k-anonimato é uma propriedade que indica a capacidade de reidentificação dos registros de um conjunto de dados. Um conjunto de dados é k-anônimo quando os semi-identificadores de cada pessoa contida nele são idênticos a uma quantidade de, no mínimo, k – 1 outra pessoa também contida no conjunto.
É possível calcular o valor de k-anonimato com base em uma ou mais colunas ou campos de um conjunto de dados. Neste tópico, demonstramos como calcular valores de k-anonimato para um conjunto de dados usando a Proteção de dados sensíveis. Para mais informações sobre k-anonimato ou análise de risco em geral, consulte o tópico sobre o conceito de análise de risco antes de continuar.
Antes de começar
Antes de continuar, verifique se você fez o seguinte:
- Faça login na sua Conta do Google.
- No console do Google Cloud , na página do seletor de projetos, selecione ou crie um projeto do Google Cloud . Acessar o seletor de projetos
- Verifique se o faturamento está ativado para seu projeto do Google Cloud . Saiba como confirmar se a cobrança está ativada para seu projeto.
- Ative a proteção de dados sensíveis. Ativar a proteção de dados sensíveis
- Selecione um conjunto de dados do BigQuery para a análise. A Proteção de dados confidenciais calcula a métrica k-anonimato verificando uma tabela do BigQuery.
- Determine um identificador (se aplicável) e pelo menos um semi-identificador no conjunto de dados. Para mais informações, consulte Termos e técnicas de análise de risco.
Calcular o k-anonimato
A Proteção de Dados Sensíveis realiza a análise de risco sempre que um job de análise de risco é executado. É preciso criar o job primeiro, usando o console doGoogle Cloud , enviando uma solicitação da API DLP ou usando uma biblioteca de cliente da proteção de dados sensíveis.
Console
No console Google Cloud , acesse a página Criar análise de risco.
Na seção Escolher dados de entrada, especifique a tabela do BigQuery a ser verificada inserindo o ID do projeto que contém a tabela, o ID do conjunto de dados e o nome da tabela.
Em Métrica de privacidade a calcular, selecione k-anonimato.
Na seção ID do job, é possível atribuir um identificador personalizado ao job e selecionar um local de recursos em que a Proteção de dados sensíveis vai processar seus dados. Quando terminar, clique em Continuar.
Na seção Definir campos, especifique identificadores e semi-identificadores para o job de risco k-anonimato. A Proteção de dados sensíveis acessa os metadados da tabela do BigQuery especificada na etapa anterior e tenta preencher a lista de campos.
- Marque a caixa de seleção apropriada para especificar um campo como identificador (ID) ou semi-identificador (QI). É preciso selecionar 0 ou 1 identificador e pelo menos um semi-identificador.
- Se a Proteção de dados sensíveis não conseguir preencher os campos, clique em Inserir nome do campo para inserir manualmente um ou mais campos e definir cada um deles como identificador ou semi-identificador. Quando terminar, clique em Continuar.
Na seção Adicionar ações, é possível adicionar ações opcionais que serão realizadas quando o job de risco for concluído. As opções disponíveis são estas:
- Salvar no BigQuery: salva os resultados da verificação de análise de risco em uma tabela do BigQuery.
Publicar no Pub/Sub: publica uma notificação em um tópico do Pub/Sub.
Notificar por e-mail: envia um e-mail com resultados. Quando terminar, clique em Criar.
O job de análise de risco de k-anonimato começará imediatamente.
C#
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
PHP
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
REST
Para executar um novo job de análise de risco para calcular o k-anonimato, envie uma
solicitação para o recurso projects.dlpJobs,
em que PROJECT_ID indica seu identificador
do projeto:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
A solicitação contém um
objeto RiskAnalysisJobConfig,
composto de:
Um objeto
PrivacyMetricÉ aqui que você especifica que está calculando o k-anonimato ao incluir um objetoKAnonymityConfig.Um objeto
BigQueryTable. Inclua todos os itens a seguir para especificar a tabela do BigQuery que será verificada:projectId: o ID do projeto que contém a tabela.datasetId: o ID do conjunto de dados da tabela.tableId: o nome da tabela.
Um conjunto de um ou mais objetos
Action, que representam ações a serem executadas, na ordem indicada, na conclusão do job. Cada objetoActionpode conter uma das seguintes ações:- Objeto
SaveFindings: salva os resultados da verificação de análise de risco em uma tabela do BigQuery. Objeto
PublishToPubSub: publica uma notificação em um tópico do Cloud Pub/Sub.Objeto
JobNotificationEmails: envia um e-mail com os resultados.
