이 페이지에서는 조직의 데이터 위험을 식별하고 해결하기 위한 권장 전략을 제공합니다.
데이터 보호는 처리하는 데이터, 민감한 정보가 있는 위치, 데이터가 보호되고 사용되는 방식을 파악하는 것에서 시작됩니다. 데이터와 보안 상태를 포괄적으로 파악하면 데이터를 보호하고 규정 준수 및 위험을 지속적으로 모니터링하기 위한 적절한 조치를 취할 수 있습니다.
이 페이지에서는 사용자가 검색 및 검사 서비스와 그 차이점에 대해 잘 알고있다고 가정합니다.
민감한 정보 검색 사용 설정
비즈니스에서 민감한 정보가 있는 위치를 확인하려면 조직, 폴더 또는 프로젝트 수준에서 검색을 구성하세요. 이 서비스는 민감도 수준과 데이터 위험 수준을 비롯한 데이터에 관한 측정항목과 인사이트가 포함된 데이터 프로필을 생성합니다.
탐색은 서비스로서 데이터 애셋에 관한 정보 소스 역할을 하며 감사 보고서의 측정항목을 자동으로 보고할 수 있습니다. 또한 검색은 Security Command Center, Google Security Operations, Dataplex Universal Catalog과 같은 다른 Google Cloud 서비스에 연결하여 보안 운영 및 데이터 관리를 강화할 수 있습니다.
검색 서비스는 지속적으로 실행되며 조직이 운영되고 성장함에 따라 새로운 데이터를 감지합니다. 예를 들어 조직의 사용자가 새 프로젝트를 만들고 많은 양의 새 데이터를 업로드하면 검색 서비스에서 새 데이터를 자동으로 검색, 분류, 보고할 수 있습니다.
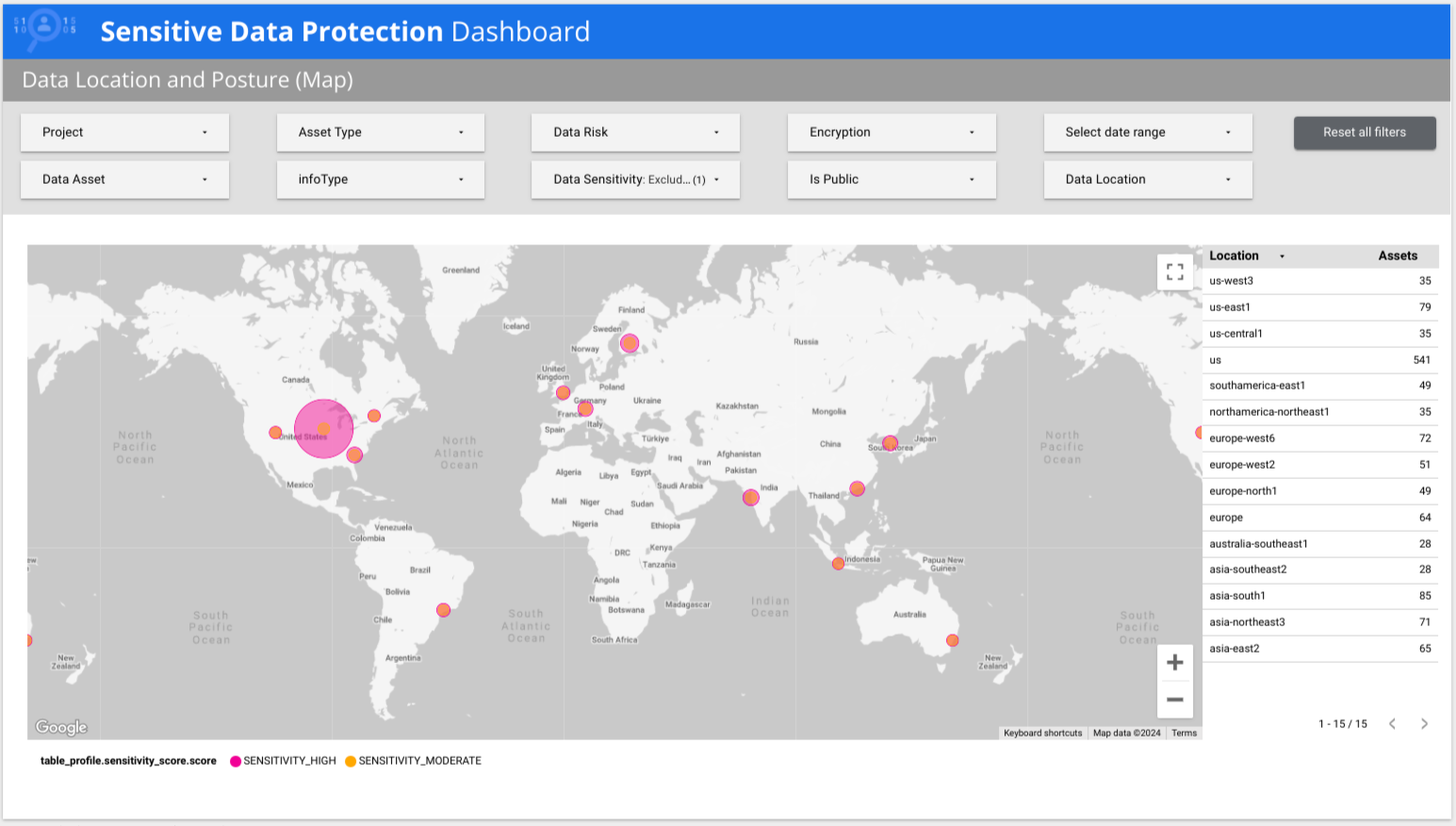
Sensitive Data Protection은 사전 제작된 여러 페이지로 된 Looker 보고서를 제공하여 위험별, infoType별, 위치별 분석을 포함한 데이터에 대한 대략적인 뷰를 제공합니다. 다음 예에서 보고서는 민감도가 낮은 데이터와 민감도가 높은 데이터가 전 세계 여러 국가에 있음을 보여줍니다.
