이 페이지에서는 데이터를 이해하고 데이터 거버넌스 워크플로를 사용 설정하는 데 도움이 되는 두 가지 Sensitive Data Protection 서비스인 검색 서비스 및 검사 서비스에 대해 설명하고 비교합니다.
민감한 데이터 검색
검색 서비스는 조직 전체의 데이터를 모니터링합니다. 이 서비스는 지속적으로 실행되며 데이터를 자동으로 검색, 분류, 프로파일링합니다. 검색은 사용자가 알지 못하는 데이터 리소스를 포함하여 저장하는 데이터의 위치와 특성을 이해하는 데 도움이 될 수 있습니다. 알 수 없는 데이터 (섀도 데이터라고도 함)는 일반적으로 알려진 데이터와 동일한 수준의 데이터 거버넌스 및 위험 관리를 거치지 않습니다.
다양한 범위에서 검색을 구성합니다. 데이터의 하위 집합마다 프로파일링 일정을 다르게 설정할 수 있습니다. 프로파일링할 필요가 없는 데이터의 하위 집합을 제외할 수도 있습니다.
검색 스캔 출력: 데이터 프로필
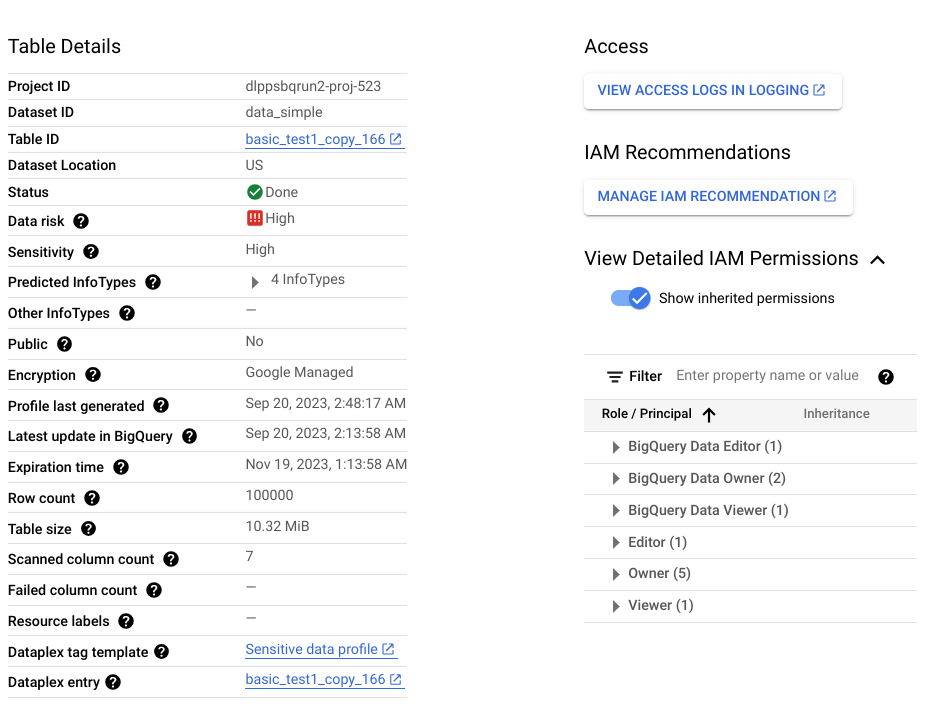
검색 스캔 출력은 범위 내에 있는 각 데이터 리소스의 데이터 프로필 집합입니다. 예를 들어 BigQuery 또는 Cloud SQL 데이터의 검색 스캔은 프로젝트, 테이블, 열 수준에서 데이터 프로필을 생성합니다.
데이터 프로필에는 프로파일링된 리소스에 관한 측정항목과 통계가 포함됩니다. 여기에는 데이터 분류(또는 infoTypes), 민감도 수준, 데이터 위험 수준, 데이터 크기, 데이터 형태 및 데이터의 특성과 데이터 보안 상황(데이터의 보안 수준)을 설명하는 기타요소가 포함됩니다. 데이터 프로필을 사용하여 테이블에 대한 액세스 정책을 설정하는 등 데이터를 보호하는 방법에 대해 정보에 입각한 결정을 내릴 수 있습니다.
각 행에 고유한 신용카드 번호가 있고 null 값이 없는 ccn이라는 BigQuery 열이 있다고 가정해 보겠습니다. 생성된 열 수준 데이터 프로필에는 다음 세부정보가 포함됩니다.
| 표시 이름 | 값 |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
또한 이 열 수준 프로필은 데이터 위치, 암호화 상태, 테이블이 공개적으로 공유되는지 여부와 같은 통계를 제공하는 테이블 수준 프로필의 일부입니다. Google Cloud 콘솔에서 테이블의 Cloud Logging 항목과 테이블의 역할이 있는 IAM 보안 주체를 볼 수도 있습니다.
데이터 프로필에서 사용할 수 있는 측정항목 및 통계의 전체 목록은 측정항목 참조를 참고하세요.
검색을 사용해야 하는 경우
데이터 위험 관리 방법을 계획할 때는 검색부터 시작하는 것이 좋습니다. 검색 서비스를 사용하면 데이터를 광범위하게 확인하고 문제의 알림, 보고, 해결을 사용 설정할 수 있습니다.
또한 검색 서비스는 구조화되지 않은 데이터가 있을 수 있는 리소스를 식별하는 데 도움이 됩니다. 이러한 리소스는 철저한 검사가 필요할 수 있습니다. 비정형 데이터는 0~1 범위의 높은 자유 텍스트 점수로 지정됩니다.