No objeto
KAnonymityConfig, especifique o seguinte:quasiIds[]: um ou mais semi-identificadores (objetosFieldId) a serem verificados e usados para calcular o k-anonimato. Quando você especifica vários semi-identificadores, eles são considerados uma única chave composta. Não há suporte para estruturas e tipos de dados repetidos. Entretanto, os campos aninhados serão permitidos, desde que não sejam estruturas nem estejam aninhados em um campo repetido.entityId: valor do identificador opcional que, quando definido, indica que todas as linhas correspondentes a cadaentityIddistinto devem ser agrupadas para o cálculo de k-anonimato. Normalmente, umentityIdé uma coluna que representa um usuário único, como um código de cliente ou um código de usuário. Quando umentityIdaparecer em várias linhas com valores de semi-identificadores diferentes, essas linhas serão mescladas para formar um multiconjunto que será usado como semi-identificadores para essa entidade. Para mais informações sobre códigos de entidade, consulte o tópico conceitual Códigos de entidade e cálculo de k-anonimato na análise de risco.
- Objeto
Assim que você envia uma solicitação para a API DLP, ela inicia o job de análise de risco.
Listar jobs de análise de risco concluídos
É possível visualizar uma lista dos jobs de análise de risco que foram executados no projeto atual.
Console
Para listar os jobs de análise de risco em execução e anteriores no console doGoogle Cloud , faça o seguinte:
No console do Google Cloud , abra a Proteção de dados sensíveis.
Clique na guia Jobs e gatilhos de jobs na parte superior da página.
Clique na guia Jobs de risco.
A lista de vagas de risco é exibida.
Protocolo
Para listar jobs em execução e executados anteriormente, envie uma solicitação GET
ao recurso
projects.dlpJobs.
A adição de um filtro de tipo de job (?type=RISK_ANALYSIS_JOB) restringe a
resposta apenas aos jobs de análise de risco.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
A resposta que você recebe contém uma representação JSON de todos os jobs de análise de risco atuais e anteriores.
Visualizar resultados do job de k-anonimato
