A anonimização K é uma propriedade de um conjunto de dados que indica a possibilidade de reidentificação dos respetivos registos. Um conjunto de dados é k-anónimo se os quase identificadores de cada pessoa no conjunto de dados forem idênticos a, pelo menos, k – 1 outras pessoas também no conjunto de dados.
Pode calcular o valor de k-anonimato com base numa ou mais colunas, ou campos, de um conjunto de dados. Este tópico demonstra como calcular os valores de anonimato k para um conjunto de dados usando a proteção de dados confidenciais. Para mais informações sobre a anonimização k ou a análise de risco em geral, consulte o tópico conceito de análise de risco antes de continuar.
Antes de começar
Antes de continuar, certifique-se de que fez o seguinte:
- Inicie sessão na sua Conta Google.
- Na Google Cloud consola, na página do seletor de projetos, selecione ou crie um Google Cloud projeto. Aceda ao seletor de projetos
- Certifique-se de que a faturação está ativada para o seu Google Cloud projeto. Saiba como confirmar se a faturação está ativada para o seu projeto.
- Ative a proteção de dados confidenciais. Ative a proteção de dados confidenciais
- Selecione um conjunto de dados do BigQuery para analisar. A proteção de dados confidenciais calcula a métrica de anonimato k analisando uma tabela do BigQuery.
- Determinar um identificador (se aplicável) e, pelo menos, um quase identificador no conjunto de dados. Para mais informações, consulte os Termos e técnicas de análise de riscos.
Calcule o k-anonimato
A proteção de dados confidenciais realiza uma análise de risco sempre que uma tarefa de análise de risco é executada. Primeiro, tem de criar a tarefa através daGoogle Cloud consola, enviando um pedido da API DLP ou usando uma biblioteca cliente da Proteção de dados confidenciais.
Consola
Na Google Cloud consola, aceda à página Criar análise de risco.
Na secção Escolher dados de entrada, especifique a tabela do BigQuery a analisar introduzindo o ID do projeto do projeto que contém a tabela, o ID do conjunto de dados da tabela e o nome da tabela.
Em Métrica de privacidade a calcular, selecione k-anonimato.
Na secção ID da tarefa, pode, opcionalmente, atribuir um identificador personalizado à tarefa e selecionar uma localização de recursos na qual a Proteção de dados confidenciais processará os seus dados. Quando terminar, clique em Continuar.
Na secção Definir campos, especifica identificadores e quase-identificadores para a tarefa de risco de anonimato k. A Proteção de dados confidenciais acede aos metadados da tabela do BigQuery que especificou no passo anterior e tenta preencher a lista de campos.
- Selecione a caixa de verificação adequada para especificar um campo como um identificador (ID) ou um quase identificador (QI). Tem de selecionar 0 ou 1 identificador e, pelo menos, 1 quase identificador.
- Se a proteção de dados confidenciais não conseguir preencher os campos, clique em Introduzir nome do campo para introduzir manualmente um ou mais campos e definir cada um como identificador ou quase identificador. Quando terminar, clique em Continuar.
Na secção Adicionar ações, pode adicionar ações opcionais a realizar quando a tarefa de risco estiver concluída. As opções disponíveis são:
- Guardar no BigQuery: guarda os resultados da análise de risco numa tabela do BigQuery.
Publicar no Pub/Sub: publica uma notificação num tópico do Pub/Sub.
Notificar por email: envia-lhe um email com os resultados. Quando terminar, clique em Criar.
A tarefa de análise de risco de k-anonimato começa imediatamente.
C#
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
PHP
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
REST
Para executar uma nova tarefa de análise de risco para calcular a anonimização k, envie um pedido para o recurso
projects.dlpJobs, onde PROJECT_ID indica o identificador do seu projeto:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
O pedido contém um objeto
RiskAnalysisJobConfig
composto pelo seguinte:
Um
PrivacyMetricobjeto. É aqui que especifica que está a calcular a anonimização k incluindo um objetoKAnonymityConfig.Um objeto
BigQueryTable. Especifique a tabela do BigQuery a analisar incluindo todos os seguintes elementos:projectId: o ID do projeto que contém a tabela.datasetId: o ID do conjunto de dados da tabela.tableId: o nome da tabela.
Um conjunto de um ou mais objetos
Actionque representam ações a executar, na ordem indicada, após a conclusão da tarefa. Cada objetoActionpode conter uma das seguintes ações:SaveFindingsobject: guarda os resultados da análise de risco numa tabela do BigQuery.PublishToPubSubobject: Publica uma notificação num tópico do Pub/Sub.JobNotificationEmailsobject: envia-lhe um email com os resultados.
