Bei der Generalisierung wird ein Unterscheidungswert ausgewählt und zu einem allgemeineren, weniger unterscheidenden Wert abstrahiert. Mit Generalisierungen wird versucht, den Nutzen der Daten zu erhalten, aber gleichzeitig deren Identifizierbarkeit zu reduzieren.
Je nach Datentyp kann es viele Generalisierungsebenen geben. In welchem Umfang Generalisierung erforderlich ist, können Sie für ein Dataset ebenso wie für die gesamte Weltbevölkerung bemessen. Hierfür verwendete Techniken werden in Methoden zur Risikoanalyse mit Sensitive Data Protection beschrieben.
Eine häufig verwendete Generalisierungstechnik, die von Sensitive Data Protection unterstützt wird, ist das Bucketing. Beim Bucketing fassen Sie Datensätze zu kleineren Buckets zusammen, um das Risiko zu minimieren, dass ein Angreifer sensible Daten mit identifizierenden Informationen verknüpft. Hierbei werden der Sinn und der Nutzen bewahrt, aber es verschleiert auch individuelle Werte, die zu selten auftreten.
Bucketing-Szenario 1
Betrachten Sie dieses numerische Bucketing-Szenario: In einer Datenbank werden Punktzahlen zur Bewertung der Zufriedenheit von Nutzern gespeichert, die von 0 bis 100 reichen. Die Datenbank sieht in etwa so aus:
| user_id | Punktzahl |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| … | … |
Beim Scannen der Daten stellen Sie fest, dass einige Werte von den Nutzern nur selten verwendet werden. Es gibt einige Punktzahlen, die jeweils nur von einem Nutzer vergeben wurden. Zum Beispiel wählen die meisten Nutzer Werte wie 0, 25, 50, 75 oder 100. Fünf Nutzer vergaben 95 Punkte und nur ein Nutzer vergab 92 Punkte. Anstatt die Rohdaten beizubehalten, können Sie diese Werte in Gruppen generalisieren und Gruppen mit zu wenigen Werten ausschließen. Je nachdem, wie die Daten verwendet werden, kann eine Generalisierung auf diese Weise dazu beitragen, eine erneute Identifizierung zu verhindern.
Sie können Zeilen mit Ausreißerdaten entfernen oder versuchen, deren Nutzen mithilfe des Bucketings zu erhalten. Für dieses Beispiel gruppieren wir die Werte so:
- 0 bis 25: "Niedrig"
- 26 bis 75: "Mittel"
- 76 bis 100: "Hoch"
Bucketing in Sensitive Data Protection ist eine von vielen einfachen Transformationen, die für die De-Identifikation verfügbar sind. Die folgende JSON-Konfiguration veranschaulicht, wie dieses Bucketing-Szenario in der DLP API umgesetzt werden kann. Diese JSON könnte in eine Anfrage an die Methode content.deidentify eingeschlossen werden:
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für Sensitive Data Protection finden Sie unter Sensitive Data Protection-Clientbibliotheken.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
Bucketing-Szenario 2
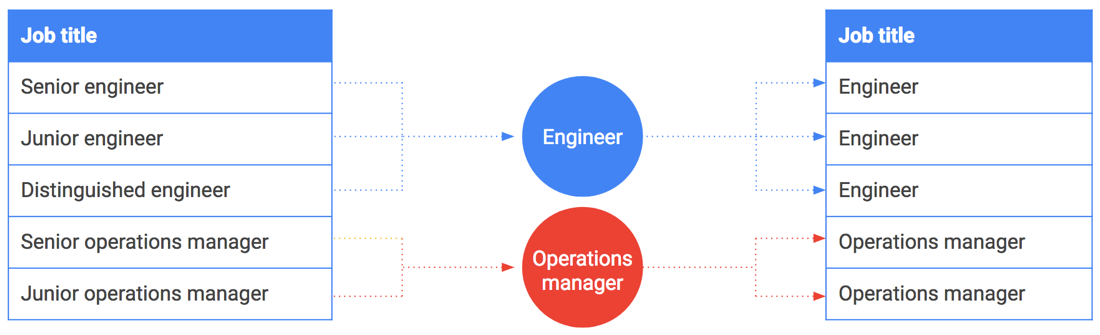
Bucketing kann auch für Strings oder Aufzählungswerte verwendet werden. Angenommen, Sie möchten Gehaltsdaten freigeben und Berufsbezeichnungen hinzufügen. Einige Berufsbezeichnungen, wie zum Beispiel CEO oder Distinguished Engineer treffen jedoch nur auf eine Person oder eine kleine Gruppe von Personen zu. Solche Berufsbezeichnungen können den jeweiligen Angestellten leicht zugeordnet werden.
Auch hier ist Bucketing sinnvoll. Statt die genauen Berufsbezeichnungen einzubinden, können Sie sie generalisieren und gruppieren. Zum Beispiel werden "Senior Engineer", "Junior Engineer" und "Distinguished Engineer" generalisiert und zu "Engineer" zusammengefasst. Die folgende Tabelle veranschaulicht, wie Berufsbezeichnungen in Berufsgruppen gruppiert werden können.
Weitere Szenarien
In diesen Beispielen wurde die Transformation auf strukturierte Daten angewendet. Bucketing kann auch für unstrukturierte Daten verwendet werden, sofern der Wert mit einem vordefinierten oder benutzerdefinierten infoType klassifiziert werden kann. Hier einige Beispielszenarien:
- Datumsangaben klassifizieren und zu Jahrgängen zusammenfassen
- Namen klassifizieren und auf der Grundlage ihrer Anfangsbuchstaben in Gruppen zusammenfassen (A – M, N – Z)
Ressourcen
Weitere Informationen zur Generalisierung und zum Bucketing finden Sie unter Sensible Daten in Textinhalten de-identifizieren.
Die API-Dokumentation finden Sie unter:
projects.content.deidentify-Methode- Transformation
BucketingConfig: Gruppiert Werte auf der Grundlage benutzerdefinierter Bereiche - Transformation
FixedSizeBucketingConfig: Gruppiert Werte auf der Grundlage fester Größenbereiche