K-anonimidad es una propiedad de un conjunto de datos que indica la posibilidad de reidentificar sus registros. Un conjunto de datos es k-anónimo si los cuasidentificadores de cada persona del conjunto de datos son idénticos a los de al menos k - 1 personas del mismo conjunto.
Puedes calcular el valor de k-anonimato en función de una o varias columnas o campos de un conjunto de datos. En este tema se muestra cómo calcular los valores de k-anonimato de un conjunto de datos con Protección de Datos Sensibles. Para obtener más información sobre la k-anonimato o el análisis de riesgos en general, consulta el tema sobre el concepto de análisis de riesgos antes de continuar.
Antes de empezar
Antes de continuar, asegúrate de que has hecho lo siguiente:
- Inicia sesión en tu cuenta de Google.
- En la Google Cloud consola Google Cloud , en la página del selector de proyectos, selecciona o crea un proyecto. Ir al selector de proyectos
- Comprueba que la facturación esté habilitada en tu Google Cloud proyecto. Consulta cómo confirmar que la facturación está habilitada en tu proyecto.
- Habilita Protección de Datos Sensibles. Habilitar Protección de Datos Sensibles
- Selecciona un conjunto de datos de BigQuery para analizarlo. Protección de Datos Sensibles calcula la métrica de k-anonimato analizando una tabla de BigQuery.
- Determina un identificador (si procede) y al menos un cuasidentificador en el conjunto de datos. Para obtener más información, consulta Términos y técnicas de análisis de riesgos.
Calcular k-anonymity
Protección de Datos Sensibles realiza un análisis de riesgos cada vez que se ejecuta un trabajo de análisis de riesgos. Primero debes crear el trabajo. Para ello, puedes usar laGoogle Cloud consola, enviar una solicitud a la API DLP o usar una biblioteca de cliente de Protección de Datos Sensibles.
Consola
En la Google Cloud consola, ve a la página Crear análisis de riesgo.
En la sección Elegir datos de entrada, especifica la tabla de BigQuery que quieres analizar. Para ello, introduce el ID del proyecto que contiene la tabla, el ID del conjunto de datos de la tabla y el nombre de la tabla.
En Métrica de privacidad que se va a calcular, selecciona k-anonimato.
En la sección ID de tarea, puedes asignar un identificador personalizado a la tarea y seleccionar una ubicación de recursos en la que Protección de Datos Sensibles tratará tus datos. Cuando hayas terminado, haz clic en Continuar.
En la sección Define fields (Definir campos), especifica identificadores y cuasi-identificadores para el trabajo de riesgo de k-anonimato. La protección de datos sensibles accede a los metadatos de la tabla de BigQuery que has especificado en el paso anterior e intenta rellenar la lista de campos.
- Selecciona la casilla correspondiente para especificar si un campo es un identificador (ID) o un cuasi-identificador (QI). Debes seleccionar 0 o 1 identificador y al menos 1 cuasi-identificador.
- Si Protección de Datos Sensibles no puede rellenar los campos, haz clic en Introducir nombre de campo para introducir manualmente uno o varios campos y definir cada uno como identificador o cuasidentificador. Cuando hayas terminado, haz clic en Continuar.
En la sección Añadir acciones, puede añadir acciones opcionales que se llevarán a cabo cuando se complete el trabajo de riesgo. Estas son las opciones disponibles:
- Guardar en BigQuery: guarda los resultados del análisis de riesgos en una tabla de BigQuery.
Publicar en Pub/Sub: publica una notificación en un tema de Pub/Sub.
Notificar por correo electrónico: te envía un correo con los resultados. Cuando hayas terminado, haz clic en Crear.
La tarea de análisis de riesgo de k-anonimato se inicia inmediatamente.
