Auf dieser Seite wird beschrieben, wie Sie die Kosten für das Erstellen von Profilen für BigQuery-Daten in einem Projekt schätzen können. Wenn Sie eine Schätzung für eine Organisation oder einen Ordner erstellen möchten, lesen Sie den Abschnitt Kosten für die Datenprofilerstellung für eine Organisation oder einen Ordner schätzen.
Weitere Informationen zum Erstellen von Profilen für BigQuery-Daten finden Sie unter Datenprofile für BigQuery-Daten.
Übersicht
Bevor Sie mit dem Generieren von Datenprofilen beginnen, können Sie eine Schätzung durchführen, um zu sehen, wie viele BigQuery-Daten Sie haben und wie viel es kosten könnte, ein Profil dieser Daten zu erstellen. Um eine Schätzung durchzuführen, erstellen Sie eine Schätzung.
Wenn Sie eine Schätzung erstellen, geben Sie die Ressource (Organisation, Ordner oder Projekt) an, die die Daten enthält, für die Sie ein Profil erstellen möchten. Mit Filtern können Sie die Datenauswahl optimieren. Sie können auch Bedingungen festlegen, die erfüllt sein müssen, bevor Sensitive Data Protection ein Profil für eine Tabelle erstellt. Sensitive Data Protection basiert die Schätzung auf der Form, Größe und Art der Daten zum Zeitpunkt der Schätzung.
Jede Schätzung enthält Details wie die Anzahl der übereinstimmenden Tabellen in der Ressource, die Gesamtgröße aller Tabellen und die geschätzten Kosten für das einmalige und monatliche Profiling der Ressource.
Weitere Informationen zur Berechnung der Preise finden Sie unter Preise für die Datenprofilerstellung.
Preisschätzung
Das Erstellen eines Kostenvoranschlags ist kostenlos.
Kundenbindung
Jede Schätzung wird nach 28 Tagen automatisch gelöscht.
Hinweise
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle DLP-Administrator (roles/dlp.admin) für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen und Verwalten von Kostenschätzungen für die Datenprofilerstellung benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Prüfen Sie, ob die Cloud Data Loss Prevention API für Ihr Projekt aktiviert ist:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle DLP-Administrator (
roles/dlp.admin) für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen und Verwalten von Kostenschätzungen für die Datenprofilerstellung benötigen. Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Rufen Sie die Seite Datenprofilschätzung erstellen auf.
Wählen Sie Ihr Projekt aus.
- Klicken Sie auf Filter und Bedingungen hinzufügen.
Im Abschnitt Filter definieren Sie einen oder mehrere Filter, die angeben, welche Tabellen in den Umfang der Schätzung fallen.
Geben Sie mindestens eines der folgenden Elemente an:
- Eine Projekt-ID oder ein regulärer Ausdruck, der ein oder mehrere Projekte angibt.
- Eine Dataset-ID oder ein regulärer Ausdruck, der ein oder mehrere Datasets angibt.
- Eine Tabellen-ID oder ein regulärer Ausdruck, der eine oder mehrere Tabellen angibt.
Reguläre Ausdrücke müssen der RE2-Syntax entsprechen.
Wenn Sie beispielsweise möchten, dass alle Tabellen in einem Dataset in den Filter einbezogen werden, geben Sie die ID des Datasets an und lassen Sie die beiden anderen Felder leer.
Wenn Sie weitere Filter hinzufügen möchten, klicken Sie auf Filter hinzufügen und wiederholen Sie diesen Schritt.
Wenn die durch Ihre Filter definierten Datenteilmengen aus der Schätzung ausgeschlossen werden sollen, deaktivieren Sie die Option Übereinstimmende Tabellen in die Schätzung einbeziehen. Wenn Sie diese Option deaktivieren, werden die im restlichen Teil dieses Abschnitts beschriebenen Bedingungen ausgeblendet.
Optional: Geben Sie im Abschnitt Bedingungen alle Bedingungen an, die die übereinstimmenden Tabellen erfüllen müssen, damit sie in die Schätzung einbezogen werden. Wenn Sie diesen Schritt überspringen, berücksichtigt der Schutz sensibler Daten alle unterstützten Tabellen, die Ihren Filtern entsprechen, unabhängig von ihrer Größe und ihrem Alter.
