本页面提供了有关如何识别和补救组织中的数据风险的建议策略。
如要保护您的数据,首先需要了解您正在处理哪些数据、敏感数据位于何处,以及如何保护和使用这些数据。全面了解数据及其安全状况后,您可以采取适当的措施来保护数据,并持续监控合规性和风险。
本页面假定您熟悉发现和检查服务及其区别。
启用敏感数据发现
如需确定贵公司中存在哪些敏感数据,请在组织、文件夹或项目级层配置发现。此服务会生成包含有关数据的指标和数据洞见的数据分析文件,包括数据的敏感度级别和数据风险级别。
作为一项服务,发现功能可充当数据资产的可靠来源,并可自动报告审核报告的指标。此外,Discovery 还可以连接到其他 Google Cloud 服务(例如 Security Command Center、Google Security Operations 和 Dataplex Universal Catalog),以丰富安全运营和数据管理。
发现服务会持续运行,并在组织运营和发展过程中检测新数据。例如,如果组织中的某人创建了一个新项目并上传了大量新数据,发现服务可以自动发现、分类和报告新数据。
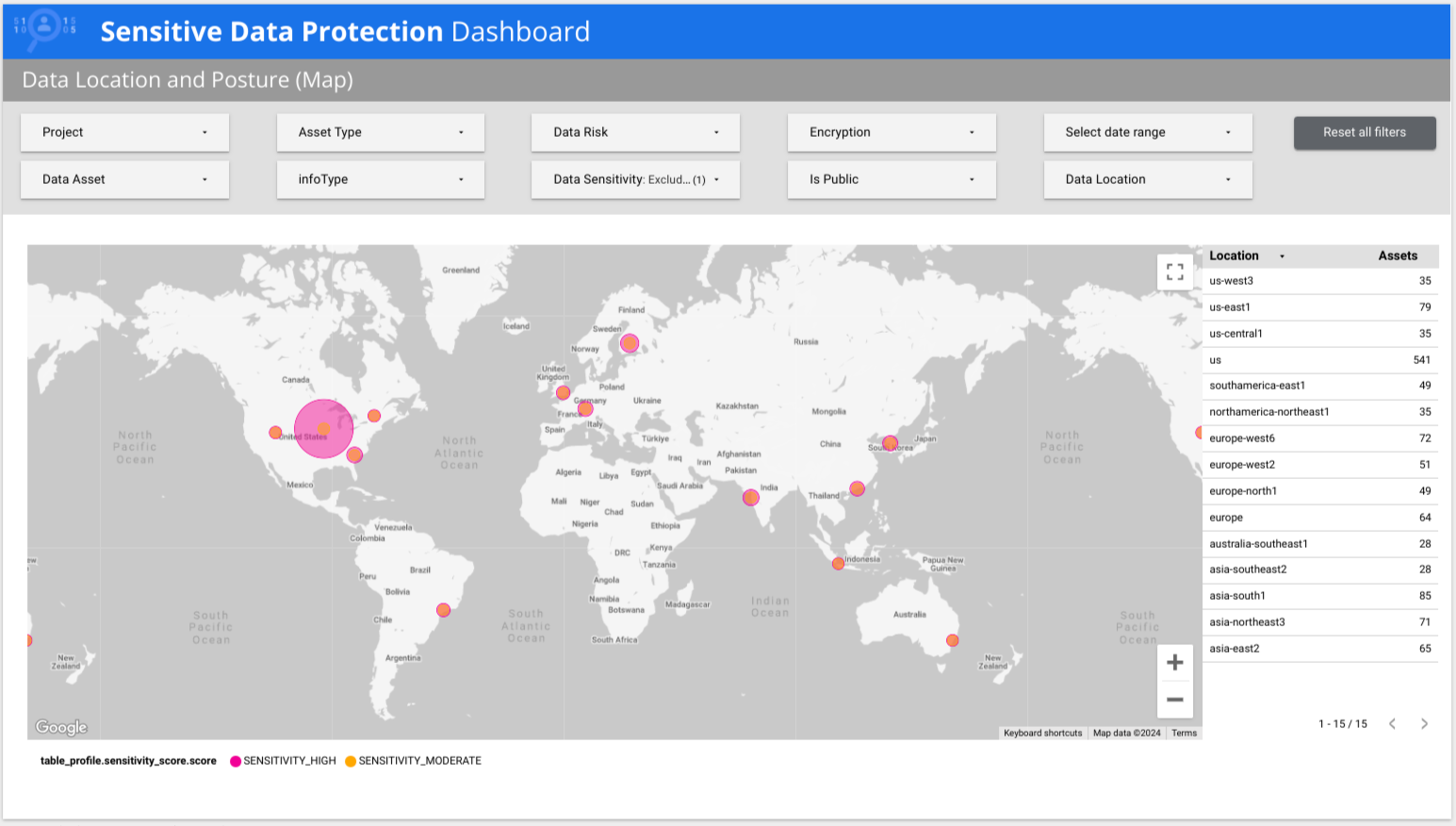
Sensitive Data Protection 提供预制的多页 Looker 报告,可让您大致了解数据,包括按风险、按 infoType 和按位置细分的数据。在以下示例中,报告显示低敏感度数据和高敏感度数据分布在全球多个国家/地区。
根据发现结果采取行动
在全面了解数据安全状况后,您可以修复发现的任何问题。一般来说,发现结果属于以下某种情形:
- 情形 1:在预期会包含敏感数据的工作负载中发现了敏感数据,并且该数据已得到妥善保护。
- 情形 2:在不应包含敏感数据或未采取适当控制措施的工作负载中发现了敏感数据。
- 场景 3:发现了敏感数据,但需要进一步调查。
场景 1:发现敏感数据,且已得到妥善保护
虽然此方案不需要采取具体行动,但您应在审核报告和安全分析工作流中包含数据配置文件,并继续监控可能导致数据面临风险的更改。
我们建议您采取以下做法:
将数据配置文件发布到用于监控安全状况和调查网络威胁的工具。数据分析有助于您确定可能使敏感数据面临风险的安全威胁或漏洞的严重程度。您可以将数据剖析自动导出到以下位置:
将数据剖析发布到 Dataplex Universal Catalog 或商品目录系统,以跟踪数据剖析指标以及任何其他合适的业务元数据。 如需了解如何自动将数据分析结果导出到 Dataplex Universal Catalog,请参阅根据数据分析结果添加 Dataplex Universal Catalog 切面。
场景 2:发现敏感数据,但未得到妥善保护
如果发现功能在未受到访问权限控制妥善保护的资源中发现了敏感数据,请考虑本部分中介绍的建议。
为数据建立正确的控制措施和数据安全状况后,请监控任何可能使数据面临风险的更改。请参阅情形 1 中的建议。
一般建议
建议您执行以下操作:
创建数据的去标识化副本,以遮盖或标记敏感列,这样数据分析师和工程师就可以继续使用您的数据,而不会泄露原始的敏感标识符(例如个人身份信息 [PII])。
对于 Cloud Storage 数据,您可以使用 Sensitive Data Protection 中的内置功能来创建去标识化副本。
如果您不需要相应数据,请考虑将其删除。