C#
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Go
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Java
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
PHP
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
REST
Para ejecutar un nuevo trabajo de análisis de riesgos para calcular el modelo k-anonymity, envía una solicitud al recurso projects.dlpJobs, donde PROJECT_ID indica el identificador de tu proyecto:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
La solicitud contiene un objeto RiskAnalysisJobConfig, que se compone de lo siguiente:
Un objeto
PrivacyMetric. Aquí es donde se especifica que se va a calcular la k-anonimidad incluyendo un objetoKAnonymityConfig.Un objeto
BigQueryTable. Especifica la tabla de BigQuery que quieres analizar incluyendo todos los elementos siguientes:projectId: el ID del proyecto que contiene la tabla.datasetId: ID del conjunto de datos de la tabla.tableId: el nombre de la tabla.
Conjunto de uno o varios objetos
Actionque representan las acciones que se deben ejecutar, en el orden indicado, cuando se complete la tarea. Cada objetoActionpuede contener una de las siguientes acciones:SaveFindingsobject: guarda los resultados del análisis de riesgos en una tabla de BigQuery.PublishToPubSubobjeto: Publica una notificación en un tema de Pub/Sub.JobNotificationEmailsObjeto: te envía un correo con los resultados.
En el objeto
KAnonymityConfigespecifica lo siguiente:quasiIds[]: uno o varios cuasi-identificadores (objetosFieldId) que se van a analizar y usar para calcular el anonimato k. Cuando especifica varios cuasi-identificadores, se consideran una sola clave compuesta. No se admiten structs ni tipos de datos repetidos, pero sí campos anidados, siempre que no sean structs ni estén anidados en un campo repetido.entityId: valor de identificador opcional que, cuando se define, indica que todas las filas correspondientes a cadaentityIddistinto deben agruparse para calcular la propiedad k-anonymity. Normalmente, unentityIdserá una columna que represente a un usuario único, como un ID de cliente o un ID de usuario. Cuando unentityIdaparece en varias filas con diferentes valores de cuasi-identificador, estas filas se combinarán para formar un multiconjunto que se usará como cuasi-identificador de esa entidad. Para obtener más información sobre los IDs de entidad, consulta IDs de entidad y cálculo de k-anonimato en el tema conceptual Análisis de riesgos.
En cuanto envías una solicitud a la API DLP, se inicia la tarea de análisis de riesgos.
Lista de tareas de análisis de riesgos completadas
Puedes ver una lista de los trabajos de análisis de riesgos que se han ejecutado en el proyecto actual.
Consola
Para enumerar los trabajos de análisis de riesgos que se están ejecutando y los que se han ejecutado anteriormente en la consola deGoogle Cloud , haga lo siguiente:
En la consola de Google Cloud , abre Protección de Datos Sensibles.
En la parte superior de la página, haga clic en la pestaña Trabajos y activadores de trabajos.
Haz clic en la pestaña Trabajos de riesgo.
Aparecerá la lista de tareas de riesgo.
Protocolo
Para ver una lista de las tareas de análisis de riesgos en curso y de las que se han ejecutado anteriormente, envía una solicitud GET al recurso projects.dlpJobs. Si añade un filtro de tipo de trabajo (?type=RISK_ANALYSIS_JOB), la respuesta se limitará a los trabajos de análisis de riesgos.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
La respuesta que recibes contiene una representación JSON de todos los trabajos de análisis de riesgos actuales y anteriores.