Konfigurieren Sie die folgenden Optionen:
Mindestbedingungen: Wenn Sie kleine oder neue Tabellen aus der Schätzung ausschließen möchten, legen Sie eine Mindestanzahl von Zeilen oder ein Mindestalter für die Tabelle fest.
Zeitbedingung: Wenn Sie alte Tabellen ausschließen möchten, aktivieren Sie die Zeitbedingung. Wählen Sie dann ein Datum und eine Uhrzeit aus. Alle Tabellen, die an oder vor diesem Datum erstellt wurden, werden aus der Schätzung ausgeschlossen.
Wenn Sie die Zeitbedingung beispielsweise auf 04.05.2022, 23:59 Uhr festlegen, werden alle Tabellen, die am oder vor dem 04.05.2022 um 23:59 Uhr erstellt wurden, aus der Schätzung ausgeschlossen.
Tabellen für die Profilerstellung: Wenn Sie die Typen von Tabellen angeben möchten, die in die Schätzung einbezogen werden sollen, wählen Sie Nur Tabellen eines bestimmten Typs oder bestimmter Typen einschließen aus. Wählen Sie dann die Tabellentypen aus, die Sie einfügen möchten.
Wenn Sie diese Bedingung nicht aktivieren oder keine Tabellentypen auswählen, werden alle unterstützten Tabellen in die Schätzung einbezogen.
Angenommen, Sie haben die folgende Konfiguration:
Mindestbedingungen
- Mindestanzahl von Zeilen: 10 Zeilen
- Mindestdauer: 24 Stunden
Zeitbedingung
- Zeitstempel: 04.05.2022, 23:59 Uhr
Tabellen, für die ein Profil erstellt werden soll
Die Option Nur Tabellen eines bestimmten Typs oder bestimmter Typen einschließen ist ausgewählt. In der Liste der Tabellentypen ist nur BigLake-Profiltabellen ausgewählt.
In diesem Fall werden alle Tabellen, die am oder vor dem 5. Mai 2022 um 23:59 Uhr erstellt wurden, von Sensitive Data Protection ausgeschlossen. Von den Tabellen, die nach diesem Datum und dieser Uhrzeit erstellt wurden, erstellt der Schutz sensibler Daten nur für die BigLake-Tabellen ein Profil, die entweder 10 Zeilen haben oder mindestens 24 Stunden alt sind.
Klicken Sie auf Fertig.
Wenn Sie weitere Filter und Bedingungen hinzufügen möchten, klicken Sie auf Filter und Bedingungen hinzufügen und wiederholen Sie die vorherigen Schritte.
Das letzte Element in der Liste der Filter und Bedingungen ist immer Standardfilter und ‑bedingungen. Diese Standardeinstellung wird auf die Tabellen in Ihrem Projekt angewendet, die keinem der von Ihnen erstellten Filter und Bedingungen entsprechen.

Wenn Sie die Standardfilter und ‑bedingungen anpassen möchten, klicken Sie auf Filter und Bedingungen bearbeiten und nehmen Sie die gewünschten Änderungen vor.
Wählen Sie in der Liste Ressourcenstandort die Region aus, in der Sie diese Schätzung speichern möchten.
Der Speicherort, an dem Sie die Schätzung speichern, hat keinen Einfluss auf die zu scannenden Daten. Außerdem wirkt sich dies nicht darauf aus, wo die Datenprofile später gespeichert werden. Die Daten werden in derselben Region gescannt, in der sie gespeichert sind (wie in BigQuery festgelegt). Weitere Informationen finden Sie unter Überlegungen zum Datenstandort.
Prüfen Sie Ihre Einstellungen und klicken Sie auf Erstellen.
Rufen Sie die Liste der Schätzungen auf.