A Proteção de Dados Sensíveis no console Google Cloud apresenta visualizações integradas para jobs de k-anonimato concluídos. Depois de seguir as instruções da seção anterior, na lista de jobs de análise de risco, selecione o job com os resultados que você quer ver. Supondo que o job foi executado com sucesso, a parte superior da página Detalhes da análise de risco terá esta aparência:
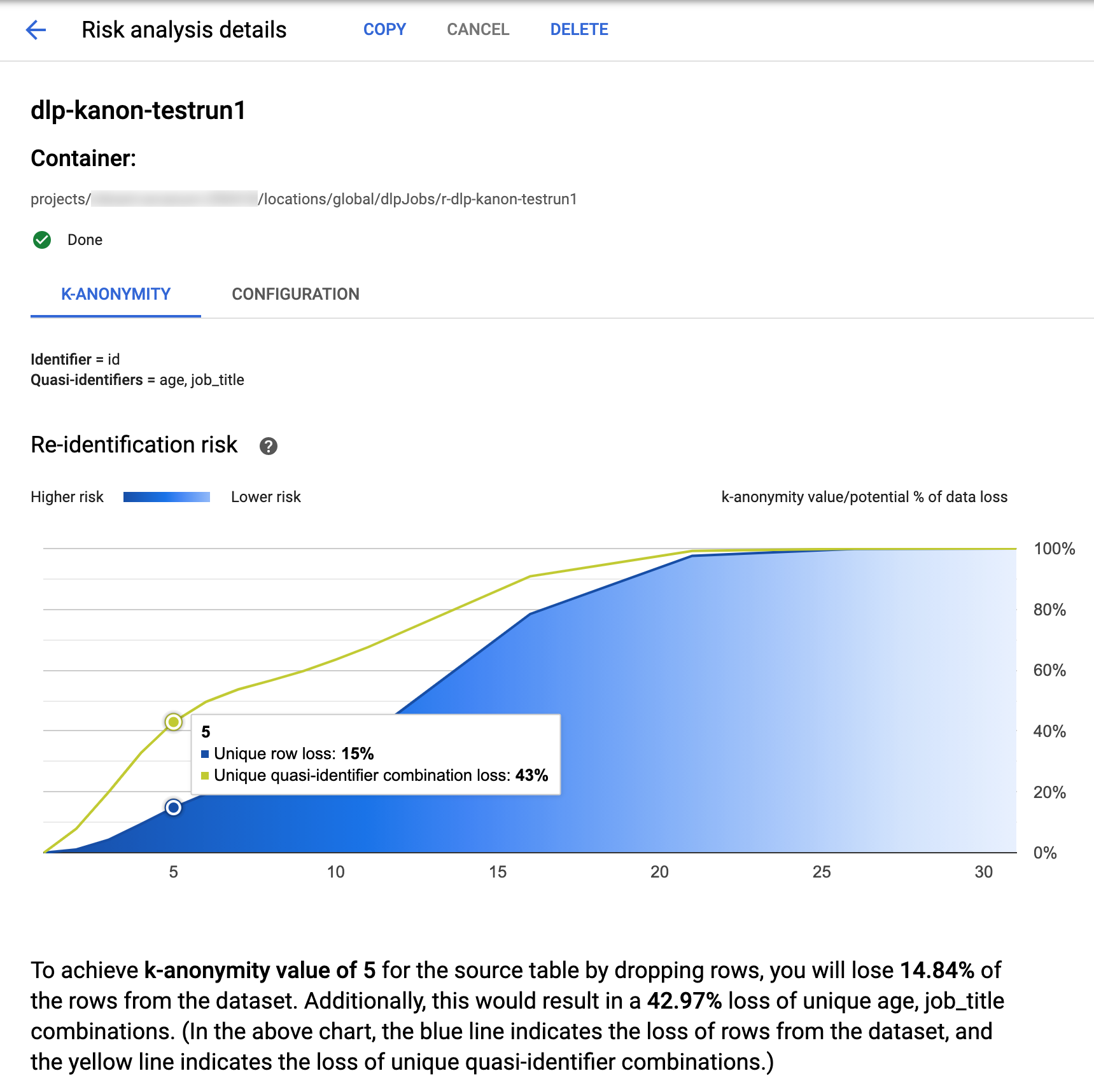
Na parte superior da página, há informações sobre o job de risco do k-anonimato, incluindo o código da tarefa e, em Contêiner, o local do recurso.
Para visualizar os resultados do cálculo de k-anonimato, clique na guia K-anonimato. Para visualizar a configuração do job de análise de risco, clique na guia Configuração.
A guia K-anonimato lista primeiro o código da entidade (se houver) e os semi-identificadores usados para calcular o k-anonimato.
Gráfico de risco
O gráfico de riso de reidentificação traça, no eixo y, a possível porcentagem de perda de dados em linhas únicas e combinações únicas de semi-identificadores para atingir, no eixo x, um valor de k-anonimato. A cor do gráfico também indica um potencial de risco. Os tons mais escuros de azul indicam riscos mais altos, enquanto tons mais claros indicam menos risco.
Os valores de k-anonimato mais altos indicam menos risco de reidentificação. No entanto, para ter valores de k-anonimato maiores, será necessário remover porcentagens maiores do total de linhas e de combinações de semi-identificadores exclusivos, o que pode diminuir a utilidade dos dados. Para ver um possível valor percentual específico de um determinado valor de k-anonimato, passe o cursor sobre o gráfico. Conforme mostrado na captura de tela, uma dica aparece no gráfico.
Para visualizar mais detalhes sobre um valor de k-anonimato específico, clique no ponto de dados correspondente. Uma explicação detalhada é exibida abaixo do gráfico, e uma tabela de dados de amostra é exibida mais abaixo da página.
Tabela de dados de amostra de risco
O segundo componente para a página de resultados do job de risco é a tabela de dados de amostra. Ele exibe combinações de semi-identificador para um determinado valor de k-anonimato.
