Sensitive Data Protection vous aide à identifier, comprendre et gérer les données sensibles qui existent dans votre infrastructure. Une fois que vous avez analysé votre contenu à l'aide de la protection des données sensibles et trouvé les données sensibles, vous disposez de plusieurs options pour traiter ces renseignements sur vos données. Cet article vous explique comment exploiter la puissance des autres fonctionnalités Google Cloud telles que BigQuery, Cloud SQL et Looker Studio pour :
- stocker les résultats des analyses effectuées avec la protection des données sensibles directement dans BigQuery ;
- générer des rapports sur l'emplacement des données sensibles au sein de votre infrastructure ;
- exécuter des analyses SQL approfondies afin de comprendre où les données sensibles sont stockées et d'identifier leur(s) type(s) ;
- automatiser les alertes ou les actions à déclencher en vous basant sur un jeu unique ou une combinaison de jeux de résultats.
Cette section contient également un exemple complet qui explique comment associer la protection des données sensibles à d'autres fonctionnalités Google Cloud pour accomplir toutes ces tâches.
Analyser un bucket de stockage
Tout d'abord, lancez une analyse sur vos données. Vous trouverez ci-dessous des informations de base sur l'analyse des dépôts de stockage à l'aide de Sensitive Data Protection. Pour obtenir des instructions complètes sur l'analyse des dépôts de stockage, y compris l'utilisation des bibliothèques clientes, consultez la page Inspecter l'espace de stockage et les bases de données pour identifier les données sensibles.
Pour exécuter une opération d'analyse sur un dépôt de stockageGoogle Cloud , assemblez un objet JSON comprenant les objets de configuration suivants :
InspectJobConfig: configure la tâche d'analyse de la protection des données sensibles et comprend les éléments suivants :StorageConfig: Dépôt de stockage à analyser.InspectConfig: Éléments à analyser et méthode à employer. Vous pouvez également vous servir d'un modèle d'inspection pour définir la configuration de l'inspection.Action: Tâche(s) à exécuter une fois l'opération terminée. Cela peut inclure l'enregistrement des résultats dans une table BigQuery ou la publication d'une notification dans Pub/Sub.
Dans cet exemple, vous analysez un bucket Cloud Storage pour identifier les noms de personnes, les numéros de téléphone, les numéros de sécurité sociale américains et les adresses e-mail. Vous envoyez ensuite les résultats à une table BigQuery dédiée au stockage du résultat Sensitive Data Protection. Vous pouvez enregistrer l'objet JSON suivant dans un fichier ou l'envoyer directement à la méthode create de la ressource Protection des données sensibles DlpJob.
Entrée JSON :
POST https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs
{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"includeQuote":true
},
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
En spécifiant deux astérisques (**) après l'adresse du bucket Cloud Storage (gs://[BUCKET_NAME]/**), vous demandez à la tâche d'analyse d'effectuer une analyse récursive. Utilisez un seul astérisque (*) si vous souhaitez analyser seulement le niveau du répertoire spécifié sans aller plus loin.
Le résultat sera enregistré dans la table spécifiée, dans l'ensemble de données et sous le projet indiqués. Les tâches suivantes qui spécifient l'ID de table indiqué ajoutent les résultats à la même table. Vous pouvez également ne pas indiquer de valeur pour la clé "tableId" si vous souhaitez que Sensitive Data Protection crée une table chaque fois que l'analyse est exécutée.
Après avoir envoyé cet objet JSON dans une requête à la méthode projects.dlpJobs.create via l'URL spécifiée, vous obtenez la réponse suivante :
Sortie JSON :
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"PENDING",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
},
"createTime":"2018-11-19T21:09:07.926Z"
}
Une fois la tâche achevée, les résultats sont enregistrés dans la table BigQuery indiquée.
Pour obtenir l'état de la tâche, appelez la méthode projects.dlpJobs.get ou envoyez une requête GET à l'URL suivante, en remplaçant [PROJECT_ID] par l'ID de votre projet et [JOB_ID] par l'identifiant de la tâche. Celui-ci vous est fourni dans la réponse de l'API Cloud Data Loss Prevention à la requête de création de tâche (l'identifiant est précédé d'un "i-") :
GET https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs/[JOB_ID]
Pour la tâche que vous venez de créer, cette requête renvoie le code JSON ci-dessous. Notez que les résultats de l'analyse sont renvoyés après les détails de l'inspection. Si l'analyse n'est pas encore terminée, sa clé "state" indique "RUNNING".
Sortie JSON :
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
},
"result":{
"processedBytes":"536734051",
"totalEstimatedBytes":"536734051",
"infoTypeStats":[
{
"infoType":{
"name":"PERSON_NAME"
},
"count":"269679"
},
{
"infoType":{
"name":"EMAIL_ADDRESS"
},
"count":"256"
},
{
"infoType":{
"name":"PHONE_NUMBER"
},
"count":"7"
}
]
}
},
"createTime":"2018-11-19T21:09:07.926Z",
"startTime":"2018-11-19T21:10:20.660Z",
"endTime":"2018-11-19T22:07:39.725Z"
}
Exécuter des analyses dans BigQuery
Maintenant que vous avez créé une table BigQuery avec les résultats de l'analyse effectuée via Sensitive Data Protection, l'étape suivante consiste à exécuter des analyses sur la table.