No objeto
KAnonymityConfig, especifica o seguinte:quasiIds[]: um ou mais quase identificadores (objetosFieldId) a analisar e usar para calcular o anonimato k. Quando especifica vários quase identificadores, estes são considerados uma única chave composta. Os tipos de dados estruturados e repetidos não são suportados, mas os campos aninhados são suportados desde que não sejam eles próprios estruturados nem estejam aninhados num campo repetido.entityId: valor do identificador opcional que, quando definido, indica que todas as linhas correspondentes a cadaentityIddistinto devem ser agrupadas para o cálculo da anonimização k. Normalmente, umentityIdé uma coluna que representa um utilizador único, como um ID do cliente ou um ID do utilizador. Quando umentityIdaparece em várias linhas com valores de quase identificadores diferentes, estas linhas são unidas para formar um conjunto múltiplo que é usado como os quase identificadores para essa entidade. Para mais informações sobre IDs de entidades, consulte IDs de entidades e computação k-anonimato no tópico conceptual Análise de risco.
Assim que envia um pedido para a API DLP, esta inicia a tarefa de análise de risco.
Apresente as tarefas de análise de risco concluídas
Pode ver uma lista das tarefas de análise de risco que foram executadas no projeto atual.
Consola
Para listar tarefas de análise de risco em execução e executadas anteriormente na Google Cloud consola, faça o seguinte:
Na Google Cloud consola, abra a Proteção de dados confidenciais.
Clique no separador Tarefas e acionadores de tarefas na parte superior da página.
Clique no separador Tarefas de risco.
É apresentada a oferta de emprego de risco.
Protocolo
Para apresentar uma lista de tarefas de análise de risco em execução e executadas anteriormente, envie um pedido GET para o recurso projects.dlpJobs. Adicionar um filtro de tipo de tarefa (?type=RISK_ANALYSIS_JOB) restringe a resposta apenas a tarefas de análise de risco.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
A resposta que recebe contém uma representação JSON de todas as tarefas de análise de risco atuais e anteriores.
Veja os resultados de tarefas de k-anonimato