有关保护 BigQuery 数据的建议
- 使用 IAM 调整表级权限。
使用 BigQuery 政策标记设置精细的列级访问权限控制,以限制对敏感列和高风险列的访问权限。借助此功能,您可以保护这些列,同时允许访问表的其余部分。
您还可以使用政策标记来启用自动数据遮盖,以便为用户提供部分模糊处理的数据。
使用 BigQuery 的行级安全性功能,根据用户或群组是否在许可名单中,隐藏或显示某些数据行。
保护 Cloud Storage 数据的建议
场景 3:发现敏感数据,但需要进一步调查
在某些情况下,您可能会获得需要进一步调查的结果。例如,数据配置文件可能会指定某列具有较高的自由文本得分,并包含敏感数据证据。较高的自由文本得分表示数据没有可预测的结构,并且可能包含间歇性的敏感数据实例。例如,某个备注列中的某些行包含个人身份信息,如姓名、联系信息或政府签发的标识符。在这种情况下,我们建议您对表设置额外的访问权限控制,并执行方案 2 中所述的其他补救措施。此外,我们建议进行更深入、更有针对性的检查,以确定风险程度。
借助检查服务,您可以对单个资源(例如单个 BigQuery 表或 Cloud Storage 存储桶)进行全面扫描。对于检查服务未直接支持的数据源,您可以将数据导出到 Cloud Storage 存储桶或 BigQuery 表中,然后对该资源运行检查作业。例如,如果您有需要在 Cloud SQL 数据库中检查的数据,您可以将该数据导出到 Cloud Storage 中的 CSV 或 AVRO 文件,然后运行检查作业。
检查作业可查找敏感数据的各个实例,例如表格单元格内句子中间的信用卡号。这种详细程度有助于您了解非结构化列或数据对象(包括文本文件、PDF、图片和其他富文档格式)中存在的数据类型。然后,您可以按照方案 2 中介绍的任何建议来修正发现的问题。
除了方案 2 中建议的步骤之外,还应考虑采取措施来防止敏感信息进入后端数据存储区。Cloud Data Loss Prevention API 的 content 方法可以接受来自任何工作负载或应用的数据,以进行动态数据检查和遮盖。例如,您的应用可以执行以下操作:
- 接受用户提供的评论。
- 运行
content.deidentify以对该字符串中的任何敏感数据进行去标识化处理。 - 将去标识化后的字符串保存到后端存储区,而不是原始字符串。
最佳做法摘要
下表总结了本文档中建议的最佳实践:
| 挑战 | 操作 |
|---|---|
| 您想了解贵组织存储的数据类型。 | 在组织、文件夹或项目级运行发现。 |
| 您在已受保护的资源中发现了敏感数据。 | 通过运行发现作业并自动将配置文件导出到 Security Command Center、Google SecOps 和 Dataplex Universal Catalog,持续监控该资源。 |
| 您在未受保护的资源中发现了敏感数据。 | 根据数据查看者的身份隐藏或显示数据;使用 IAM、列级安全性或行级安全性。您还可以使用 Sensitive Data Protection 的去标识化工具来转换或移除敏感元素。 |
| 您发现了敏感数据,需要进一步调查以了解数据风险的程度。 | 对资源运行检查作业。您还可以使用 DLP API 的同步 content 方法来主动防止敏感数据进入后端存储空间,这些方法可以近乎实时地处理数据。 |