Sur le côté gauche de la console Google Cloud , sous "Big Data", cliquez sur BigQuery. Ouvrez votre projet et votre ensemble de données, puis localisez la table que vous venez de créer.
Vous pouvez exécuter des requêtes SQL sur cette table pour en savoir plus sur ce que Sensitive Data Protection a trouvé dans votre bucket de données. Exécutez, par exemple, la requête suivante pour obtenir le nombre total de résultats d'analyse pour chaque infoType. Veillez à remplacer les espaces réservés par les valeurs réelles adéquates :
SELECT
info_type.name,
COUNT(*) AS iCount
FROM
`[PROJECT_ID].[DATASET_ID].[TABLE_ID]`
GROUP BY
info_type.name
Le tableau récapitulatif des résultats de cette requête pour le bucket concerné peut ressembler à ceci :
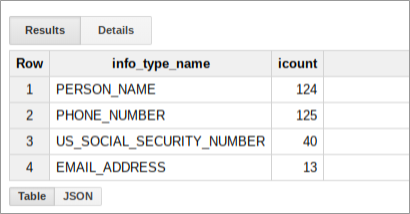
Créer un rapport dans Looker Studio
Looker Studio vous permet de créer des rapports personnalisés à partir des tables BigQuery. Dans cette section, vous allez créer dans Looker Studio un rapport sous forme de tableau simple, basé sur les résultats de la protection des données sensibles stockés dans BigQuery.
- Ouvrez Looker Studio, puis commencez un nouveau rapport.
- Cliquez sur Créer une source de données.
- Dans la liste des connecteurs, cliquez sur BigQuery. Si nécessaire, autorisez Looker Studio à se connecter à vos projets BigQuery en cliquant sur Autoriser.
- Maintenant, choisissez la table sur laquelle effectuer la recherche, puis cliquez sur Mes projets ou Projets partagés, en fonction de l'emplacement de votre projet. Trouvez votre projet, votre ensemble de données et votre table dans les listes présentées sur la page.
- Cliquez sur Connecter pour lancer le rapport.
- Cliquez sur Ajouter au rapport.
Vous allez maintenant créer un tableau qui affiche la fréquence de chaque infoType. Sélectionnez le champ info_type.name comme dimension. Le tableau que vous obtiendrez ressemblera à ceci :
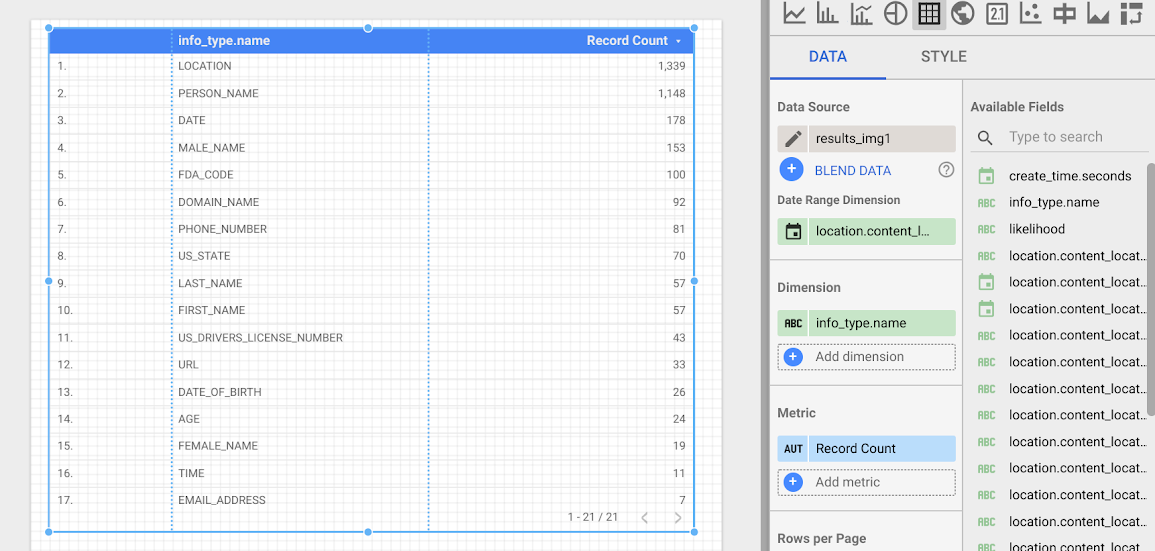
Étapes suivantes
Ceci n'est qu'un exemple de ce que vous pouvez visualiser à l'aide de Looker Studio et des résultats de Sensitive Data Protection. Vous pouvez ajouter d'autres éléments graphiques ainsi que des filtres d'exploration pour créer des tableaux de bord et des rapports. Pour en savoir plus sur les éléments disponibles dans Looker Studio, consultez la présentation des produits Looker Studio.