A proteção de dados confidenciais na Google Cloud consola inclui visualizações integradas para trabalhos de k-anonimato concluídos. Depois de seguir as instruções na secção anterior, na ficha da tarefa de análise de risco, selecione a tarefa para a qual quer ver os resultados. Supondo que a tarefa foi executada com êxito, a parte superior da página Detalhes da análise de risco tem o seguinte aspeto:
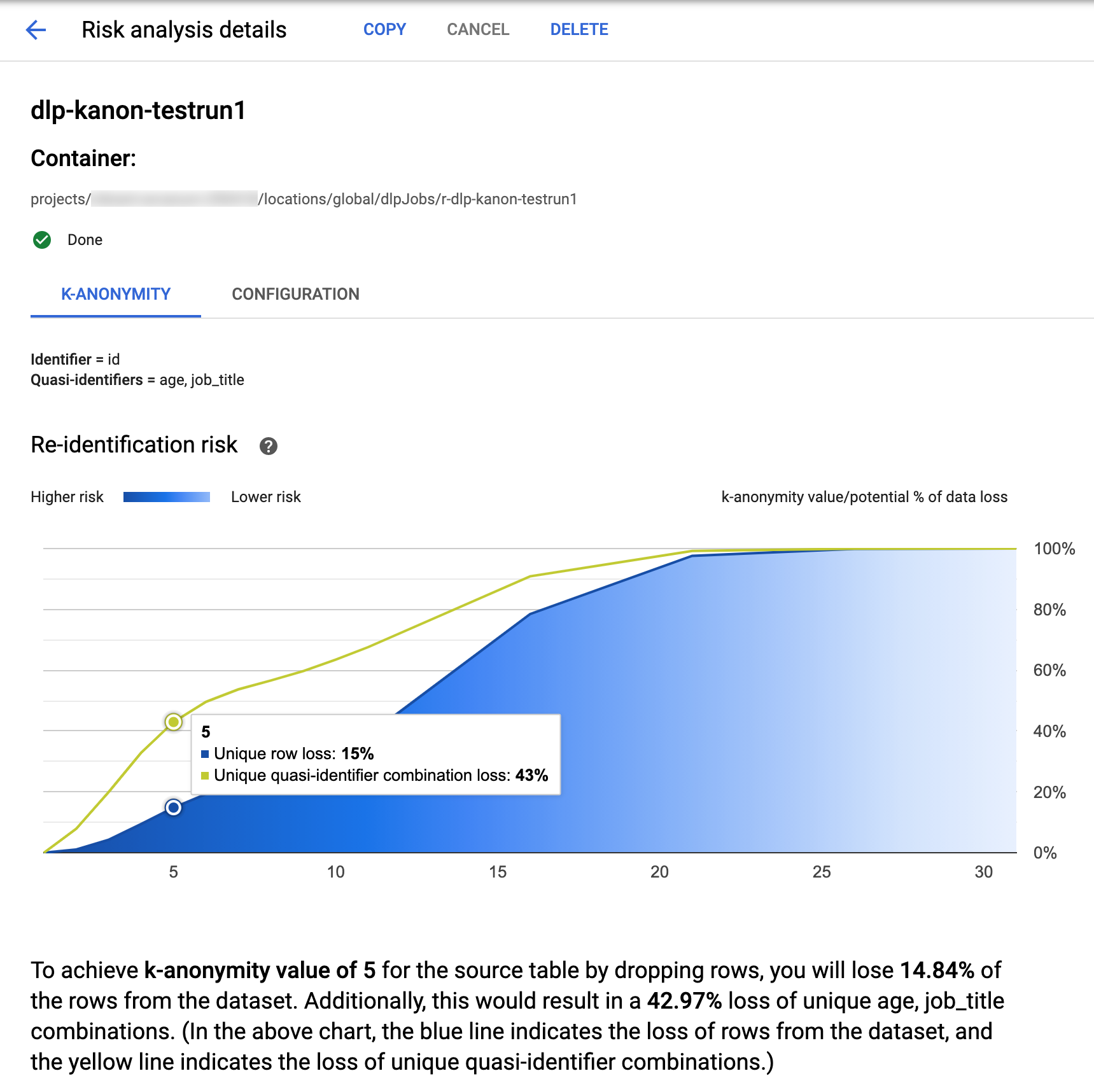
Na parte superior da página, encontram-se informações sobre a tarefa de risco de anonimato k, incluindo o respetivo ID da tarefa e, em Recipiente, a respetiva localização do recurso.
Para ver os resultados do cálculo do k-anonimato, clique no separador K-anonimato. Para ver a configuração da tarefa de análise de risco, clique no separador Configuração.
O separador K-anonimato apresenta primeiro o ID da entidade (se existir) e os identificadores quase únicos usados para calcular o k-anonimato.
Gráfico de risco
O gráfico Risco de reidentificação representa, no eixo y, a percentagem potencial de perda de dados para linhas únicas e combinações únicas de quase identificadores para alcançar, no eixo x, um valor de anonimato k. A cor do gráfico também indica o potencial de risco. As tonalidades mais escuras de azul indicam um risco mais elevado, enquanto as tonalidades mais claras indicam um risco menor.
Os valores de anonimato k mais elevados indicam um menor risco de reidentificação. No entanto, para alcançar valores de anonimato k mais elevados, teria de remover percentagens mais elevadas do total de linhas e combinações de quase identificadores únicos mais elevadas, o que pode diminuir a utilidade dos dados. Para ver um valor de perda percentual potencial específico para um determinado valor de anonimato k, passe o cursor do rato sobre o gráfico. Conforme mostrado na captura de ecrã, é apresentada uma sugestão no gráfico.
Para ver mais detalhes sobre um valor de k-anonimato específico, clique no ponto de dados correspondente. É apresentada uma explicação detalhada abaixo do gráfico e uma tabela de dados de exemplo mais abaixo na página.
Tabela de dados de amostra de risco
O segundo componente da página de resultados da tarefa de risco é a tabela de dados de exemplo. Apresenta combinações de quase identificadores para um determinado valor de anonimato k.