검색 결과에 따라 조치 취하기
데이터 보안 상황을 전반적으로 파악한 후 발견된 문제를 해결할 수 있습니다. 일반적으로 검색 발견 항목은 다음 시나리오 중 하나에 해당합니다.
- 시나리오 1: 민감한 정보가 예상되는 워크로드에서 발견되었으며 적절하게 보호되고 있습니다.
- 시나리오 2: 민감한 정보가 예상치 못한 워크로드에서 발견되었거나 적절한 제어가 없는 곳에서 발견되었습니다.
- 시나리오 3: 민감한 정보가 발견되었지만 추가 조사가 필요합니다.
시나리오 1: 민감한 정보가 발견되었으며 적절하게 보호되고 있습니다.
이 시나리오에서는 특별한 조치가 필요하지 않지만 감사 보고서 및 보안 분석 워크플로에 데이터 프로필을 포함하고 데이터를 위험에 빠뜨릴 수 있는 변경사항을 계속 모니터링해야 합니다.
다음 권장사항을 참고하세요.
보안 상태를 모니터링하고 사이버 위협을 조사하는 도구에 데이터 프로필을 게시합니다. 데이터 프로필을 사용하면 민감한 정보를 위험에 빠뜨릴 수 있는 보안 위협 또는 취약점의 심각도를 파악할 수 있습니다. 다음으로 데이터 프로필을 자동으로 내보낼 수 있습니다.
데이터 프로필을 Dataplex 범용 카탈로그 또는 인벤토리 시스템에 게시하여 다른 적절한 비즈니스 메타데이터와 함께 데이터 프로필 측정항목을 추적합니다. 데이터 프로필을 Dataplex 범용 카탈로그로 자동 내보내기에 관한 자세한 내용은 데이터 프로필의 통계를 기반으로 Dataplex 범용 카탈로그 관점 추가를 참고하세요.
시나리오 2: 민감한 정보가 발견되었으며 적절하게 보호되지 않음
탐색에서 액세스 제어로 적절하게 보호되지 않는 리소스에서 민감한 데이터를 발견한 경우 이 섹션에 설명된 권장사항을 고려하세요.
데이터에 적합한 제어 및 데이터 보안 상황을 설정한 후 데이터가 위험에 처할 수 있는 변경사항을 모니터링합니다. 시나리오 1의 권장사항을 참고하세요.
일반 권장사항
다음 작업을 수행하는 것이 좋습니다.
익명화된 데이터 사본을 만들어 민감한 열을 마스킹하거나 토큰화하여 데이터 분석가와 엔지니어가 개인 식별 정보(PII)와 같은 민감한 원시 식별자를 노출하지 않고 데이터를 계속 사용할 수 있도록 합니다.
Cloud Storage 데이터의 경우 민감한 정보 보호의 기본 제공 기능을 사용하여 익명화된 사본을 만들 수 있습니다.
데이터가 필요하지 않으면 삭제하는 것이 좋습니다.
BigQuery 데이터 보호 권장사항
- IAM을 사용하여 테이블 수준 권한 조정
BigQuery 정책 태그를 사용하여 세분화된 열 수준 액세스 제어를 설정하여 민감하고 위험도가 높은 열에 대한 액세스를 제한합니다. 이 기능을 사용하면 테이블의 나머지 부분에 대한 액세스를 허용하면서 이러한 열을 보호할 수 있습니다.
