguir o resultado de uma operação de desidentificação usando hash
criptográfico no valor 1-206-555-0123. Essa saída é uma representação codificada
em base64 do valor de hash:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Como usar chaves criptográficas
Há três opções de chaves criptográficas que é possível usar com os métodos de desidentificação criptográfica na Proteção de dados sensíveis:
Chave criptográfica encapsulada do Cloud KMS: esse é o tipo mais seguro de chave criptográfica disponível para uso com os métodos de desidentificação da proteção de dados sensíveis. Uma chave encapsulada do Cloud KMS consiste em uma chave criptográfica de 128, 192 ou 256 bits que foi criptografada usando outra chave. Você fornece a primeira chave criptográfica, que é encapsulada usando uma chave criptográfica armazenada do Cloud Key Management Service. Esses tipos de chaves são armazenados no Cloud KMS para reidentificação posterior. Para mais informações sobre como criar e encapsular uma chave para fins de desidentificação e reidentificação, consulte Guia de início rápido: como desidentificar e reidentificar texto confidencial.
Chave criptográfica transitória: uma chave criptográfica transitória é gerada pela Proteção de dados sensíveis no momento da desidentificação e, em seguida, descartada. Por isso, não use uma chave criptográfica transitória com nenhum método de desidentificação criptográfico que você queira reverter. As chaves criptográficas temporárias só mantêm a integridade por solicitação de API. Se você precisar de integridade em mais de uma solicitação de API ou planejar reidentificar os dados, não use esse tipo de chave.
Chave criptográfica desencapsulada: uma chave desencapsulada é uma chave criptográfica codificada em base64 de 128, 192 ou 256 bits fornecida na solicitação de desidentificação para a API DLP. Você é responsável por manter esses tipos de chaves criptográficas seguros para reidentificação posterior. Devido ao risco de vazamento acidental da chave, esses tipos de chaves não são recomendados. Essas chaves podem ser úteis para testes, mas, para cargas de trabalho de produção, recomenda-se uma chave criptográfica encapsulada do Cloud KMS.
Para saber mais sobre as opções disponíveis ao usar chaves criptográficas, consulte
CryptoKey
na referência da API DLP.
Como usar ajustes de contexto
Por padrão, todos os métodos de transformação criptográfica de desidentificação têm integridade referencial, sejam tokens de saída unidirecionais ou bidirecionais. Ou seja, com a mesma chave criptográfica, um valor de entrada é sempre transformado para o mesmo valor criptografado. Em situações em que dados ou padrões de dados repetitivos podem ocorrer, o risco de reidentificação aumenta. Em vez disso, para que o mesmo valor de entrada seja sempre transformado em um valor criptografado diferente, é possível especificar um ajuste de contexto exclusivo.
Você especifica um ajuste de contexto (chamado apenas de uma
context
na API DLP) ao transformar dados tabulares, uma vez que o ajuste é
efetivamente um ponteiro para uma coluna de dados, como um identificador.
A proteção de dados sensíveis usa o valor no campo especificado pelo ajuste de
contexto ao criptografar o valor de entrada. Para garantir que o valor criptografado seja
sempre um valor exclusivo, especifique uma coluna para o ajuste que contenha identificadores
exclusivos.
Considere este exemplo simples. A tabela a seguir mostra vários registros médicos, sendo que alguns incluem IDs de pacientes duplicados.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5.440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
Se você instruir a proteção de dados sensíveis a desidentificar os IDs do paciente na
tabela, ela desidentificará os IDs dos pacientes aos mesmos valores por padrão, conforme
mostrado na tabela a seguir. Por exemplo, as duas instâncias do ID
do paciente "43789" são desidentificadas para "47222." A coluna patient_id mostra os
valores do token após a pseudonimização usando FPE-FFX e não inclui
anotações alternativas. Consulte Criptografia com preservação de formato para mais
informações.
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5.440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
Isso significa que o escopo da integridade referencial está em todo o conjunto de dados.
Para restringir o escopo para evitar esse comportamento, especifique um ajuste de contexto. É possível especificar qualquer coluna como um ajuste de contexto, mas, para garantir que cada valor desidentificado seja exclusivo, especifique uma coluna para que cada valor seja exclusivo.
Suponha que você queira ver se o mesmo paciente aparece por valor icd10_codes,
mas não se o mesmo paciente aparece em valores icd10_codes diferentes. Para
fazer isso, especifique a coluna icd10_codes como o ajuste de contexto.
Esta é a tabela após desidentificar a coluna patient_id usando a
coluna icd10_codes como um ajuste de contexto:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5.440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
Observe que os quartos e quintos valores patient_id desidentificados (29460) são os
mesmos porque não só os valores originais de patient_id são idênticos, mas, também, os valores icd10_codes das duas linhas eram idênticos. Como você precisa executar
uma análise com IDs de pacientes consistentes dentro do escopo do valor icd10_codes,
esse comportamento é o que você está procurando.
Para separar completamente a integridade referencial entre os valores patient_id e
icd10_codes, use a coluna record_id como um ajuste
de contexto:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5.440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
Observe que cada valor patient_id desidentificado na tabela agora é exclusivo.
Para saber como usar os ajustes de contexto na API DLP, observe o uso
de context nos seguintes tópicos de referência do método de transformação:
- Criptografia com preservação de formato:
CryptoReplaceFfxFpeConfig - Criptografia determinística usando AES-SIV:
CryptoDeterministicConfig - Mudança de data:
DateShiftConfig
A seguir
Analise exemplos de código que demonstram como tokenizar dados confidenciais (em inglês).
Saiba como desidentificar dados usando a API DLP.