Ver los resultados de un trabajo de k-anonymity
Protección de Datos Sensibles en la consola ofrece visualizaciones integradas de las tareas de k-anonimato completadas. Google Cloud Después de seguir las instrucciones de la sección anterior, en la lista de trabajos de análisis de riesgos, seleccione el trabajo del que quiera ver los resultados. Si la tarea se ha ejecutado correctamente, la parte superior de la página Detalles del análisis de riesgo tendrá este aspecto:
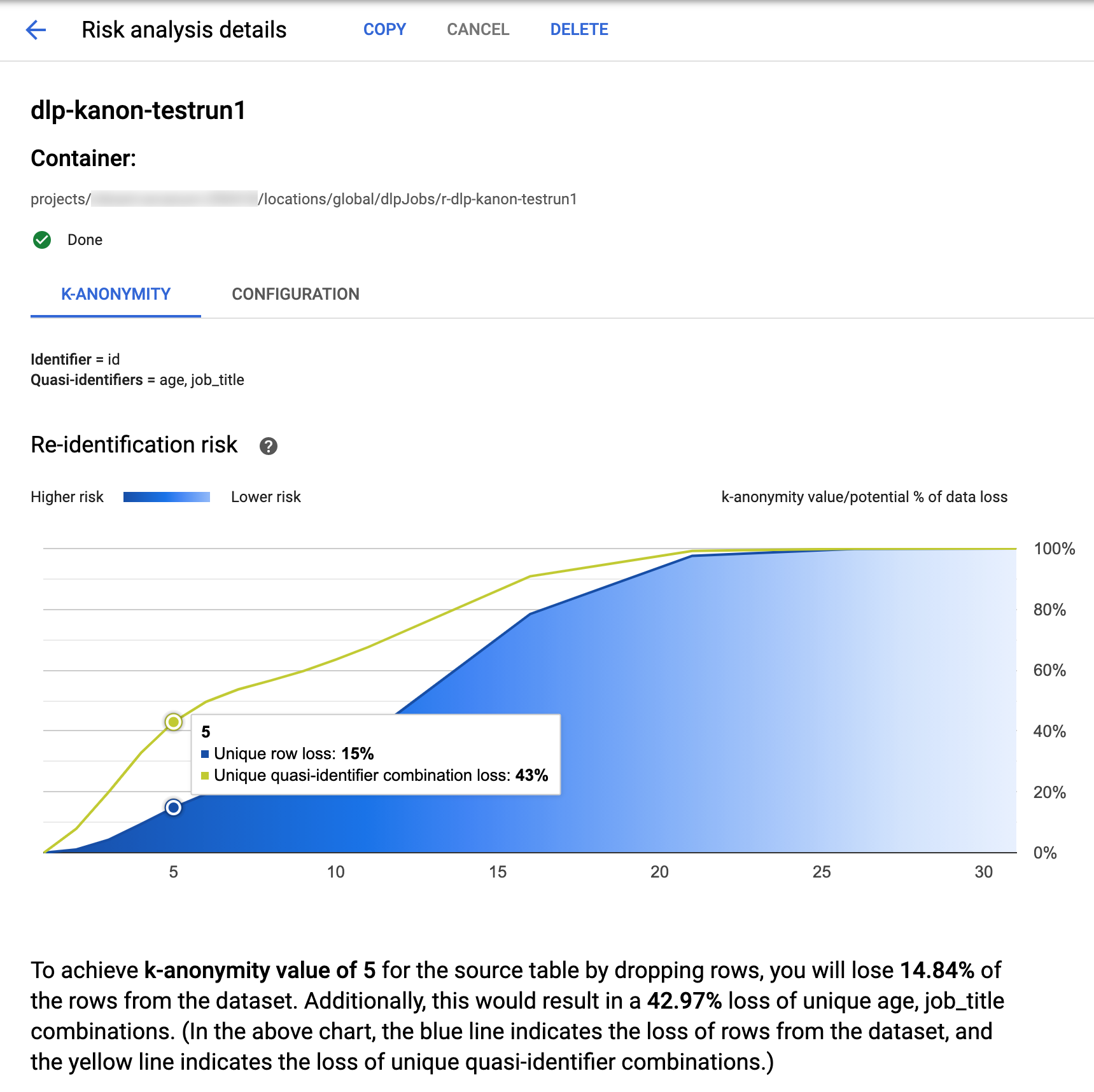
En la parte superior de la página se muestra información sobre el trabajo de riesgo de k-anonimato, incluido su ID y, en Contenedor, la ubicación del recurso.