정책 태그를 사용하여 자동 데이터 마스킹을 사용 설정할 수도 있습니다. 이렇게 하면 사용자에게 부분적으로 난독화된 데이터가 제공될 수 있습니다.
BigQuery의 행 수준 보안 기능을 사용하여 사용자 또는 그룹이 허용된 목록에 있는지 여부에 따라 특정 데이터 행을 숨기거나 표시합니다.
Cloud Storage 데이터 보호 권장사항
시나리오 3: 민감한 정보가 발견되었지만 추가 조사가 필요함
경우에 따라 추가 조사가 필요한 결과가 표시될 수 있습니다. 예를 들어 데이터 프로필은 민감한 정보에 대한 증거가 있는 높은 자유 텍스트 점수를 갖도록 지정할 수 있습니다. 자유 텍스트 점수가 높으면 데이터에 예측 가능한 구조가 없고 민감한 정보의 간헐적인 인스턴스가 포함될 수 있음을 나타냅니다. 특정 행에 이름, 연락처 정보, 정부 발급 식별자와 같은 PII가 포함된 메모 열일 수 있습니다. 이 경우 테이블에 추가 액세스 제어를 설정하고 시나리오 2에 설명된 다른 해결 방법을 수행하는 것이 좋습니다. 또한 위험의 정도를 파악하기 위해 심층적인 타겟 검사를 실행하는 것이 좋습니다.
검사 서비스를 사용하면 개별 BigQuery 테이블 또는 Cloud Storage 버킷과 같은 단일 리소스를 철저히 스캔할 수 있습니다. 검사 서비스에서 직접 지원하지 않는 데이터 소스의 경우 데이터를 Cloud Storage 버킷 또는 BigQuery 테이블로 내보내고 해당 리소스에서 검사 작업을 실행할 수 있습니다. 예를 들어 Cloud SQL 데이터베이스에서 검사해야 하는 데이터가 있는 경우 Cloud Storage의 CSV 또는 AVRO 파일로 데이터를 내보내고 검사 작업을 실행할 수 있습니다.
검사 작업은 테이블 셀 내 문장 중간에 있는 신용카드 번호와 같은 민감한 정보의 개별 인스턴스를 찾습니다. 이러한 세부정보를 통해 비정형 열이나 데이터 객체(텍스트 파일, PDF, 이미지, 기타 서식 있는 문서 형식 포함)에 어떤 종류의 데이터가 있는지 파악할 수 있습니다. 그런 다음 시나리오 2에 설명된 권장사항을 통해 발견 항목을 해결할 수 있습니다.
시나리오 2에서 권장하는 단계 외에도 민감한 정보가 백엔드 데이터 스토리지에 입력되지 않도록 조치를 취하는 것이 좋습니다.
Cloud Data Loss Prevention API의 content 메서드는 이동 중인 데이터 검사 및 마스킹을 위해 모든 워크로드 또는 애플리케이션의 데이터를 허용할 수 있습니다. 예를 들어 애플리케이션은 다음을 실행할 수 있습니다.
- 사용자가 제공한 댓글을 수락합니다.
content.deidentify를 실행하여 해당 문자열에서 민감한 정보를 익명화합니다.- 식별자가 삭제된 문자열을 원본 문자열 대신 백엔드 저장소에 저장합니다.
권장사항 요약
다음 표에서는 이 문서에 설명된 권장사항을 요약해서 보여줍니다.
| 도전과제 | 작업 |
|---|---|
| 조직에서 어떤 종류의 데이터를 저장하는지 알고 싶습니다. | 조직, 폴더 또는 프로젝트 수준에서 검색을 실행합니다. |
| 이미 보호된 리소스에서 민감한 정보를 발견했습니다. | 검색을 실행하고 프로필을 Security Command Center, Google SecOps, Dataplex 범용 카탈로그로 자동으로 내보내서 해당 리소스를 지속적으로 모니터링합니다. |
| 보호되지 않는 리소스에서 민감한 정보가 발견되었습니다. | 데이터를 보는 사용자에 따라 데이터를 숨기거나 표시합니다. IAM, 열 수준 보안 또는 행 수준 보안을 사용합니다. Sensitive Data Protection의 익명화 도구를 사용하여 민감한 요소를 변환하거나 삭제할 수도 있습니다. |
| 민감한 정보를 발견했으며 데이터 위험의 정도를 파악하기 위해 추가 조사가 필요합니다. | 리소스에서 검사 작업을 실행합니다. 거의 실시간으로 데이터를 처리하는 DLP API의 동기식 content 메서드를 사용하여 민감한 정보가 백엔드 스토리지에 들어오는 것을 사전에 방지할 수 있습니다. |