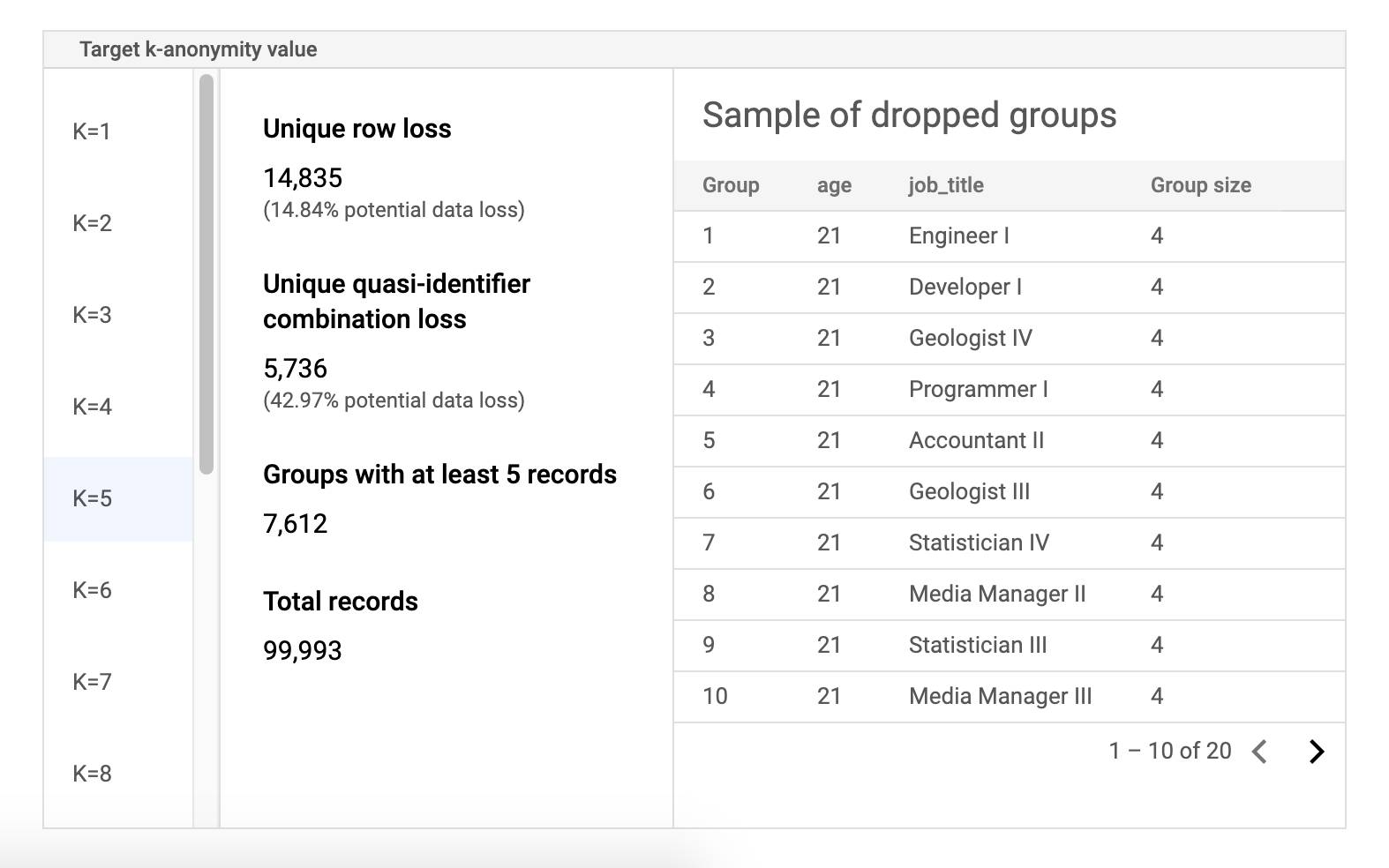
A primeira coluna da tabela lista os valores de k-anonimato. Clique em um valor de k-anonimato para visualizar dados de amostra correspondentes que precisariam ser descartados para atingir esse valor.
A segunda coluna exibe a respectiva perda de dados em potencial de linhas exclusivas e combinações de semi-identificadores, assim como o número de grupos com pelo menos k registros e o número total de registros.
A última coluna exibe uma amostra de grupos que compartilham uma combinação de semi-identificadores, junto com o número de registros atuais para essa combinação.
Recuperar detalhes do job usando REST
Para recuperar os resultados dok-anonimato usando o API
REST, envie a seguinte solicitação GET
para o
projects.dlpJobs. Substitua PROJECT_ID pelo ID do projeto e
JOB_ID pelo identificador do job em que você quer receber os resultados.
O código da tarefa foi retornado quando você iniciou o job e também pode ser recuperado ao listar todos os jobs.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
A solicitação retorna um objeto JSON que contém uma instância do job. Os resultados
da análise estão dentro da chave "riskDetails", em um
objeto
AnalyzeDataSourceRiskDetails. Para mais informações, consulte a referência da API do
recurso
DlpJob.
Exemplo de código: calcular k-anonimato com um ID de entidade
Este exemplo cria um job de análise de risco que calcula o k-anonimato com um ID de entidade.
Para mais informações sobre códigos de entidade, consulte Códigos de entidade e cálculo de k-anonimato.
C#
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
PHP
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca de cliente da Proteção de dados sensíveis, consulte Bibliotecas de cliente da Proteção de dados sensíveis.
Para autenticar na Proteção de dados sensíveis, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
A seguir
- Saiba como calcular o valor de l-diversidade para um conjunto de dados.
- Saiba como calcular o valor de k-mapa para um conjunto de dados.
- Aprenda a calcular o valor de δ-presença para um conjunto de dados.