Para ver los resultados del cálculo de k-anonimidad, haga clic en la pestaña K-anonimidad. Para ver la configuración del trabajo de análisis de riesgos, haga clic en la pestaña Configuración.
En la pestaña K-anonimidad se muestra primero el ID de entidad (si lo hay) y los cuasi-identificadores que se han usado para calcular la k-anonimidad.
Gráfico de riesgos
El gráfico Riesgo de reidentificación representa, en el eje y, el porcentaje potencial de pérdida de datos tanto de las filas únicas como de las combinaciones únicas de cuasi-identificadores para alcanzar, en el eje x, un valor de k-anonymity. El color del gráfico también indica el potencial de riesgo. Los tonos de azul más oscuros indican un mayor riesgo, mientras que los más claros indican un menor riesgo.
Cuanto más altos sean los valores de k-anonimidad, menor será el riesgo de reidentificación. Sin embargo, para conseguir valores de k-anonimato más altos, tendrías que eliminar porcentajes más altos del total de filas y combinaciones únicas de cuasi-identificadores, lo que podría reducir la utilidad de los datos. Para ver un valor de pérdida potencial específico de un valor de k-anonimato determinado, coloque el cursor sobre el gráfico. Como se muestra en la captura de pantalla, aparece una descripción emergente en el gráfico.
Para ver más detalles sobre un valor de k-anonymity específico, haz clic en el punto de datos correspondiente. Debajo del gráfico se muestra una explicación detallada y, más abajo en la página, aparece una tabla de datos de ejemplo.
Tabla de datos de ejemplo de riesgo
El segundo componente de la página de resultados de la tarea con riesgo es la tabla de datos de ejemplo. Muestra las combinaciones de cuasidentificadores de un valor de k-anonimato objetivo.
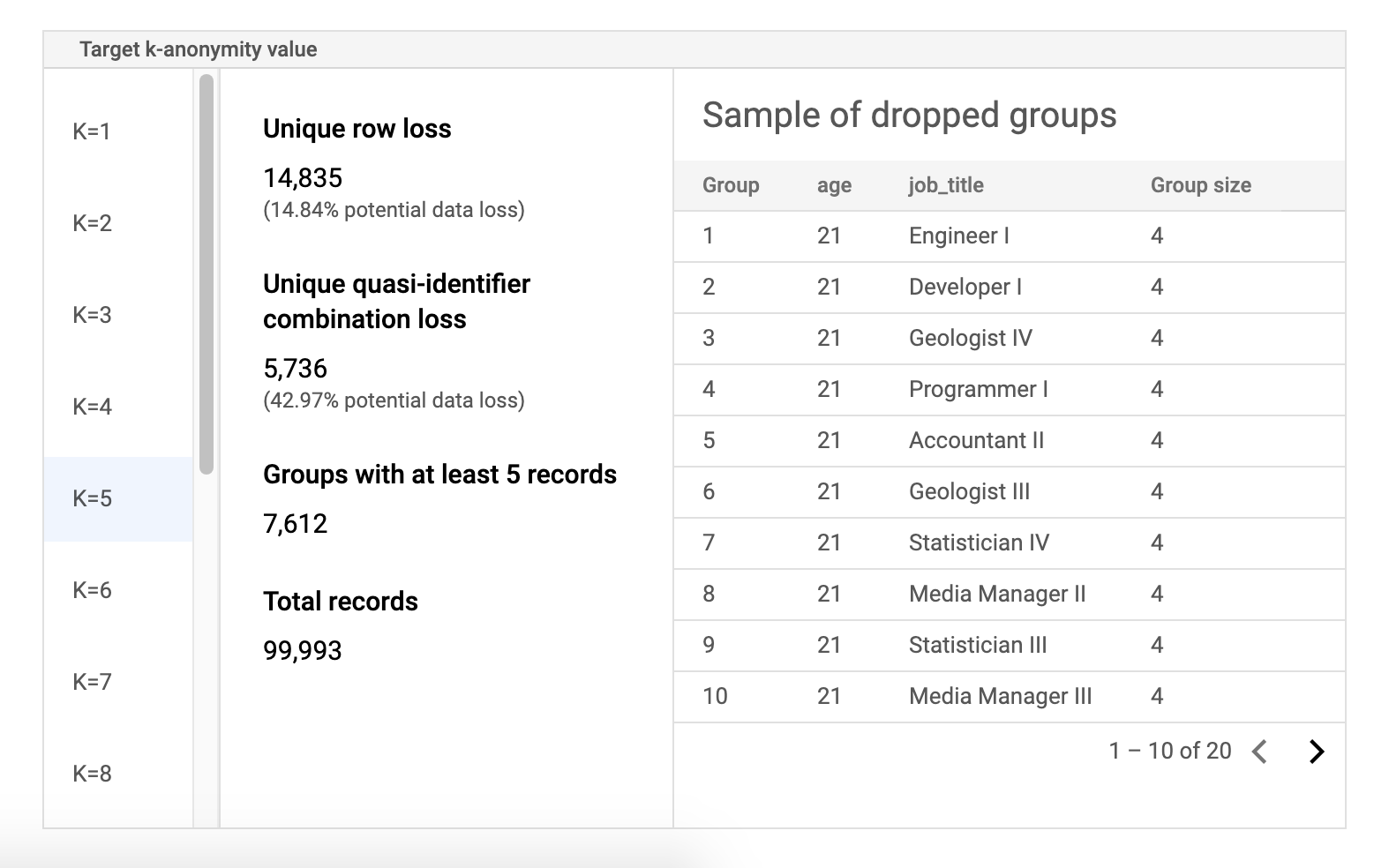
La primera columna de la tabla muestra los valores de k-anonimato. Haga clic en un valor de k-anonimato para ver los datos de muestra correspondientes que se tendrían que eliminar para alcanzar ese valor.
