La generalización es el proceso de tomar un valor distintivo y abstraerlo en un valor más general y menos distintivo. La generalización intenta conservar la utilidad de los datos y, al mismo tiempo, reducir la capacidad de identificación de los datos.
Puede haber muchos niveles de generalización en función del tipo de datos. La generalización necesaria es algo que se puede medir en un conjunto de datos o en una población real mediante técnicas como las que se incluyen en el análisis de riesgos de Protección de Datos Sensibles.
Una técnica de generalización habitual que admite Protección de Datos Sensibles es el agrupamiento en contenedores. Con la creación de contenedores, se agrupan los registros en contenedores más pequeños para minimizar el riesgo de que un atacante asocie información sensible con información de identificación. De esta forma, se conservarán el significado y la utilidad, pero también se ocultarán los valores individuales que tengan muy pocos participantes.
Situación de asignación a segmentos 1
Imaginemos el siguiente caso de asignación a contenedores numéricos: una base de datos almacena las puntuaciones de satisfacción de los usuarios, que van del 0 al 100. La base de datos tiene un aspecto similar al siguiente:
| user_id | puntuación |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | ... |
Al analizar los datos, te das cuenta de que los usuarios rara vez usan algunos valores. De hecho, hay algunas puntuaciones que solo se corresponden con un usuario. Por ejemplo, la mayoría de los usuarios eligen 0, 25, 50, 75 o 100. Sin embargo, cinco usuarios eligieron 95 y solo uno eligió 92. En lugar de conservar los datos sin procesar, puedes generalizar estos valores en grupos y eliminar los grupos con muy pocos participantes. En función de cómo se usen los datos, generalizarlos de esta forma podría ayudar a evitar la reidentificación.
Puedes eliminar estas filas de datos atípicos o intentar conservar su utilidad mediante la creación de contenedores. En este ejemplo, vamos a agrupar todos los valores según lo siguiente:
- De 0 a 25: "Bajo"
- 26-75: "Medio"
- 76-100: "Alto"
La creación de contenedores en Protección de Datos Sensibles es una de las muchas transformaciones primitivas disponibles para la desidentificación. La siguiente configuración JSON muestra cómo implementar este escenario de asignación a contenedores en la API DLP. Este JSON se puede incluir en una solicitud al método
content.deidentify:
C#
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Go
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Java
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
PHP
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
Situación de agrupación en contenedores 2
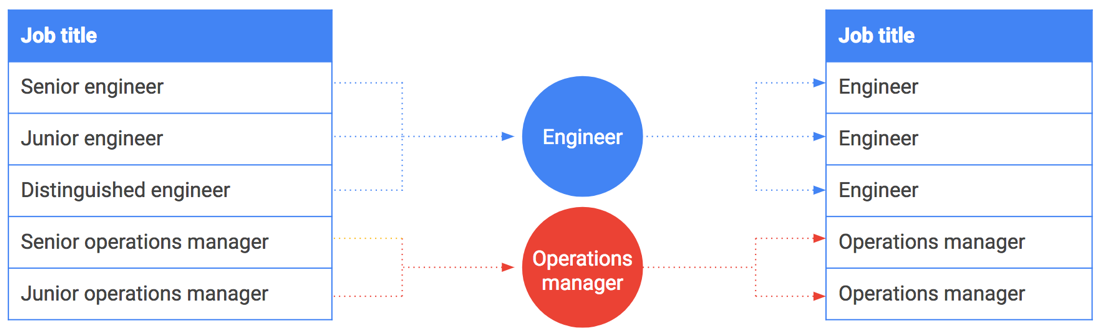
También se puede usar el agrupamiento en contenedores en cadenas o valores enumerados. Supongamos que quieres compartir datos de salarios e incluir los puestos de trabajo. Sin embargo, algunos cargos, como el de director general o ingeniero distinguido, pueden estar vinculados a una persona o a un grupo reducido de personas. Estos puestos se asignan fácilmente a los empleados que los ocupan.
La segmentación también puede ser útil en este caso. En lugar de incluir cargos exactos, generalízalos y agrúpalos. Por ejemplo, "Ingeniero sénior", "Ingeniero junior" e "Ingeniero distinguido" se generalizan y se agrupan en "Ingeniero". En la siguiente tabla se muestra cómo se agrupan puestos específicos en familias de puestos.
Otros casos
En estos ejemplos, hemos aplicado la transformación a datos estructurados. La creación de contenedores también se puede usar en ejemplos no estructurados, siempre que el valor se pueda clasificar con un infoType predefinido o personalizado. A continuación, se muestran algunos ejemplos:
- Clasificar fechas y agruparlas en intervalos de años
- Clasifica los nombres y agrúpalos en función de la primera letra (A-M, N-Z)
Recursos
Para obtener más información sobre la generalización y la agrupación en contenedores, consulta el artículo Desidentificar datos sensibles en contenido de texto.
Para consultar la documentación de la API, vaya a:
projects.content.deidentifymethodBucketingConfigtransformación: segmenta los valores en función de intervalos personalizados.FixedSizeBucketingConfigTransformación: agrupa los valores en función de intervalos de tamaño fijo.