Cette page présente des stratégies recommandées pour identifier et corriger les risques liés aux données dans votre organisation.
La protection de vos données commence par la compréhension des données que vous traitez, de l'emplacement des données sensibles, ainsi que de la façon dont ces données sont sécurisées et utilisées. Lorsque vous disposez d'une vue complète de vos données et de votre niveau de sécurité, vous pouvez prendre les mesures appropriées pour les protéger et surveiller en permanence la conformité et les risques.
Dans cette page, nous partons du principe que vous connaissez les services de découverte et d'inspection, ainsi que leurs différences.
Activer la découverte des données sensibles
Pour déterminer où se trouvent les données sensibles dans votre entreprise, configurez la découverte au niveau de l'organisation, du dossier ou du projet. Ce service génère des profils de données contenant des métriques et des insights sur vos données, y compris leurs niveaux de sensibilité et de risque.
En tant que service, la découverte sert de source de vérité sur vos assets de données et peut générer automatiquement des métriques pour les rapports d'audit. De plus, la découverte peut se connecter à d'autres services Google Cloud tels que Security Command Center, Google Security Operations et Dataplex Universal Catalog pour enrichir les opérations de sécurité et la gestion des données.
Le service de découverte s'exécute en continu et détecte les nouvelles données à mesure que votre organisation fonctionne et se développe. Par exemple, si un membre de votre organisation crée un projet et importe une grande quantité de nouvelles données, le service de découverte peut découvrir, classer et signaler automatiquement les nouvelles données.
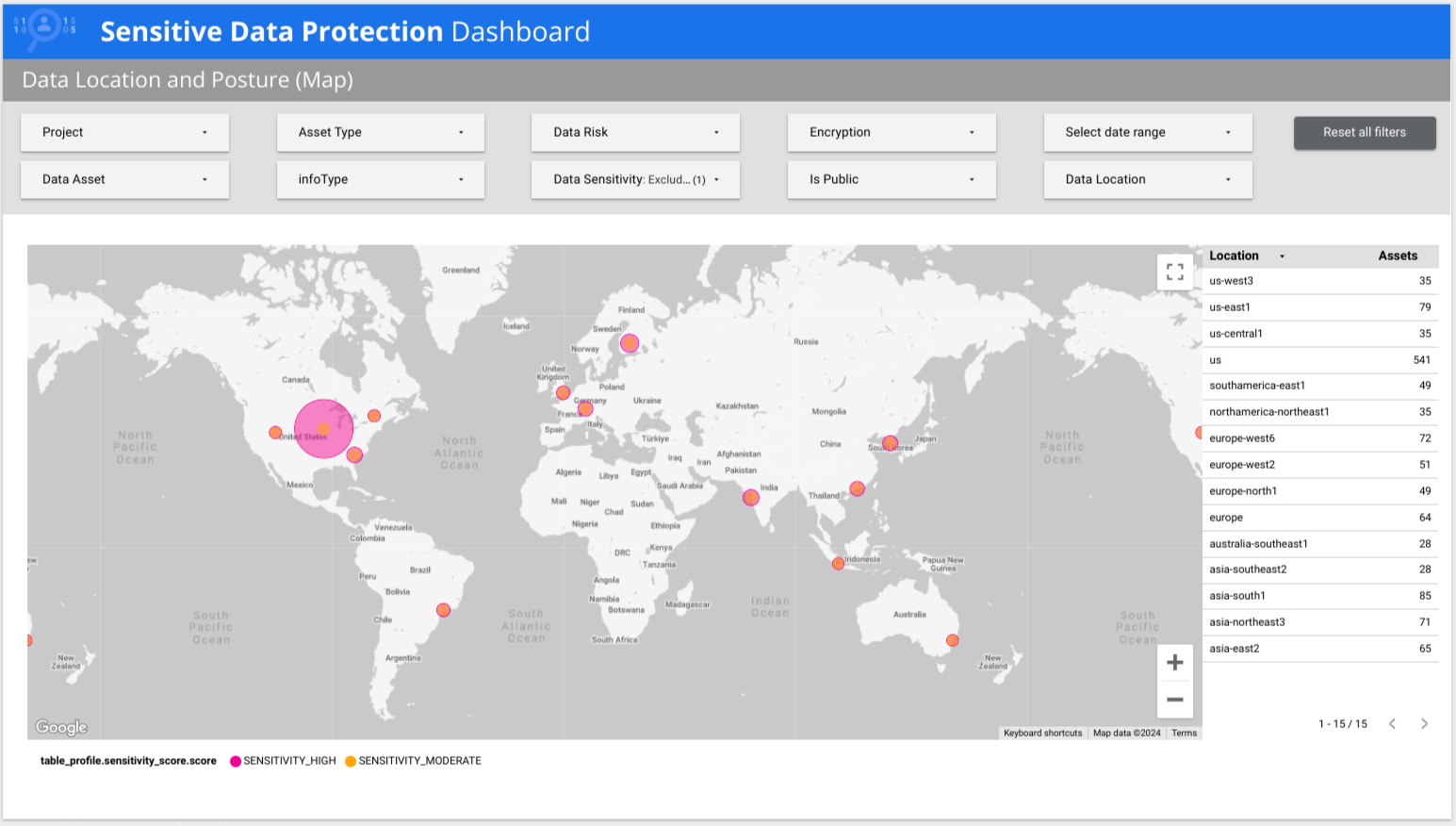
La protection des données sensibles fournit un rapport Looker multipage prédéfini qui vous offre une vue d'ensemble de vos données, y compris des répartitions par risque, par infoType et par emplacement. Dans l'exemple suivant, le rapport indique que des données à sensibilité faible et élevée sont présentes dans plusieurs pays du monde.