La segunda columna muestra la posible pérdida de datos de las filas únicas y las combinaciones de cuasi-identificadores, así como el número de grupos con al menos k registros y el número total de registros.
En la última columna se muestra una muestra de los grupos que comparten una combinación de cuasi-identificador, junto con el número de registros que existen para esa combinación.
Obtener los detalles de un trabajo mediante REST
Para obtener los resultados de la tarea de análisis de riesgos de k-anonimato mediante la API REST, envía la siguiente solicitud GET al recurso projects.dlpJobs. Sustituye PROJECT_ID por el ID de tu proyecto y JOB_ID por el identificador del trabajo del que quieras obtener resultados.
El ID de la tarea se devolvió cuando la iniciaste y también se puede obtener consultando todas las tareas.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
La solicitud devuelve un objeto JSON que contiene una instancia del trabajo. Los resultados del análisis se encuentran en la clave "riskDetails", en un objeto AnalyzeDataSourceRiskDetails. Para obtener más información, consulta la referencia de la API del recurso DlpJob.
Código de muestra: calcular k-anonymity con un ID de entidad
En este ejemplo, se crea una tarea de análisis de riesgo que calcula la k-anonimidad con un ID de entidad.
Para obtener más información sobre los IDs de entidad, consulta IDs de entidad y anonimato k.
C#
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Go
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Java
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
PHP
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para saber cómo instalar y usar la biblioteca de cliente de Protección de Datos Sensibles, consulta el artículo sobre las bibliotecas de cliente de Protección de Datos Sensibles.
Para autenticarte en Protección de Datos Sensibles, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Siguientes pasos
- Consulta cómo calcular el valor de l-diversidad de un conjunto de datos.
- Consulta cómo calcular el valor k-map de un conjunto de datos.
- Consulte cómo calcular el valor de δ-presencia de un conjunto de datos.