민감한 정보 검사
검사 서비스는 단일 리소스를 철저히 스캔하여 민감한 정보의 각 개별 인스턴스를 찾습니다. 검사에서는 감지된 각 인스턴스에 대해 발견을 생성합니다.
검사 작업은 검사할 데이터를 정확히 파악하는 데 도움이 되는 다양한 구성 옵션을 제공합니다. 예를 들어 샘플링을 사용 설정하여 검사할 데이터를 특정 행 수(BigQuery 데이터의 경우) 또는 특정 파일 형식(Cloud Storage 데이터의 경우)으로 제한할 수 있습니다. 데이터가 생성되거나 수정된 특정 기간을 타겟팅할 수도 있습니다.
데이터를 지속적으로 모니터링하는 검색과 달리 검사는 주문형 작업입니다. 하지만 작업 트리거라는 반복 검사 작업을 예약할 수 있습니다.
검사 스캔 출력: 발견 항목
각 발견 항목에는 감지된 인스턴스의 위치, 잠재적인 infoType, 발견 항목이 infoType과 일치하는 확실성(가능성이라고도 함)과 같은 세부정보가 포함됩니다. 설정에 따라 발견 항목과 관련된 실제 문자열을 가져올 수도 있습니다. Sensitive Data Protection에서 이 문자열을 인용이라고 합니다.
검사 발견 항목에 포함된 세부정보의 전체 목록은 Finding을 참조하세요.
검사를 사용해야 하는 경우
검사는 구조화되지 않은 데이터(예: 사용자가 작성한 댓글이나 리뷰)를 조사하고 개인 식별 정보(PII)의 각 인스턴스를 식별해야 하는 경우에 유용합니다. 검색 스캔에서 구조화되지 않은 데이터가 포함된 리소스를 식별하면 해당 리소스에 대해 검사 스캔을 실행하여 개별 발견 항목에 대한 세부정보를 가져오는 것이 좋습니다.
검사를 사용하지 말아야 하는 경우
다음 조건이 모두 적용되는 경우 리소스를 검사하는 것은 유용하지 않습니다. 검색 스캔은 검사 스캔이 필요한지 여부를 결정하는 데 도움이 될 수 있습니다.
- 리소스에 구조화된 데이터만 있습니다. 즉, 사용자 댓글이나 리뷰와 같은 자유 형식 데이터 열이 없습니다.
- 해당 리소스에 저장된 infoType을 이미 알고 있습니다.
예를 들어 검색 스캔의 데이터 프로필이 특정 BigQuery 테이블에 구조화되지 않은 데이터가 있는 열이 없지만 고유한 신용카드 번호 열이 있다고 가정해 보겠습니다. 이 경우 테이블에서 신용카드 번호를 검사하는 것은 유용하지 않습니다. 검사에서는 열의 각 항목에 대한 결과를 생성합니다. 행이 100만 개이고 각 행에 신용카드 번호가 1개 포함된 경우 검사 작업에서 CREDIT_CARD_NUMBER infoType에 대한 발견 항목이 100만 개 생성됩니다. 이 예시에서는 검색 스캔이 열에 고유한 신용카드 번호가 포함되어 있음을 나타내므로 검사가 필요하지 않습니다.
데이터 상주, 처리, 스토리지
검색 및 검사 모두 데이터 상주 요구사항을 지원합니다.
- 검색 서비스는 데이터가 있는 위치에서 데이터를 처리하고 생성된 데이터 프로필을 프로파일링된 데이터와 동일한 리전 또는 멀티 리전에 저장합니다. 자세한 내용은 데이터 상주 고려사항을 참조하세요.
- Google Cloud 스토리지 시스템 내에서 데이터를 검사할 때 검사 서비스는 데이터가 있는 리전과 동일한 리전에서 데이터를 처리하고 검사 작업을 해당 리전에 저장합니다. 하이브리드 작업 또는
content메서드를 통해 데이터를 검사할 때 검사 서비스를 사용하면 데이터를 처리할 위치를 지정할 수 있습니다. 자세한 내용은 데이터 저장 방식을 참고하세요.
비교 요약: 검색 및 검사 서비스
| 탐색 | 검사 | |
|---|---|---|
| 혜택 |
|
|
| 비용 |
소비 모드에서 10TB는 월 약 300달러입니다. |
10TB의 경우 스캔당 약 미화 10,000달러가 소요됩니다. |
| 지원되는 데이터 소스 | BigLake BigQuery Cloud Run 함수 환경 변수 Cloud Run 서비스 버전 환경 변수 Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore 하이브리드(모든 소스)1 |
| 지원되는 범위 |
|
단일 BigQuery 테이블, Cloud Storage 버킷 또는 Datastore 종류 |
| 기본 제공 검사 템플릿 | 예 | 예 |
| 기본 제공 및 커스텀 infoType | 예 | 예 |
| 스캔 출력 | 지원되는 모든 데이터의 대략적인 개요 (데이터 프로필) | 검사된 리소스의 민감한 정보에 대한 구체적인 발견 항목입니다. |
| BigQuery에 결과 저장 | 예 | 예 |
| Dataplex 범용 카탈로그에 태그로 전송 (지원 중단됨) | 예 | 예 |
| Dataplex 범용 카탈로그에 관점으로 전송 | 예 | 아니요 |
| Security Command Center에 결과 게시 | 예 | 예 |
| Google Security Operations에 발견 항목 게시 | 조직 수준 및 폴더 수준 검색의 경우 예 | No |
| Pub/Sub에 게시 | 예 | 예 |
| 데이터 상주 지원 | 예 | 예 |
1 하이브리드 검사의 가격 모델은 다릅니다. 자세한 내용은 모든 소스의 데이터 검사 를 참고하세요.
다음 단계
- 데이터 위험 완화를 위한 권장 전략 살펴보기(이 시리즈의 다음 문서)