Intervenir en fonction des résultats de la découverte
Une fois que vous avez une vue d'ensemble de votre niveau de sécurité des données, vous pouvez résoudre les problèmes détectés. En général, les résultats de la découverte relèvent de l'un des scénarios suivants :
- Scénario 1 : Des données sensibles ont été trouvées dans une charge de travail où elles sont attendues et où elles sont correctement protégées.
- Scénario 2 : Des données sensibles ont été trouvées dans une charge de travail où elles n'étaient pas attendues ou où des contrôles appropriés ne sont pas en place.
- Scénario 3 : Des données sensibles ont été détectées, mais nécessitent une enquête plus approfondie.
Scénario 1 : Des données sensibles ont été détectées et sont correctement protégées
Bien que ce scénario ne nécessite aucune action spécifique, vous devez inclure les profils de données dans vos rapports d'audit et vos workflows d'analyse de sécurité, et continuer à surveiller les modifications qui peuvent mettre vos données en danger.
Nous vous recommandons d'adopter les bonnes pratiques suivantes :
Publiez les profils de données dans des outils permettant de surveiller votre stratégie de sécurité et d'examiner les cybermenaces. Les profils de données peuvent vous aider à déterminer la gravité d'une menace ou d'une faille de sécurité qui pourrait mettre en danger vos données sensibles. Vous pouvez exporter automatiquement des profils de données vers les destinations suivantes :
Publiez les profils de données dans Dataplex Universal Catalog ou dans un système d'inventaire pour suivre les métriques des profils de données ainsi que toute autre métadonnée métier appropriée. Pour savoir comment exporter automatiquement des profils de données vers Dataplex Universal Catalog, consultez Ajouter des aspects Dataplex Universal Catalog en fonction des insights issus des profils de données.
Scénario 2 : Des données sensibles ont été détectées et ne sont pas correctement protégées
Si la découverte trouve des données sensibles dans une ressource qui n'est pas correctement sécurisée par des contrôles d'accès, tenez compte des recommandations décrites dans cette section.
Une fois que vous avez établi les contrôles et la stratégie de sécurité des données appropriés pour vos données, surveillez les éventuelles modifications qui pourraient les mettre en danger. Consultez les recommandations du scénario 1.
Recommandations générales
Voici quelques conseils :
Créez une copie anonymisée de vos données pour masquer ou tokeniser les colonnes sensibles. Vos analystes et ingénieurs de données pourront ainsi continuer à travailler avec vos données sans révéler d'identifiants bruts et sensibles, comme les informations permettant d'identifier personnellement l'utilisateur.
Pour les données Cloud Storage, vous pouvez utiliser une fonctionnalité intégrée à la protection des données sensibles pour créer des copies anonymisées.
Si vous n'avez pas besoin des données, envisagez de les supprimer.
Recommandations pour protéger les données BigQuery
- Ajustez les autorisations au niveau des tables à l'aide d'IAM.
Définissez des contrôles d'accès précis au niveau des colonnes à l'aide des tags avec stratégie BigQuery pour restreindre l'accès aux colonnes sensibles et à haut risque. Cette fonctionnalité vous permet de protéger ces colonnes tout en autorisant l'accès au reste du tableau.