Klicken Sie auf den Kostenvoranschlag, den Sie aufrufen möchten. Die Schätzung enthält Folgendes:
- Die Anzahl der Tabellen in der Ressource abzüglich der Tabellen, die Sie durch Filter und Bedingungen ausgeschlossen haben.
- Die Gesamtmenge der Daten, die den Tabellen entsprechen.
- Die Anzahl der Aboeinheiten, die erforderlich sind, um diese Datenmenge jeden Monat zu analysieren.
- Die Kosten der ersten Erkennung, die den ungefähren Kosten für die Profilerstellung der gefundenen Tabellen entsprechen. Diese Schätzung basiert nur auf einer Momentaufnahme der aktuellen Daten und berücksichtigt nicht, wie stark Ihre Daten in einem bestimmten Zeitraum wachsen.
- Zusätzliche Kostenschätzungen für die Profilerstellung nur für Tabellen, die jünger als 6, 12 oder 24 Monate sind. Diese zusätzlichen Schätzungen sollen Ihnen zeigen, wie Sie die Kosten für die Datenprofilerstellung senken können, indem Sie die Datenabdeckung weiter einschränken.
- Die geschätzten monatlichen Kosten für das Erstellen von Profilen für Ihre Daten, vorausgesetzt, Ihre BigQuery-Nutzung ist jeden Monat dieselbe wie in diesem Monat.
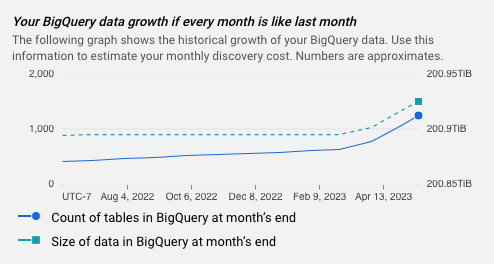
- Ein Diagramm, das das Wachstum Ihrer BigQuery-Daten im Zeitablauf zeigt.
- Die von Ihnen festgelegten Konfigurationsdetails.
- Weitere Informationen zu den Preisen für die Datenprofilerstellung
- Weitere Informationen zu Datenprofilen für BigQuery-Daten
- Informationen zum Erstellen von Profildaten für eine Organisation oder einen Ordner
- Weitere Informationen
Schätzung erstellen
In den folgenden Abschnitten finden Sie weitere Informationen zu den Schritten auf der Seite Schätzung für Datenprofil erstellen. Klicken Sie am Ende jedes Abschnitts auf Weiter.
Zu scannende Ressource auswählen
Achten Sie darauf, dass Gesamtes Projekt scannen ausgewählt ist.Eingabefilter und Bedingungen
Sie können diesen Abschnitt überspringen, wenn Sie alle BigQuery-Tabellen im Projekt in Ihre Schätzung einbeziehen möchten.In diesem Abschnitt erstellen Sie Filter, um bestimmte Teilmengen Ihrer Daten anzugeben, die in die Schätzung einbezogen oder aus dieser ausgeschlossen werden sollen. Für Teilmengen, die Sie in die Schätzung einbeziehen, geben Sie auch alle Bedingungen an, die eine Tabelle in der Teilmenge erfüllen muss, um in die Schätzung aufgenommen zu werden.
So legen Sie Filter und Bedingungen fest:
Standort zum Speichern der Schätzung festlegen
Sensitive Data Protection erstellt die Schätzung und fügt sie der Liste der Schätzungen hinzu. Anschließend wird die Schätzung ausgeführt.
Je nachdem, wie viele Daten in der Ressource enthalten sind, kann es bis zu 24 Stunden dauern, bis die Schätzung abgeschlossen ist. In der Zwischenzeit können Sie die Seite „Schutz sensibler Daten“ schließen und später noch einmal nachsehen. In der Google Cloud Console wird eine Benachrichtigung angezeigt, wenn die Schätzung verfügbar ist.
Schätzung ansehen
Diagramm für Schätzungen
Jede Schätzung enthält ein Diagramm, das das bisherige Wachstum Ihrer BigQuery-Daten zeigt. Anhand dieser Informationen lassen sich die monatlichen Kosten für das Datenprofiling schätzen.
Nächste Schritte