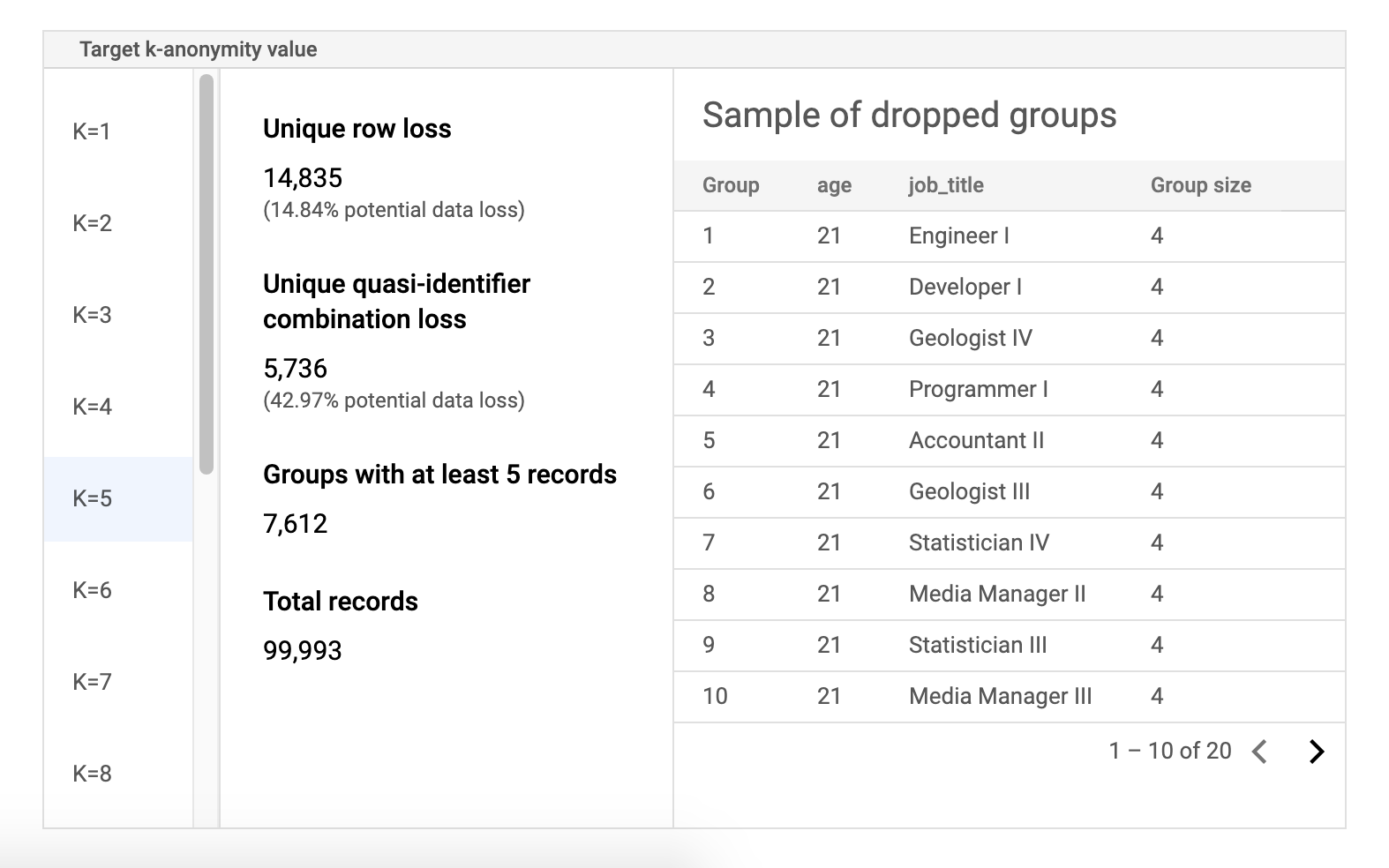
A primeira coluna da tabela apresenta os valores de anonimato k. Clique num valor de anonimato de k para ver os dados de amostra correspondentes que teriam de ser ignorados para alcançar esse valor.
A segunda coluna apresenta a potencial perda de dados respetiva de linhas únicas e combinações de quase identificadores, bem como o número de grupos com, pelo menos, k registos e o número total de registos.
A última coluna apresenta uma amostra de grupos que partilham uma combinação de quase identificadores, juntamente com o número de registos existentes para essa combinação.
Obtenha detalhes de tarefas através de REST
Para obter os resultados da tarefa de análise de risco de anonimato de k através da API REST, envie o seguinte pedido GET para o recurso projects.dlpJobs. Substitua PROJECT_ID pelo ID do projeto e JOB_ID pelo identificador da tarefa para a qual quer obter resultados.
O ID da tarefa foi devolvido quando iniciou a tarefa e também pode ser obtido através da
listagem de todas as tarefas.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
O pedido devolve um objeto JSON que contém uma instância da tarefa. Os resultados
da análise encontram-se na chave "riskDetails", num
objeto AnalyzeDataSourceRiskDetails. Para mais informações, consulte a referência da API para o recurso
DlpJob.
Exemplo de código: calcular a k-anonimidade com um ID de entidade
Este exemplo cria uma tarefa de análise de risco que calcula o k-anonimato com um ID de entidade.
Para mais informações acerca dos IDs de entidades, consulte IDs de entidades e computação de k-anonimato.
C#
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
PHP
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca cliente para a Proteção de dados confidenciais, consulte o artigo Bibliotecas cliente da Proteção de dados confidenciais.
Para se autenticar na Proteção de dados confidenciais, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
O que se segue?
- Saiba como calcular o valor de l-diversidade para um conjunto de dados.
- Saiba como calcular o valor do mapa k para um conjunto de dados.
- Saiba como calcular o valor de δ-presença para um conjunto de dados.