Vous pouvez également utiliser des tags avec stratégie pour activer le masquage des données automatique, qui peut fournir aux utilisateurs des données partiellement masquées.
Utilisez la fonctionnalité de sécurité au niveau des lignes de BigQuery pour masquer ou afficher certaines lignes de données, selon qu'un utilisateur ou un groupe figure dans une liste autorisée.
Anonymisez les données BigQuery au moment de la requête à l'aide de fonctions distantes (UDF).
Recommandations pour protéger les données Cloud Storage
Scénario 3 : Des données sensibles ont été détectées, mais nécessitent une enquête plus approfondie
Dans certains cas, vous pouvez obtenir des résultats qui nécessitent une analyse plus approfondie. Par exemple, un profil de données peut indiquer qu'une colonne présente un score de texte libre élevé avec des preuves de données sensibles. Un score de texte libre élevé indique que les données n'ont pas de structure prévisible et peuvent contenir des instances intermittentes de données sensibles. Il peut s'agir d'une colonne de notes où certaines lignes contiennent des informations permettant d'identifier personnellement l'utilisateur, comme des noms, des coordonnées ou des identifiants émis par le gouvernement. Dans ce cas, nous vous recommandons de définir des contrôles d'accès supplémentaires sur la table et d'effectuer les autres corrections décrites dans le scénario 2. De plus, nous vous recommandons d'effectuer une inspection plus approfondie et ciblée pour identifier l'étendue du risque.
Le service d'inspection vous permet d'analyser en profondeur une seule ressource, comme une table BigQuery ou un bucket Cloud Storage. Pour les sources de données qui ne sont pas directement compatibles avec le service d'inspection, vous pouvez exporter les données dans un bucket Cloud Storage ou une table BigQuery, puis exécuter une tâche d'inspection sur cette ressource. Par exemple, si vous avez des données que vous devez inspecter dans une base de données Cloud SQL, vous pouvez les exporter vers un fichier CSV ou AVRO dans Cloud Storage et exécuter un job d'inspection.
Un job d'inspection localise les instances individuelles de données sensibles, comme un numéro de carte de crédit au milieu d'une phrase dans une cellule de tableau. Ce niveau de détail peut vous aider à comprendre le type de données présentes dans les colonnes non structurées ou dans les objets de données, y compris les fichiers texte, les PDF, les images et d'autres formats de documents enrichis. Vous pouvez ensuite corriger les problèmes détectés en suivant l'une des recommandations décrites dans le scénario 2.
En plus des étapes recommandées dans le scénario 2, pensez à prendre des mesures pour empêcher les informations sensibles d'entrer dans votre stockage de données backend.
Les méthodes content de l'API Cloud Data Loss Prevention peuvent accepter des données provenant de n'importe quelle charge de travail ou application pour l'inspection et le masquage des données en transit. Par exemple, votre application peut effectuer les opérations suivantes :
- Accepter un commentaire fourni par un utilisateur.
- Exécutez
content.deidentifypour anonymiser les données sensibles de cette chaîne. - Enregistrez la chaîne anonymisée dans votre stockage backend au lieu de la chaîne d'origine.
Récapitulatif des bonnes pratiques
Le tableau suivant récapitule les bonnes pratiques recommandées dans ce document :
| Défi | Action |
|---|---|
| Vous souhaitez connaître le type de données stockées par votre organisation. | Exécutez la découverte au niveau de l'organisation, du dossier ou du projet. |
| Vous avez trouvé des données sensibles dans une ressource déjà protégée. | Surveillez en continu cette ressource en exécutant la découverte et en exportant automatiquement les profils vers Security Command Center, Google SecOps et Dataplex Universal Catalog. |
| Vous avez trouvé des données sensibles dans une ressource non protégée. | Masquez ou affichez les données en fonction de la personne qui les consulte. Utilisez IAM, la sécurité au niveau des colonnes ou la sécurité au niveau des lignes. Vous pouvez également utiliser les outils d'anonymisation de Sensitive Data Protection pour transformer ou supprimer les éléments sensibles. |
| Vous avez trouvé des données sensibles et vous devez approfondir vos recherches pour comprendre l'étendue du risque lié à vos données. | Exécutez une tâche d'inspection sur la ressource. Vous pouvez également empêcher de manière proactive les données sensibles d'entrer dans votre stockage backend en utilisant les méthodes content synchrones de l'API DLP, qui traitent les données en temps quasi réel. |